




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
本文主要是对 PostgreSQL 中的进程架构和内存架构做下简单介绍,适用于初学者阅读。
postgres server process:Postgres服务器进程,即守护进程,是数据库集群管理的所有进程的父进程。 backend processes:后端进程,每个后端进程处理连接进来的客户端发出的所有查询和语句。 backgroud processes:后台进程,每个后台进程分别执行相应的功能(例如VACUUM和CHECKPOINT进程)以进行数据库管理。
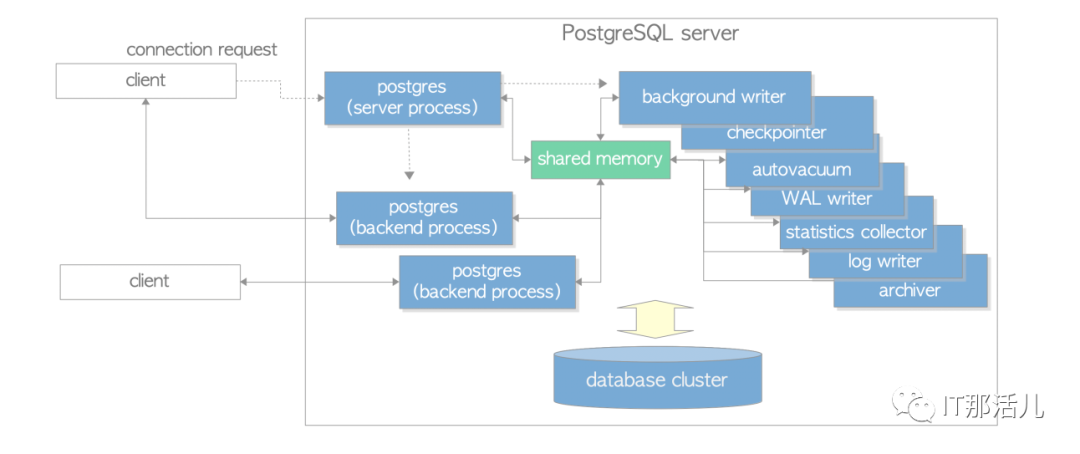 图1.1.PostgreSQL进程结构示意图
图1.1.PostgreSQL进程结构示意图
background writer(后台写进程):定期将shared buffer pool中的脏数据写到磁盘上的进程,checkpoint也会触发这个过程,类似Oracle的dbwn进程。当插入或更新数据时,并不会马上把数据持久化至数据文件中。 这是基于提高插入、更新及删除数据的性能考虑的,毕竟写内存比写硬盘会快很多。BgWriter会周期性的将内存中的脏块刷新至磁盘,刷脏块既不能太快也不能太慢。 如果一个数据库短时间内被修改多次,当刷新过快的情况下,它每次的修改都会保存至磁盘,这会导致I/O增加,从而影响性能。刷新过慢时,对于繁忙的数据库而言,内存中存放大量的脏块未刷新至磁盘,假设此时无可用内存,当有新的更新需要使用内存来保存从磁盘中读取的数据块时,需要等待脏块刷新至磁盘把内存腾挪出来。 这样会导致更新需要等更长的时间。并且如果出现异常宕机的情况,重启时需要恢复的那部分没有刷新至磁盘的脏块,也影响其故障恢复的时间。其机制由如下参数来控制:

