




背景
1,接到客户反馈,其中一条insert语句造成了大量的gc buffer busy wait ,buffer busy wait和enq: TX - index contention等待事件,并且索引大小增长很厉害,希望我们协助分析。
2,另外,客户有两个厂区,这里分别用厂区A和厂区B表示,客户反馈厂区A的insert 比厂区B 频繁好几倍,并且业务逻辑也一样,反而厂区A正常,而厂区B出现上面的一系列等待事件。
其实根据客户反馈,结合awr,很容易就分析出来了,索引5-5分裂严重,索引臃肿,但是为什么厂区A的业务更频繁,反而却没有问题了?接下来就一步一步为大家揭秘,整个分析过程也是经过很久,多次调整,因为客户7X24系统,需要时间窗口做调整。
分析
第一次接到客户反馈
第一次接到反馈,根据等待事件,很明显就是索引分裂导致,建议客户对比一下两个厂区索引的相关属性,序列的相关属性以及业务逻辑,索引是否单调递增等等,但是客户反馈是一样的,一下子就陷入了谜团,一模一样的环境,为什么差别会这么大呢?
既然想不出其中的问题,就对索引先做一些简单分析吧:
首先对比两个厂区索引blocks,如图:
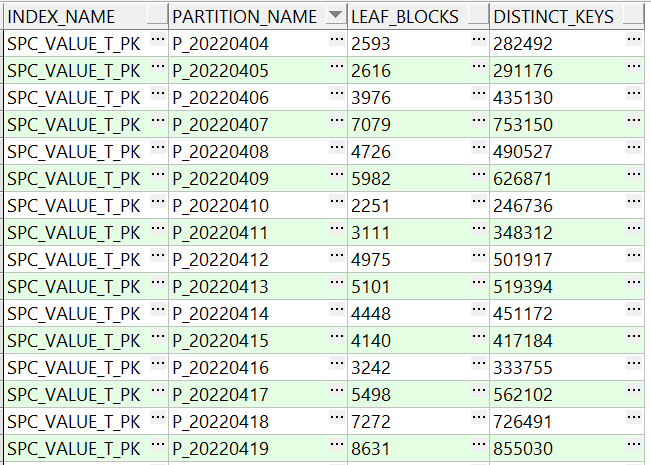
厂区B:
厂区A:
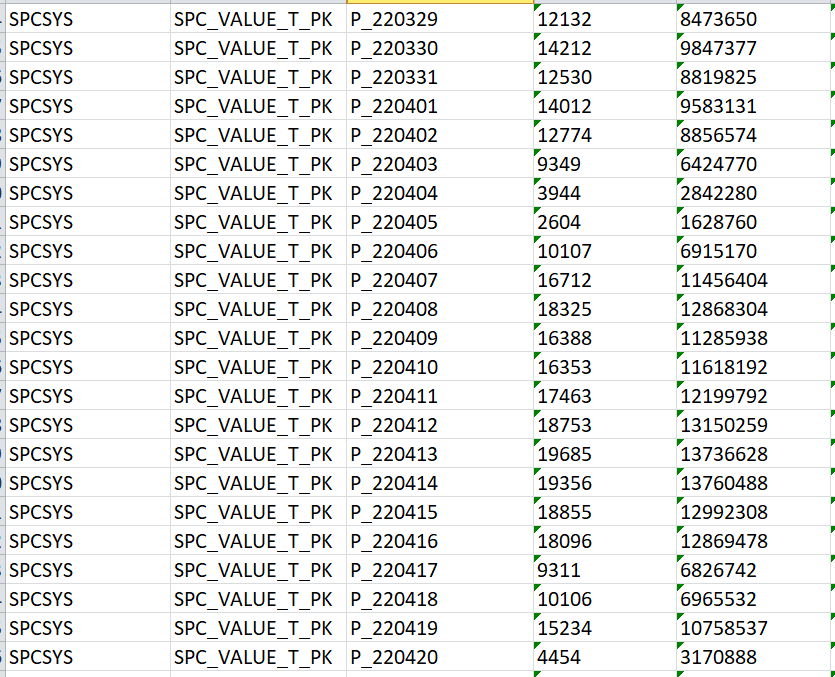
可以看到厂区A的几百万键值才占用几千blocks,空间使用更充分,占用block少,厂区B几十万键值就占用了好几千的block,非常的臃肿,继续对索引大小进行了一个简单估算,主键是由时间戳+序列组成,宽度为30。
注:一个索引条目包括索引条目头2个字节,键值列长度1字节,列宽avg_row_len,rowid长度1字节,rowid 6字节,所以每个索引条目大概占用avg_row_len+10宽度。同时一个块的块头占用192字节,默认10%的pctfree,所以计算方法如下:
每个block可以存放的索引条目约为 (8192-192) * 90% / (avg_row_len+10),估算结果与上图厂区B的实际占用block严重不匹配。
由于客户反馈两个厂区的环境,索引,业务逻辑都是一样,并且也统计了DBA_TAB_MODIFICATIONS,发现DML并不多,尤其delete,几乎没有,所以这里我就先建议客户重建了一下索引,后续再继续观察一下,其实我这里已经猜到重建索引并不能解决,后面问题应该会重现。
第二次接到客户反馈
果然不出所料,51岁修期间客户重建了索引,51节后上班第一天,就接到客户反馈,说重建完初期上面的现象有所缓解,索引只有700M大小,但是短短三天之后,等待事件又开始继续加剧,索引大小增长了好几倍,需要继续分析。
其实经过上一次分析,到索引重建,到现象重现,我已经对业务反馈的一些“事实”开始持怀疑态度了,所以这次想着开始从这个方向去分析,首先首对比两个厂区的AWR:
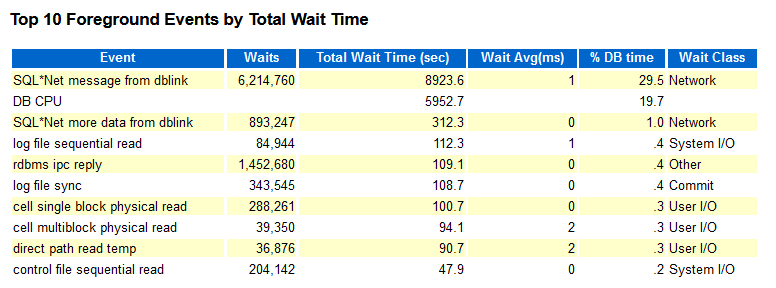
厂区A:


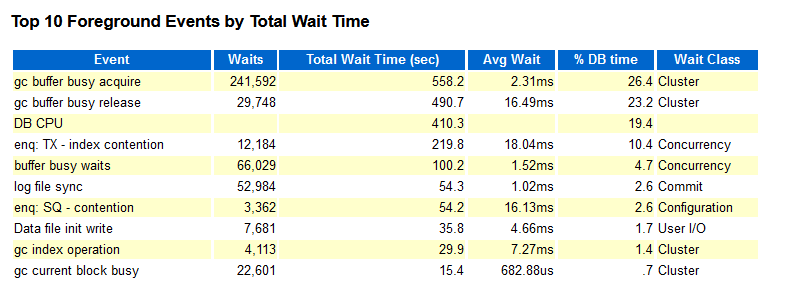
厂区B:


可以看到:
厂区A一小时内insert接近32W次,索引分裂接近3.7W次,其中5-5分裂差不多1.3W次,而top 10并没有出现相关等待事件。
厂区B一小时内insert才5.3W次,索引分裂才2000多次,几乎全是5-5分裂,而TX-index及busy相关等待是事件却很严重。
根据客户的反馈,应用的业务逻辑是一样的,那问题究竟出现在哪里呢????
其实大家仔细看上面的awr,可以发现厂区A的SQL Module是DBMS_SCHEDULER,而厂区B的是JDBC Thin Client,到这里有想法了吗?
看到这里我第一反应,觉得业务反馈的“事实”不可信,让客户重新和业务确认一下,客户确认完之后反馈,确实有不一样,厂区A是通过定时job调用,批量insert,在一个session执行,而厂区B是单条insert语句单次执行,连接的是scanip,这就好解释了:
厂区B通过insert语句单次执行,那session会几乎平均到两个节点上,这样两个节点频繁的insert,势必会导致gc,同时因为seq有缓存,可能节点1才insert到1000,而节点2已经insert到2000,这样势必就会导致索引的5-5分裂。这里适当扩充一下,索引的5-5分裂在RAC环境下存在的一个副作用:
举个例子:两节点的rac,序列缓存是2000,节点1 insert第一条的时候取值是1,节点2 insert 第一条的时候取值是2001,两个节点取到的序列值跨度较大,那业务上先后insert的两条数据,在索引中很可能就不在一个块上,序列缓存值越大,可能性越大,而索引是有序的,这样节点1插入新值得时候,必然会在之前insert的两条数据序列值之间,就必然会存在5-5分裂,并且这种情况下5-5分裂,序列缓存越大,5-5分裂后的空闲空间就更难用到,从而造成空间浪费更严重。
其实分析到这里,我就已经反馈给客户,就是因为insert逻辑不一样,厂区A 一次批量insert都在一个节点,而厂区B每次insert都是单条SQL语句,均衡分布于两个节点,从而造成了索引5-5分裂在rac环境下的副作用。
分析到这里,你以为破案了吗???继续往下看:
第三次接到客户反馈
一个礼拜后,又接到了客户反馈,客户说他们周末的时候直接关闭了集群的其中一个节点,让业务单节点运行,gc相关等待是没了,但是buffer busy wait和enq:TX - index contention却一直还在,只能继续找其它突破口继续分析了。
回顾一下,业务反馈索引是单调递增的,数据库也是单节点运行的,分析了AWR,也是索引5-5分裂,这就奇怪了,没有了两节点序列缓存干扰,单调递增不应该是9-1分裂吗???
分析到这里,我又对业务反馈的一些“事实”产生了怀疑,索引真的是单调递增吗?
