




原文地址:https://dzone.com/articles/from-zookeeper-to-raft-how-virtual-distributed-fil
原文作者:泰勒·克雷恩
Raft 是一种用于状态机复制的算法,用于确保高可用性 (HA) 和容错。这篇博客分享了 Alluxio 如何迁移到一个没有 Zookeeper 的、内置的基于 Raft 的日志系统作为 HA 实现。
介绍
Alluxio 实现了一个虚拟分布式文件系统,允许使用 Hadoop 或 Spark 等计算引擎通过单个接口访问独立的大型数据存储。在 Alluxio 集群中,Alluxio master 负责协调和保持对底层数据存储或文件系统(简称 UFS)的访问一致。master 包含文件系统元数据的全局快照,当客户端想要读取或修改文件时,它首先联系 master。鉴于其在系统中的核心作用,master 必须具有容错性、高可用性、强一致性和快速性。本篇博客将讨论 Alluxio master 从使用Zookeeper 的复杂多组件系统到使用Raft的更简单、更高效的演变。
文件系统的操作可以被认为是在系统上执行的一系列命令(例如,创建/删除/读/写)。在单个线程中一次执行这些命令为我们的文件系统提供了一个顺序规范,该规范易于推理和在其上实现应用程序。虽然这个顺序规范很简单,但 Alluxio 的虚拟分布式文件系统的实际实现由许多同时执行的移动部分组成:协调系统的 master,存储文件数据并充当客户端和 UFS 之间的缓存的 worker 、UFS 本身以及在主设备的指示下访问系统所有其他部分的客户端。又来了,
我们这里要解决的核心问题是如何让 Alluxio master 看起来像是由单个节点运行,一次运行一个操作,以便实现简单且易于其他组件交互,但仍然具有容错性和高可用性。再者,高手必须足够快才能执行数十次?每秒数千次操作和规模以支持数百个元数据?数百万个文件。
期刊和 HA(高可用性)
Alluxio master 的内部状态由几个包含文件系统元数据、块元数据和工作元数据的表组成。文件系统元数据由一个 inode 表组成,该表将每个目录和文件的元数据(其名称、父级等)映射到一个称为 inode id 的唯一标识符,以及一个使用 inode id 将目录映射到其子级的边缘表。每个文件的实际数据被分割成一个或多个位于 Alluxio 工作人员上的块,可以使用将每个文件映射到一组块标识符的块元数据表和将每个工作人员映射到列表的工作人员元数据表来定位这些块。它包含的块。
每个修改此元数据的操作,例如在虚拟文件系统上创建一个新文件,都会输出一个日志条目包含对表格所做的修改。日志条目按照它们在日志中创建的顺序存储,从而满足我们对主节点的顺序规范。从初始状态开始并按顺序重放这些日志条目将导致元数据的相同状态,从而允许主节点在故障后恢复。为确保日志不会变得太大,将定期拍摄元数据的快照。现在如果这个日志存储在一个高度可用和容错的位置,那么我们就有了我们可靠系统的基础。例如,我们可以启动单个节点并为其分配 master 角色。一段时间后,如果我们检测到节点发生故障,则启动一个新节点,它会重播日志,并取代它作为新的主节点。一个可能的问题是启动新节点并重播日志可能需要很长时间,在此期间系统不可用。为了提高系统的可用性,我们可以同时运行多个 master 副本,其中只有一个副本服务于客户端操作(将此 master 称为primary master),而其他只是在创建日志条目时重放它们(将这些 master 称为辅助 master)。现在,当主 master 发生故障时,辅助 master 可以立即接管为新的主 master。
实现我们的初始设计
从这个基本设计来看,还有两个问题需要解决,1:如何保证始终只有一个主master在运行,2:如何保证日志本身是一致的、容错的、高可用的。从 2013 年开始,我们引入了初始实现来解决这两个问题。
