




概念
把堆(heap)比作一本书的话,index 类似于书本结尾的索引,可以根据关键词找到索引,从而找到指向数据的页码,从而更快更方便的查询所需的 tuple(元组)
目的:提高查询性能(perfomance)
index(索引) 和 table(表) 存储在不同的物理文件中,所以需要额外的空间来存放索引,index 和 table 在 PostgreSQL 数据库中统称为 relation(关系),相关的信息保存在 pg_class系统表中。
创建索引
语法
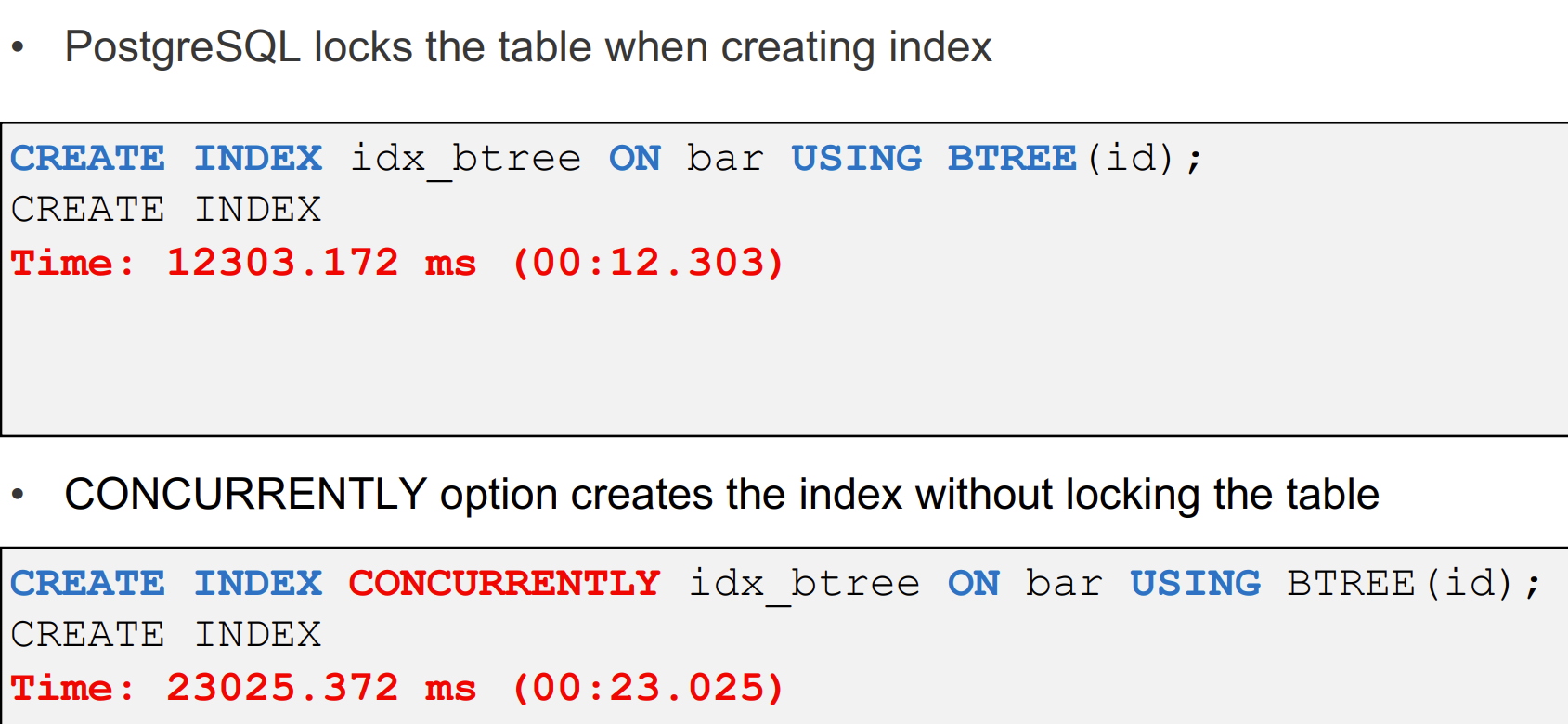
在创建索引的时候会 lock 表,可以使用 CIC (create index concurrently),但创建索引的时间相对较长
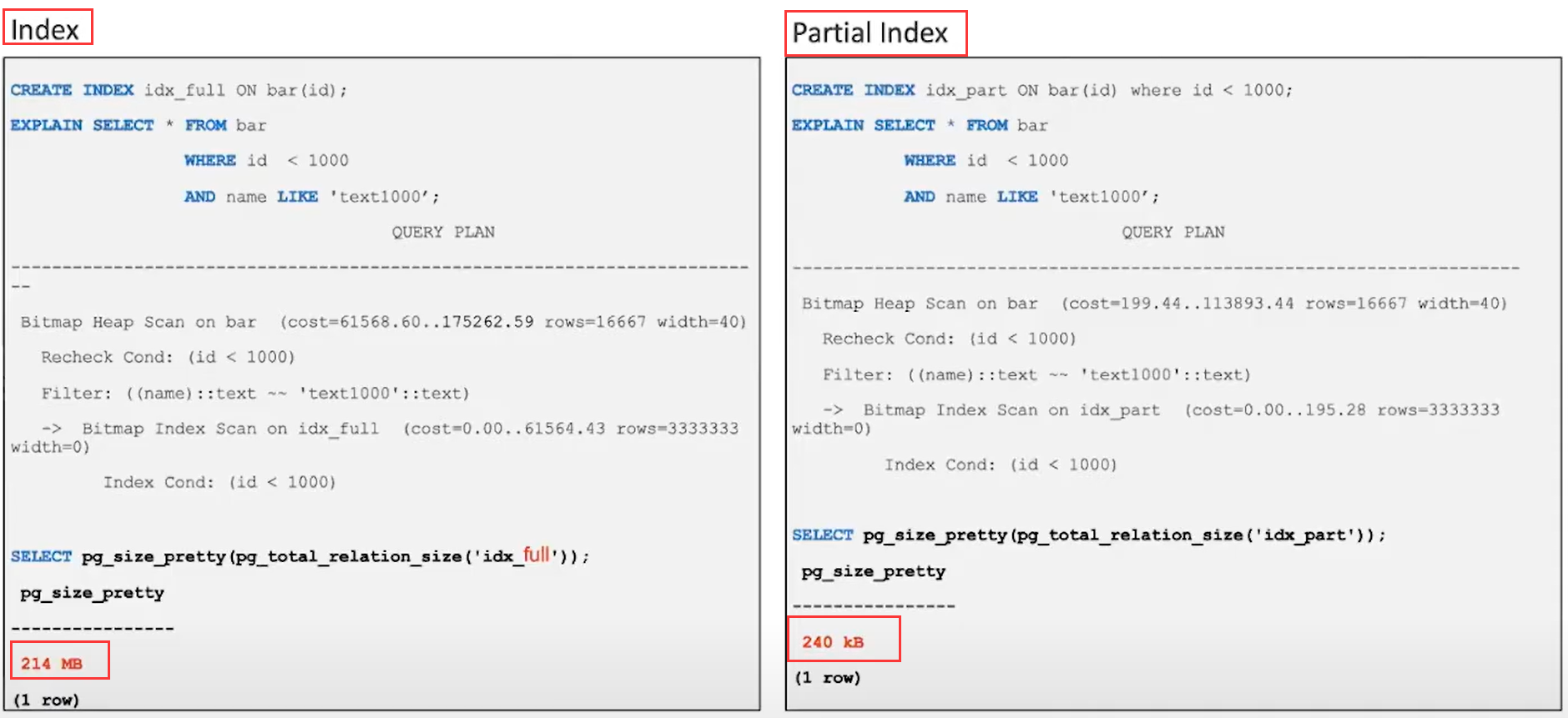
Partial Index - 部分索引
-
partial index 是对于表的部分数据创建索引
-
如果发现表的某一部分数据查询次数较多时,可以考虑在这部分数据上创建一个部分索引
