




简介
Apache Spark
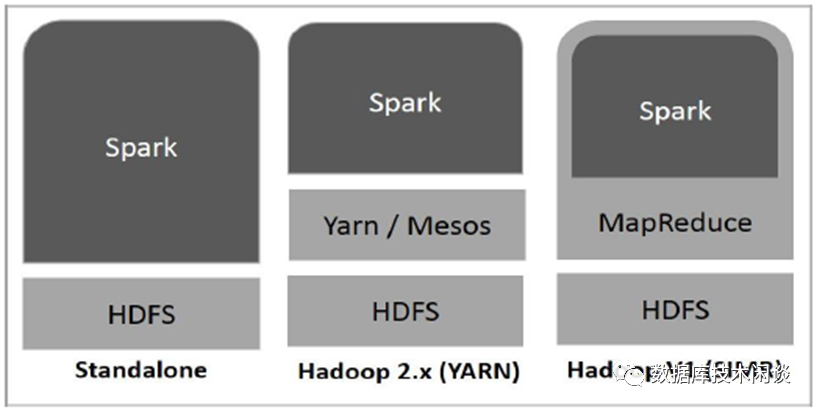
Standalone - Spark 独立部署意味着 Spark 占据 HDFS(Hadoop分布式文件系统)顶部的位置,并明确为 HDFS 分配空间。这里,Spark 和 MapReduce 将并行运行以覆盖集群上的所有 Spark 作业。
Hadoop Yarn - Hadoop Yarn 部署意味着,Spark 只需运行在 Yarn 上,无需任何预安装或根访问。它有助于将 Spark 集成到 Hadoop 生态系统或 Hadoop 堆栈中。它允许其他组件在堆栈顶部运行。
Spark in MapReduce (SIMR) - MapReduce 中的 Spark 用于在独立部署之外启动 Spark job 。使用 SIMR,用户可以启动 Spark 并使用其 shell 而无需任何管理访问。
Apache Spark Core
Spark Core是spark平台的基础通用执行引擎,所有其他功能都是基于。它在外部存储系统中提供内存计算和引用数据集。
Spark SQL
Spark SQL是SparkCore之上的一个组件,它引入了一个称为SchemaRDD的新数据抽象,它为结构化和半结构化数据提供支持。
Spark Streaming
Spark Streaming 利用 SparkCore 的快速调度功能来执行流式分析。它以小批量获取数据,并对这些小批量的数据执行RDD(弹性分布式数据集)转换。
部署
操作系统
修改会话限制
vim etc/security/limits.conf* soft nofile 1000000* hard nofile 1000000* soft stack 32768* hard stack 32768
操作系统增加用户 hadoop
useradd hadoop
SSH 配置
在hadoop用户下,打通到自身的ssh通道。
ssh-keygen -t rsassh-copy-id 192.168.111.188
JDK
yum -y install java-1.8.0-openjdk.x86_64
vim etc/profileexport JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64
Hadoop
软件下载
软件安装
tar zxvf hadoop-3.3.2.tar.gz -C/opt/apache/ln -s opt/apache/hadoop-3.3.2 opt/apache/hadoopchown -R hadoop.hadoop opt/apache/hadoop
hadoop 配置
[hadoop@sfx111188 ~]$ vim ~/.bash_profileexport HADOOP_HOME=/opt/apache/hadoopexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
[hadoop@sfx111188 ~]$ vim core-site.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://192.168.111.188:9000</value></property><property><name>hadoop.tmp.dir</name><value>/opt/apache/hadoop/data</value></property><property><name>dfs.namenode.data.dir</name><value>file:///${hadoop.tmp.dir}/dfs/sfx111188</value></property><property><name>dfs.datanode.data.dir</name><value>file:///opt/apache/hadoop/data</value></property><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property></configuration>
fs.defaultFS 指定 Hadoop 默认访问IP和端口。 hadoop.tmp.dir 指定 Hadoop 临时目录 opt/apache/hadoop/data,这个目录我建成一个软链接,会指向一个 SSD 目录或者 BCache 目录。 dfs.datanode.data.dir 指向 Hadoop 数据目录 opt/apache/hadoop/data。同上。
[hadoop@sfx111188 ~]$ vim hdfs-site.xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>
dfs.replication 指定HDFS 的数据副本数,这里是单机测试,设置为1。
[hadoop@sfx111188 ~]$ vim ~/.bash_profileexport JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64
HDFS 格式化
[hadoop@sfx111188 ~]$ hdfs namenode -format2022-03-14 14:14:44,791 INFOnamenode.FSNamesystem: Retry cache on namenode is enabled2022-03-14 14:14:44,792 INFOnamenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cacheentry expiry time is 600000 millis2022-03-14 14:14:44,793 INFO util.GSet:Computing capacity for map NameNodeRetryCache2022-03-14 14:14:44,793 INFO util.GSet: VMtype = 64-bit2022-03-14 14:14:44,793 INFO util.GSet:0.029999999329447746% max memory 26.7 GB = 8.2 MB2022-03-14 14:14:44,793 INFO util.GSet:capacity = 2^20 = 1048576 entriesRe-format filesystem in Storage Directoryroot= /data2/hdfs/dfs/name; location= null ? (Y or N) y2022-03-14 14:14:57,837 INFOnamenode.FSImage: Allocated new BlockPoolId:BP-1765820763-192.168.111.188-16472384978312022-03-14 14:14:57,838 INFO common.Storage:Will remove files: [/data2/hdfs/dfs/name/current/seen_txid,/data2/hdfs/dfs/name/current/edits_inprogress_0000000000000000003,/data2/hdfs/dfs/name/current/fsimage_0000000000000000000.md5,/data2/hdfs/dfs/name/current/VERSION, /data2/hdfs/dfs/name/current/fsimage_0000000000000000000,/data2/hdfs/dfs/name/current/edits_0000000000000000001-0000000000000000002]2022-03-14 