第一个由 Zookeeper [1] 解决。Zookeeper 是一个高度可靠的分布式协调服务,提供运行在 ZAB [2] 共识算法上的类似文件系统的接口。Zookeeper 提供了一个领导者选举配方[3],其中多个节点可以加入该配方,并且单个节点将被选为领导者。如果领导者在一段时间内不再响应,则将选择新的领导者。在 Alluxio 中,所有的 master 都是从二级 master 开始的,并加入 Zookeeper 领导者选举配方,当配方选举一个节点作为领导者时,它就可以升入主节点。
为了解决第二个问题并确保日志具有高可用性和容错性,日志条目存储在 UFS 上。当然,应该使用可用且容错的 UFS。最后,期刊必须一致。如前所述,日志条目应该是完全有序的事件日志,满足我们的顺序规范。只要一次运行的主主节点不超过一个,它就可以将日志条目附加到 UFS 中的文件中以满足一致性。但是我们的领导人选举方案不是已经确保了这一点吗?如果我们有完美的故障检测器或同步系统,那么可以,但不幸的是我们都没有。当 Zookeeper 执行leader选举时,它会在选举新的leader之前通知之前的leader它已经失去了它的领导权,but if the previous leader (or the network) is slow, it may still be appending entries to the journal when the new leader is elected. 因此,我们可能同时有多个主 master 附加到日志中。为了减少发生这种情况的机会,互斥协议通过使用特定文件命名方案使用 UFS 的一致性保证运行。
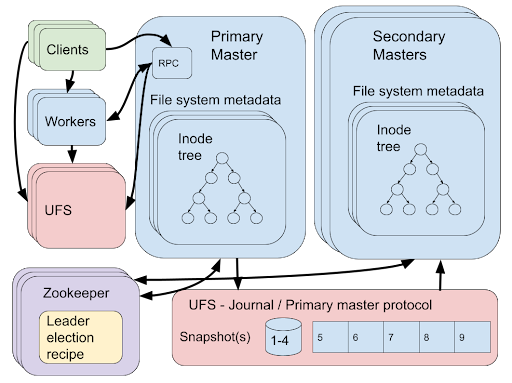
让我们检查一下这个解决方案的一些问题。首先,它依赖于几个外部系统,Zookeeper 和 UFS,与 Alluxio master 一起运行。这使系统的设计和分析变得复杂。每个组件都有不同的故障和可用性模型需要考虑。不同 UFS 之间的选择也使系统复杂化,例如,一个 UFS 可能无法通过频繁的小附加操作提供高性能。此外,每个 UFS 可能有不同的一致性保证,当两个并发的 Primary Master 尝试写入日志时,情况会变得复杂。由于这些原因,HDFS 是此配置的推荐 UFS。
我们现在描述如何使用 Raft 进行更简单、更高效的设计。
基于复制状态机的改进设计
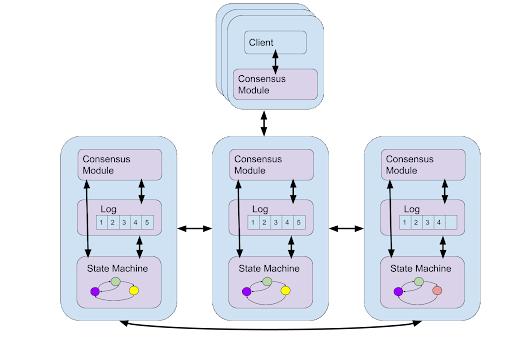
首先,让我们介绍一下(复制的)状态机的概念。状态机将一系列命令作为输入,这些命令修改系统的内部状态并可能产生一些输出。对于我们的例子,状态机必须是确定性的,即给定相同的输入集,系统将产生相同的输出。如果我们将我们的日志视为一个状态机,我们可以将其视为一个简单的日志,该日志具有一个附加命令,该命令将一个日志条目附加到日志的末尾。复制状态机然后是提供高可用性和容错的状态机。它通过在多个节点上复制状态机并运行共识算法来确保相同的命令在每个副本上以相同的顺序运行来实现这一点。Raft [4] 就是这样一种复制状态机协议,用户只需要提供一个确定性状态机作为协议的输入。Raft 的一个重要特性是它确保了线性化的一致性条件[5]。考虑到客户端在复制状态机上执行的每个命令都有一个调用和响应。线性化确保所有客户端都观察到一个操作是在调用和响应之间的某个时刻发生的。这个瞬间被称为操作的线性化点。所有操作的线性化点为我们提供了遵循正在实现的状态机的顺序规范的操作的总顺序。因此,即使我们的状态机被复制,对于客户端来说,它似乎是在实时按顺序执行操作。
使用 Raft 实现日志