-
部分索引相较于
full index,查询的性能提高,并且部分索引文件所占的空间也会小于全索引

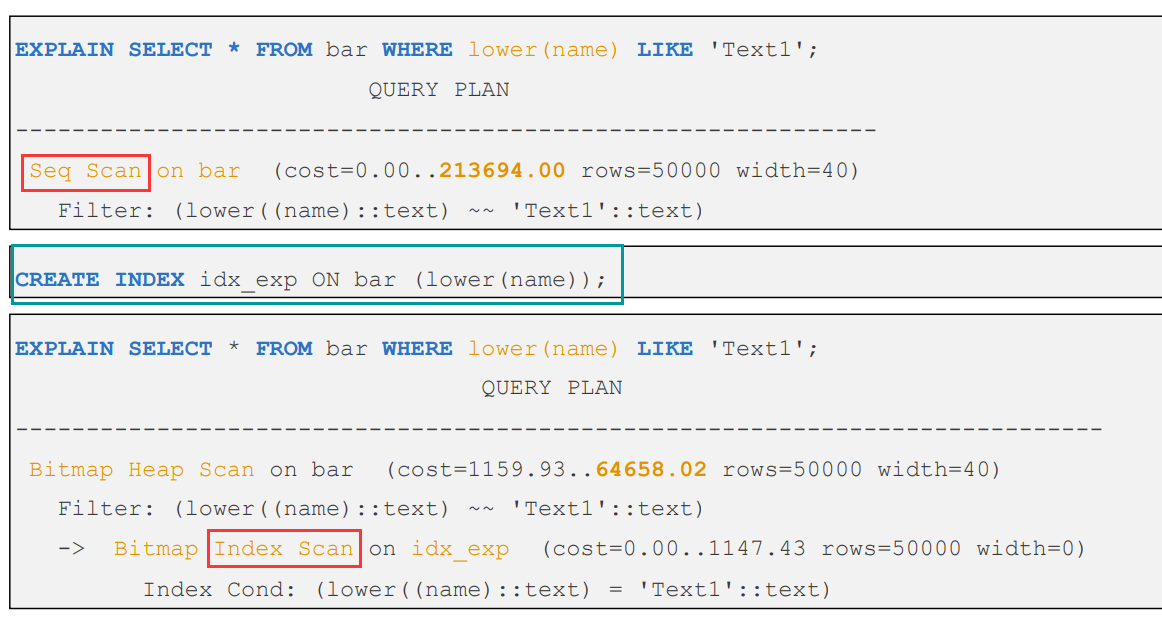
Expression Index - 表达式索引
-
除针对表的字段直接创建索引外,还可以对字段进行某种运算之后的结果创建索引。
-
对于表达式索引的维护代价比较高,因为在每一行插入或更新时需要重新计算相应表达式的值,但是针对于表达式索引在查询时的效率更高,因为表达式的值会直接存储在索引中