14:14:57,846 INFOcommon.Storage: Storage directory data2/hdfs/dfs/name has been successfullyformatted.2022-03-14 14:14:57,868 INFO namenode.FSImageFormatProtobuf:Saving image file data2/hdfs/dfs/name/current/fsimage.ckpt_0000000000000000000using no compression2022-03-14 14:14:57,986 INFOnamenode.FSImageFormatProtobuf: Image file/data2/hdfs/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 398 bytessaved in 0 seconds .2022-03-14 14:14:57,991 INFOnamenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 02022-03-14 14:14:58,111 INFOnamenode.FSNamesystem: Stopping services started for active state2022-03-14 14:14:58,111 INFOnamenode.FSNamesystem: Stopping services started for standby state2022-03-14 14:14:58,113 INFOnamenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.2022-03-14 14:14:58,113 INFOnamenode.NameNode: SHUTDOWN_MSG:/************************************************************SHUTDOWN_MSG: Shutting down NameNode atsfx111188/192.168.111.188************************************************************/
启动Hadoop 集群
[hadoop@sfx111188 ~]$ cd $HADOOP_HOME[hadoop@sfx111188 ~]$ sbin/start-dfs.shStarting namenodes on [sfx111188]Last login: Mon Mar 14 09:27:54 CST 2022 from 192.168.108.15 on pts/5sfx111188: Warning: Permanently added 'sfx111188' (ECDSA) to the listof known hosts.Starting datanodesLast login: Mon Mar 14 11:26:12 CST 2022 on pts/2Starting secondary namenodes [sfx111188]Last login: Mon Mar 14 11:26:14 CST 2022 on pts/2Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF8
[hadoop@sfx111188 ~]$ jpsPicked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF897075 DataNode128627 Jps97403 SecondaryNameNode159369 XMLServerLauncher96890 NameNode
[root@sfx111188 hadoop]# netstat -ntlpActive Internet connections (only servers)Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program nametcp 0 0 0.0.0.0:9867 0.0.0.0:* LISTEN 97075/javatcp 0 0 0.0.0.0:9868 0.0.0.0:* LISTEN 97403/javatcp 0 0 0.0.0.0:9870 0.0.0.0:* LISTEN 96890/javatcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1718/rpcbindtcp 0 0 127.0.0.1:13072 0.0.0.0:* LISTEN 125603/nodetcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 4629/sshdtcp 0 0 127.0.0.1:32505 0.0.0.0:* LISTEN 97075/javatcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 5227/mastertcp 0 0 0.0.0.0:9864 0.0.0.0:* LISTEN 97075/javatcp 0 0 192.168.111.188:9000 0.0.0.0:* LISTEN 96890/javatcp 0 0 0.0.0.0:9866 0.0.0.0:* LISTEN 97075/javatcp6 0 0 :::111 :::* LISTEN 1718/rpcbindtcp6 0 0 :::22 :::* LISTEN 4629/sshdtcp6 0 0 ::1:25 :::* LISTEN 5227/master
Hive
软件安装
[hadoop@sfx111188 ~]$ vim ~/.bash_profileexport HIVE_HOME=/opt/apache/hiveexport PATH=$PATH:$HIVE_HOME/bin
安装MySQL
[root@sfx111188 ~]# yum -y install mysql-server.x86_64
[root@sfx111188 ~]# systemctl start mysqld
[root@sfx111188 ~]# mysql -h127.1 -uroot -P3306 -pcreate database hivedb;create user hive identified by'hive123456';grant all privileges on hivedb.* to hive;
参数文件