Checkpointer进程:执行checkpoint,类似Oracle的ckpt
autovacuum launcher进程:为vacuum process周期性的调用autovacuum work processes,用于旧数据的清除。wal writer进程:将wal buffer的数据刷新到磁盘,WAL log另称为预写式日志。即在事务提交之前,必须将这些修改操作记录到磁盘中。这样就不需要实时地将脏数据持久化到磁盘。 即便服务器突然宕机或数据库异常宕掉,导致一部分内存中的脏块未刷新至文件,在数据库重启后,通过读取WAL日志,将这部分事务重放一遍就可以将数据库恢复至宕机的时刻。 stats collector进程:收集统计信息,例如pg_stat_activity 和pg_stat_database的统计信息。 logging collector (logger)进程:将错误信息写入到日志。 Archiver进程:将WAL log归档。
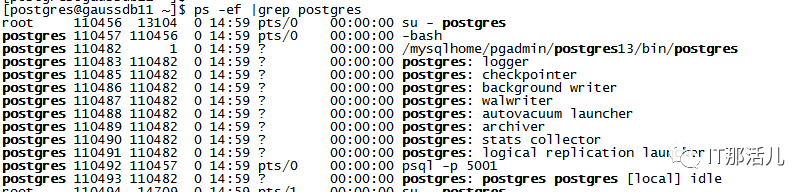
Local memory area,由每个backend process后端进程分配以供其自己使用。
Shared memory area,由PostgreSQL server的所有服务进程共享使用的内存。
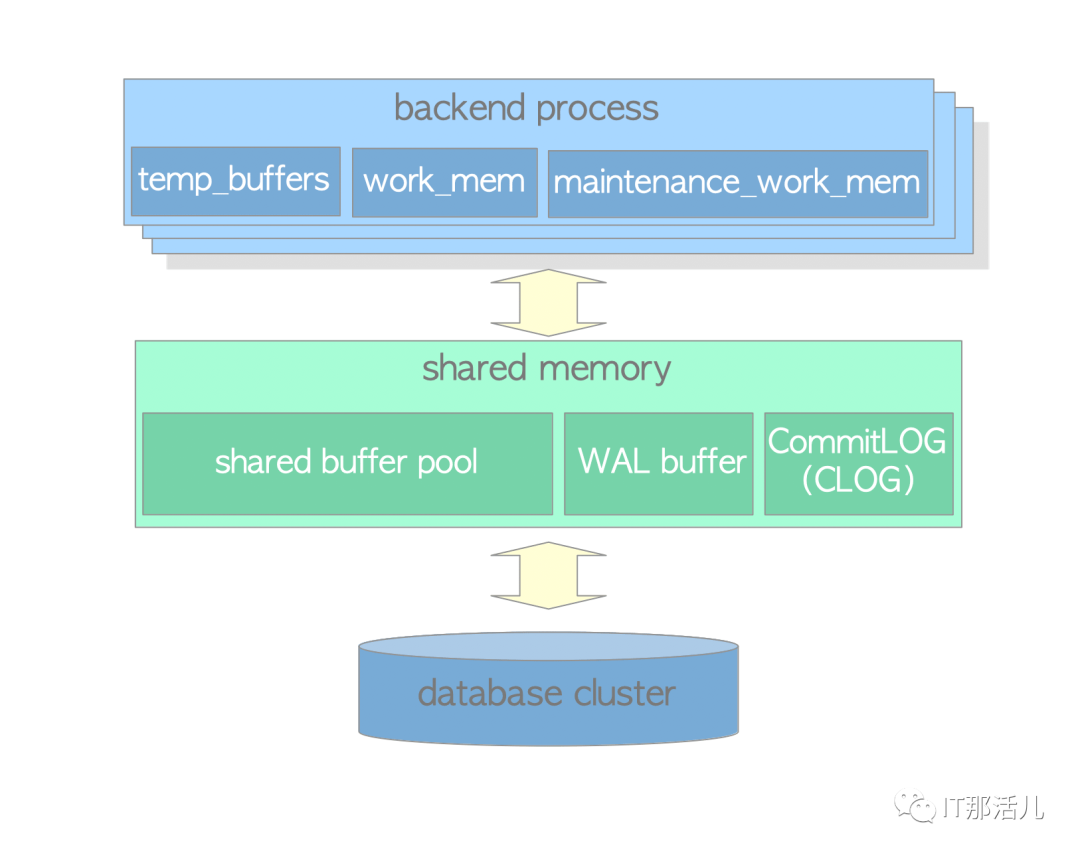 图 2.1. PostgreSQL的内存结构
图 2.1. PostgreSQL的内存结构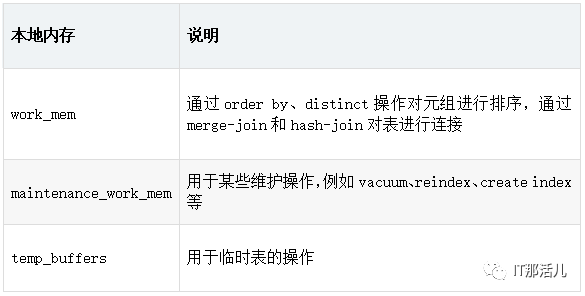
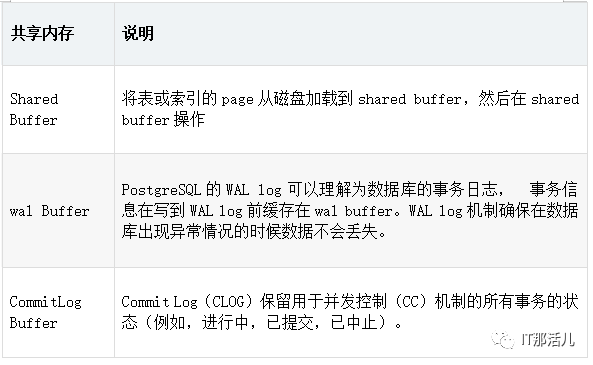
为各种访问控制机制分配的子区域,例如轻量级锁,共享锁和排他锁等。 各种后台进程的子区域,例如checkpointer和autovacuum。 为事务处理提供的子区域,比如事务中的save-point,和二阶段事务提交。 其他。
END
本文作者:魏 斌
本文来源:IT那活儿(上海新炬王翦团队)

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