例1:

例2:

索引类型
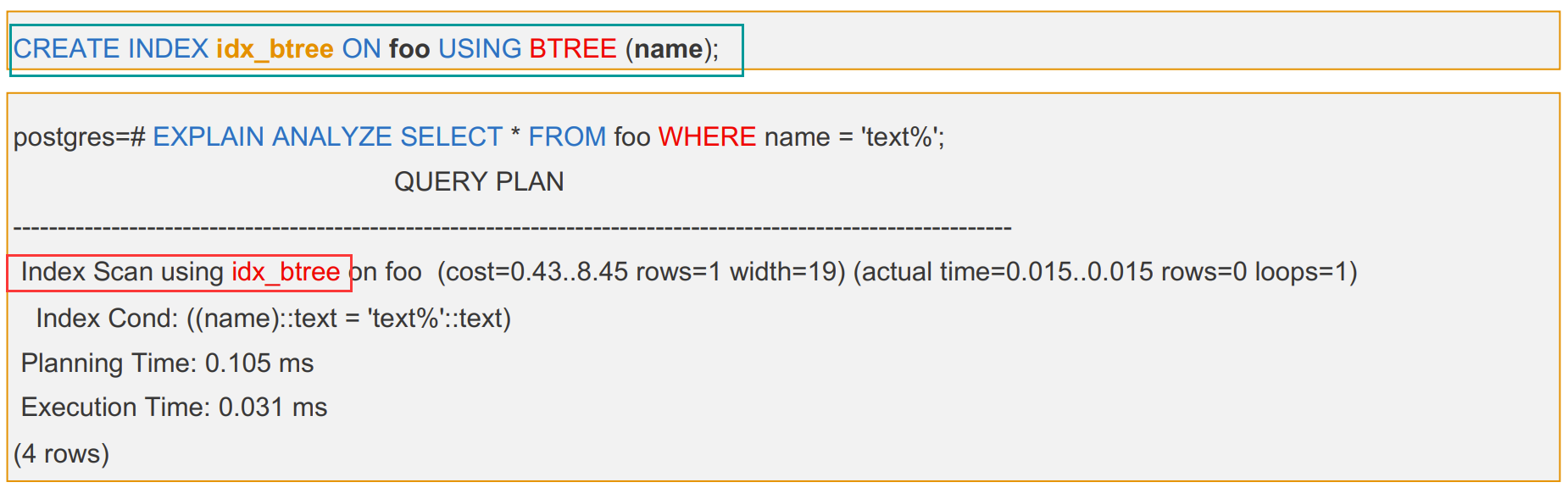
1、B-TREE - B树索引
- PostgreSQL 数据库默认的索引
- 适用于大多数查询语句和多种操作类型
- 存放元组的CTID、键值

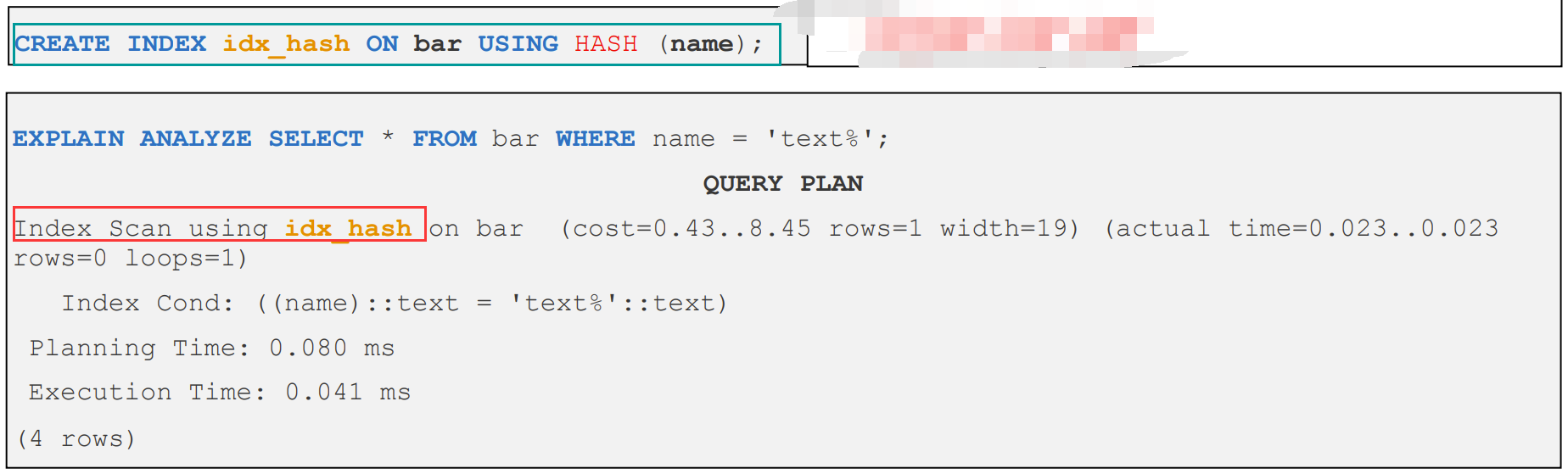
2、HASH - 哈希索引
- 适用于等值查询

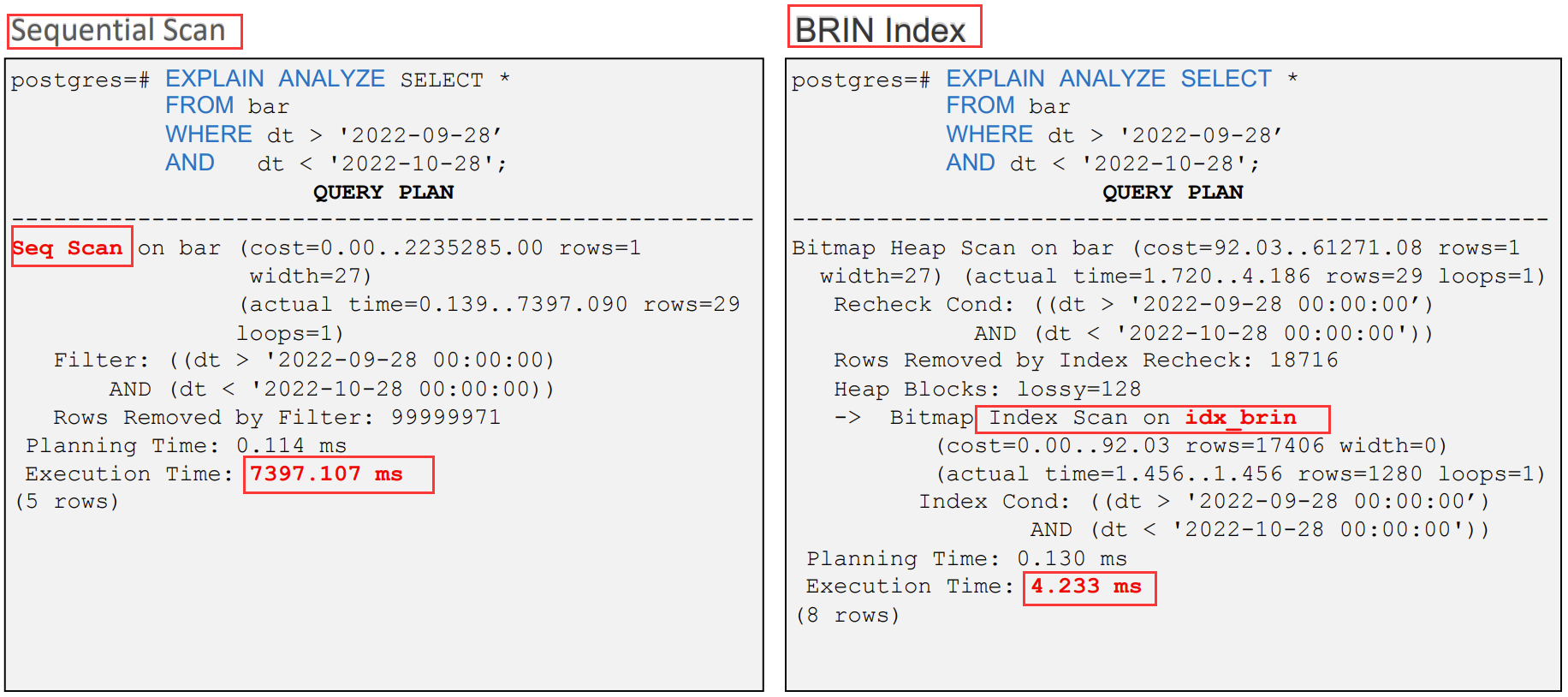