现在我们可以简单地将日志条目的日志作为状态机提供给 Raft 复制,但我们可以进一步简化系统。回想一下,将状态表示为日志条目的原因是为了允许主服务器通过重放日志条目来恢复到最近的状态。由于 Raft 负责容错,我们可以对代表 master 状态的状态机使用更高级别的抽象。这只是包含 Alluxio 文件系统元数据状态的表的集合。主机将执行其正常操作,并向状态机提供代表对表的修改的命令,这些命令显然是确定性的。Raft 在内部处理日志记录、快照和在发生故障时的状态恢复。
这些表是使用 RocksDB [6] 实现的。RocksDB 是一个使用日志结构的合并树 [7] 实现的磁盘键值存储,它允许有效的更新。通过使用 RocksDB,文件系统元数据的大小可以增长到大于主节点上可用的内存。Alluxio 还在 RocksDB 之上实现了一个内存缓存,以确保读取键的速度很快。
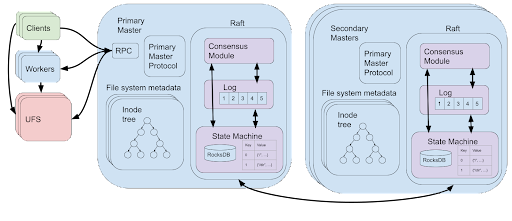
像以前一样,单个主节点将被指定为主主节点,为客户端请求提供服务。这是因为创建日志修改的虚拟文件系统操作应该只发生在主主节点上,因为它们可能会修改外部状态(UFS 和工作节点)。Raft 在内部使用领导者选举作为其共识算法的一部分,Alluxio 使用该算法来任命主节点。为了减少两个主 master 并发运行的可能性,Alluxio 添加了一个额外的同步层,允许以前的主 master 在新的主 master 开始服务客户端请求之前显式降级或超时。
使用 Raft 极大地简化了实现,提高了 Alluxio 高可用和容错 master 的性能和可扩展性。Zookeeper 和 UFS 的外部系统的运行已被直接在 Alluxio 主节点上运行的 Raft 的 Apache Ratis [8] 实现所取代。不再需要恢复后重放低级日志的概念。相反,我们只需要使用 RocksDB 访问快速键值存储,这些存储由 Raft 高效且一致地复制,以确保高可用性和容错性。我们还推荐阅读 Confluent 如何通过从 Zookeeper 迁移到 Apache Kafka [9] 中的 Raft 来简化和提高其分布式架构的性能。
参考
[1] 亨特、帕特里克等人。“{ZooKeeper}:互联网规模系统的无等待协调。” 2010 USENIX 年度技术会议(USENIX ATC 10)。2010. https://zookeeper.apache.org。
[2] Junqueira、Flavio P.、Benjamin C. Reed 和 Marco Serafini。“Zab:主备份系统的高性能广播。” 2011 年 IEEE/IFIP 第 41 届国际可靠系统和网络会议 (DSN)。IEEE,2011。
[3] Apache 策展人领袖选举。https://curator.apache.org/curator-recipes/leader-election.html
[4] 翁加罗、迭戈和约翰·奥斯特豪特。“寻找一种可以理解的共识算法。” 2014 USENIX 年度技术会议(Usenix ATC 14)。2014. https://raft.github.io。
[5] Herlihy、Maurice P. 和 Jeannette M. Wing。“线性化:并发对象的正确性条件。” ACM 编程语言和系统交易 (TOPLAS) 12.3 (1990):463-492。
[6] 岩石数据库。http://rocksdb.org。
[7] 奥尼尔、帕特里克等人。“日志结构的合并树(LSM-tree)。” 信息学报 33.4 (1996): 351-385。
[8] 阿帕奇拉蒂斯。https://ratis.apache.org。
[9] Apache Kafka 变得简单:第一次看到没有 ZooKeeper 的 Kafka。https://www.confluent.io/blog/kafka-without-zookeeper-a-sneak-peek/。