于是我对索引列的实际数据进行了排查,是的,没猜错,确实发现了新猫腻,如图:
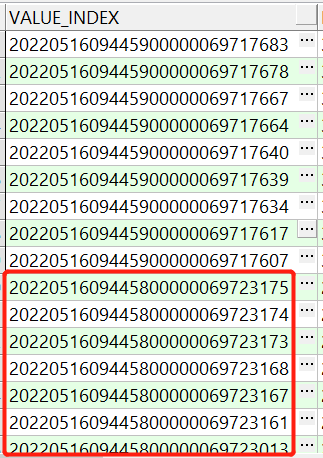
看到没有,时间戳小的,后面拼接的序列反而更大,这就奇怪了,难道应用程序里面的拼接逻辑有问题???并且存在时间戳小的数据反而后插入的情况???到这里我又让客户去找业务确认,确认结果没有令我失望,确实存在上面所说的情况,这样就好解释为什么单节点情况下索引还存在5-5分裂,因为,索引列的插入顺序压根就不是单调递增的。
将分析情况反馈给客户之后,我以为已经彻底破案了,就跑出去抽支烟,冷静冷静,并简单在脑海里作一下回顾,总结,你以为这就结束了吗??? 并没有,回顾总结的时候,我又有了新的疑问:
索引虽然不是单调递增,但是在rac环境下,为什么厂区B会臃肿,空闲空间无法使用??而厂区A不存在这个情况呢???按照上面说的,5-5分裂在RAC环境下的副作用,难道两个厂区的序列cache不一样??
带着我的疑问我又找了客户,趁客户去和业务确认的空档,我对索引做了个treedump,如图:
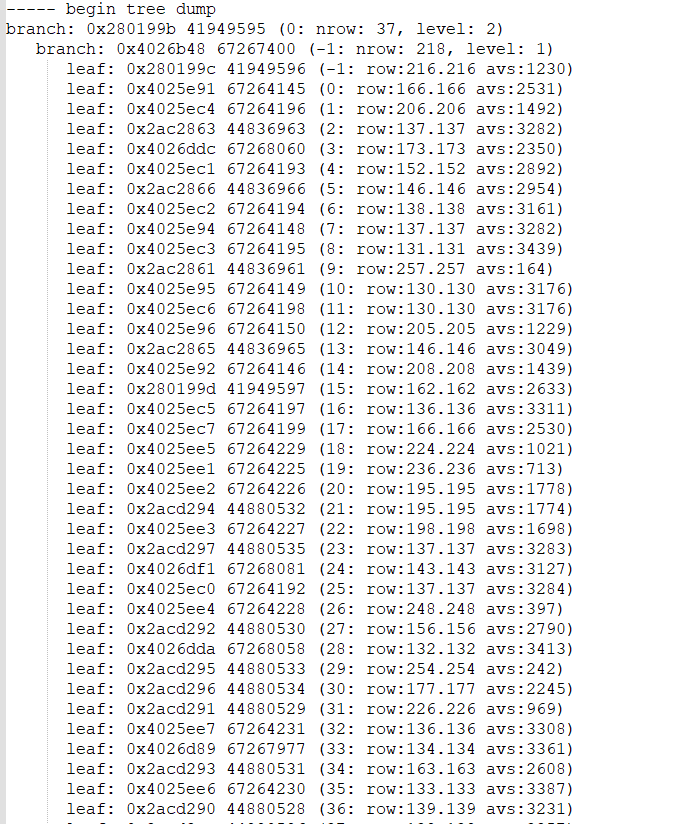
可以发现,每个索引块都有好几千字节的空闲空间未使用,每个block存储索引条目大部分都在100多条左右,按照最初的估算是应该能存下200左右个索引条目的,其实到这里我已经差不多能猜出来,业务反馈的又有不实。
客户确认完之后,果然,还是一如既往的没让我“失望”,第一次业务反馈的序列缓存两个厂区一样的言论,又是不实的,厂区A的seq cache只有20,而厂区B的seq cache有500,而根据之前估算一个block最多只能存储200个左右条目,而seq cache有500,比200大的多,这正好是5-5分裂在RAC环境下副作用比较明显的情况,到此,整个问题彻底分析完成,具体需要调整的内容:
- 修改insert逻辑,将单条insert执行的方式修改为跟厂区A一样的批量执行方式
- 调小整序列缓存(因为批量在同一个节点执行,并不会导致rac节点间sequence争用,所以cache调小是可行的)
- 修改业务逻辑,排除小值后插入,以及小的时间戳和大的sequence拼接的情况
总结
经过上面的多次分析和多次和业务的沟通,问题终于彻底解决,但是其中也走了很多弯路,关键是一开始我对业务反馈的两个厂区的各种情况都一致的言论深信不疑,如下:
- insert 逻辑一样,实际并不一样
- 索引单调递增,实际并不是,存在小值后插入,小时间戳和大sequence拼接的情况
- 两个厂区sequence的cache一样,实际并不一样,一个20,一个500
所以,面对问题,要保持对业务反馈的各种情况持谨慎信任态度,毕竟业务对数据库处理逻辑不是很了解,可能有时候反馈的事情并不准确,多和业务沟通,少走弯路。