3、BRIN - 块范围索引
- 块范围索引:Block Range Index
- 适用于列与它们在表中存储的物理位置存在某种相关性
- 存储:页码、列的最大值和最小值
- 优点:索引文件小
例:

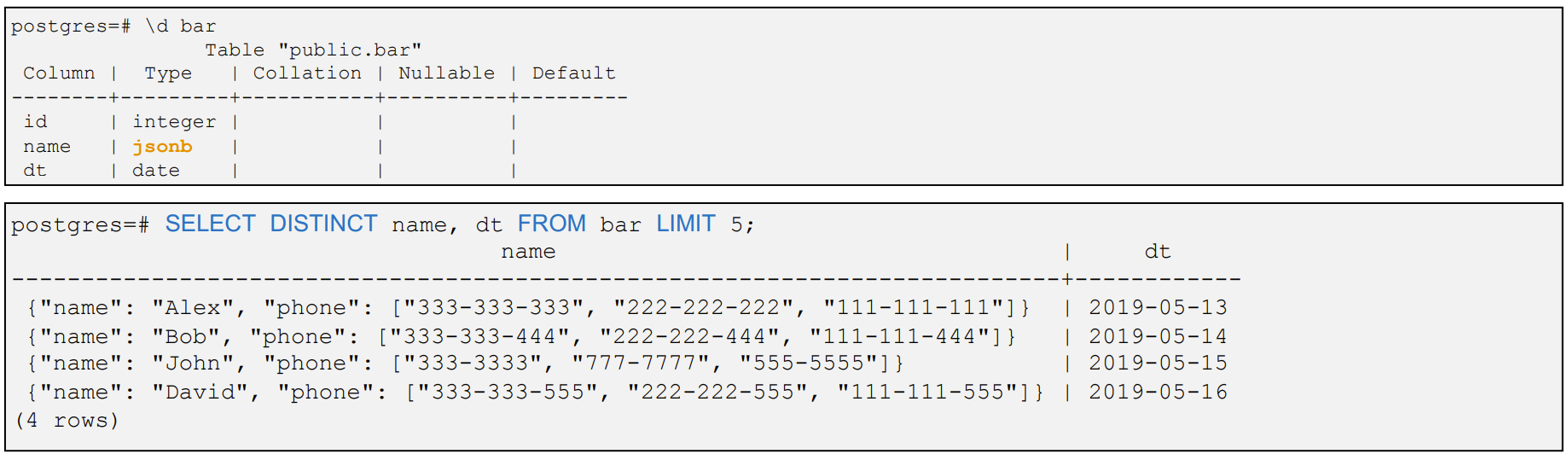
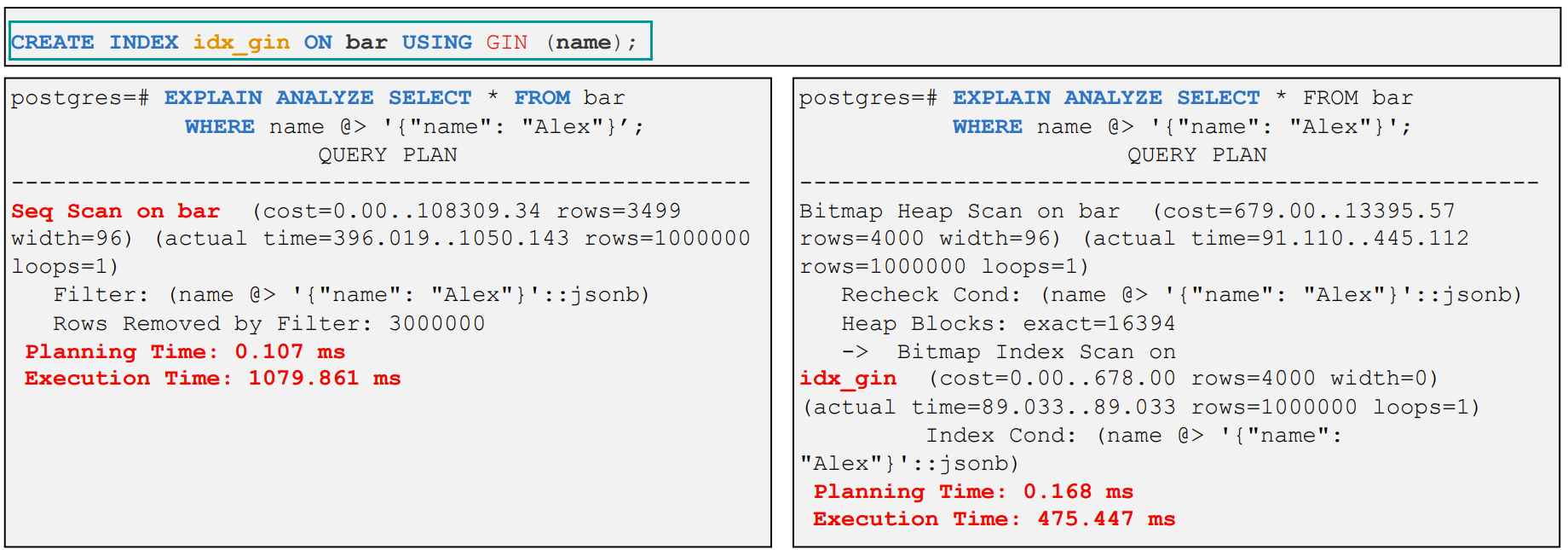
4、GIN - 通用倒排索引
- 通用倒排索引:Generalized Inverted Index
- 适用:处理被索引项为组合值