[hadoop@sfx111188 ~]$ cd $HIVE_HOME/conf[hadoop@sfx111188 ~]$ vim hive-site.xml<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://sfx111188:3306/hivedb?createDatabaseIfNotExist=true&useSSL=false</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>hive</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>hive123456</value></property><property><name>hive.metastore.warehouse.dir</name><value>/path/to/warehouse</value></property></configuration>
Hive MySQL 驱动
初始化Hive metastore Schema
[hadoop@sfx111188 ~]$ schematool -dbType mysql -initSchema
启动 HiveMetaStore 服务
[hadoop@sfx111188 ~]$ nohup hive --service metastore > ~/hive-metastore.log2>&1 &
Spark SQL
源码下载并编译
package type 选Source Code。下载,解压。
[root@sfx111188 spark-3.2.1]# vim pom.xml<!--url>https://maven-central.storage-download.googleapis.com/maven2/</url--><url>https://maven.aliyun.com/repository/public</url>
[root@sfx111188 spark-3.2.1]# ./dev/make-distribution.sh --namehadoop-3.3.2-hive-3.1.3 --tgz -Pyarn -Dhadoop.version=3.3.2 -Phive-Phive-thriftserver -DskipTests
配置环境变量
[hadoop@sfx111188 ~]$ vim ~/.bash_profileexport SPARK_HOME=/opt/apache/sparkexport PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
配置文件
[hadoop@sfx111188 ~]$ cd $SPARK_HOME/conf[hadoop@sfx111188 ~]$ vim spark-env.sh修改下面参数为实际值。export SPARK_LOCAL_DIRS=/sparkcacheexport SPARK_DRIVER_MEMORY=16gexport SPARK_WORKER_CORES=40export SPARK_EXECUTOR_CORES=24export SPARK_EXECUTOR_MEMORY=16g
[hadoop@sfx111188 ~]$ vim spark-defaults.confspark.eventLog.enabled truespark.eventLog.dir hdfs://sfx111188:9000/user/hadoop/logs/sparkspark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value-Dnumbers="one two three"spark.memory.fraction=0.75spark.driver.maxResultSize=4g
[hadoop@sfx111188 ~]$ vim hive-site.xml<?xml version="1.0" encoding="UTF-8"standalone="no"?><?xml-stylesheettype="text/xsl" href="configuration.xsl"?><configuration><property><name>hive.metastore.warehouse.dir</name><value>/user/hadoop/warehouse</value></property><property><name>hive.metastore.uris</name><value>thrift://sfx111188:9083</value></property></configuration>
Spark SQL里数据库和表的文件会放在Hadoop中,具体是 hive.metastore.warehouse.dir 。
[hadoop@sfx111188 ~]$ hdfs dfs -mkdir -p /user/hadoop/warehouse
[hadoop@sfx111188 ~]$ hdfs dfs -ls /user/hadoop/warehouse
启动Spark History 服务
[hadoop@sfx111188 ~]$ start-history-server.sh
测试Spark SQL 连接。
[hadoop@sfx111188 ~]$ jps20049 NameNode31057 HistoryServer21874 SecondaryNameNode21495 DataNode34555 Jps23084 NodeManager22303 ResourceManager
[hadoop@sfx111188 ~]$ spark-sqlSetting default log level to"WARN".To adjust logging level usesc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).2022-05-17 17:35:25,473 WARNutil.NativeCodeLoader: Unable to load native-hadoop library for yourplatform... using builtin-java classes where applicable2022-05-17 17:35:27,561 WARN util.Utils:Service 'SparkUI' could not bind on port 4040. Attempting port 4041.Spark master: local[*], Application Id:local-1652780127695spark-sql>spark-sql> show databases;defaultTime taken: 3.794 seconds, Fetched 1 row(s)spark-sql>
[hadoop@sfx111188 ~]$ netstat -ntlp |grep 4041(Not all processes could be identified,non-owned process infowillnot be shown, you would have to be root to see it all.)tcp6 0 0 :::4041 :::* LISTEN 15986/java[hadoop@sfx111188 ~]$
参考
Spark 介绍_w3cschool
https://www.w3cschool.cn/spark_sql/spark_introduction.html
从零搭建 Spark SQL + Hive 开发环境 - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/360945733