- 创建索引时速度较慢,因为它需要提前扫描文档


5、GIST - Generalized Search Tree
- 是一种平衡的,树状结构的访问方法
- GiST索引并不是一种单独的索引,而是可以用于实现很多不同索引策略的框架
- 适用于全文搜索、Int数组等
小结 - 索引的选择
- B-TREE 索引:适用于大多数查询或不同的数据类型
- HASH 索引:适用于等值查询
- BRIN 索引:适用于 非常大的顺序排列数据集
- GIN 索引:文档和数组
- GIST索引:全文搜索
索引维护
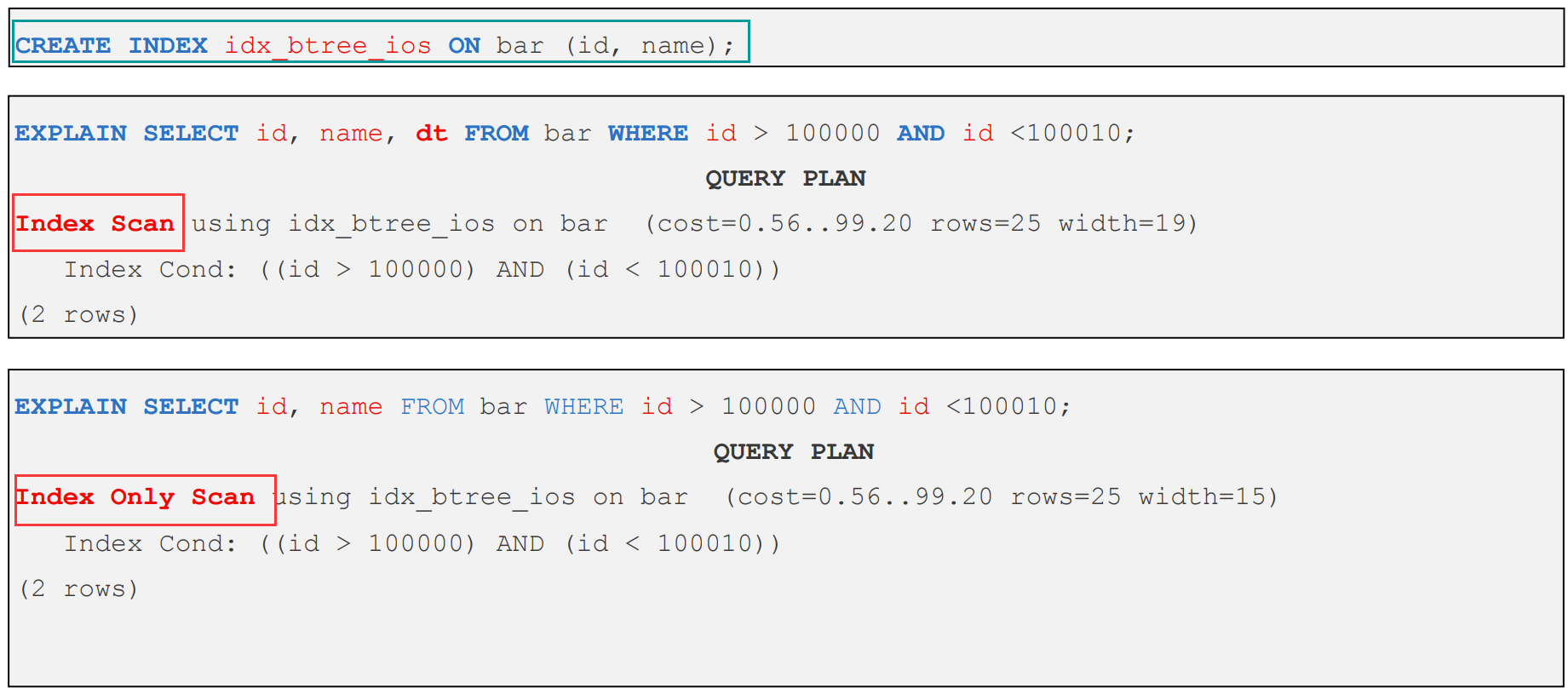
1、Index Only Scan - 仅索引扫描
- SELECT 表的目标列都在索引键中,为了减少 I/O,仅索引扫描会直接使用索引中的键值

2、Duplicate Indexes - 重复索引
pg中允许在同一个列创建多个索引,而大部分情况下都是不需要的
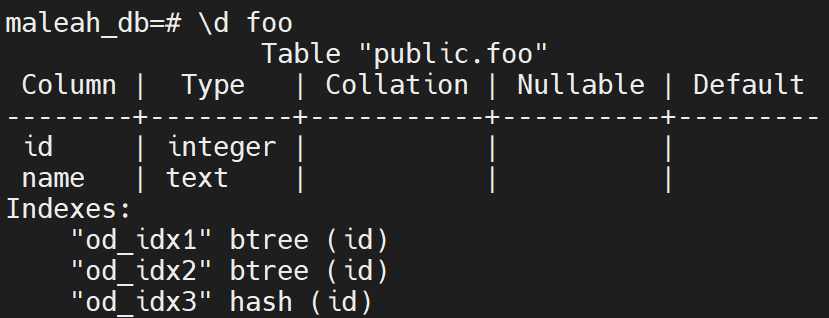

常见查询重复索引SQL:(相关视图:pg_index)
-- 1.
SELECT relname,(array_agg(idx))[1] idx1,
pg_get_indexdef((array_agg(idx))[1]) idx1_def,
(array_agg(idx))[2] idx2,
pg_get_indexdef((array_agg(idx))[2]) idx2_def,
(array_agg(idx))[3] idx3,
pg_get_indexdef((array_agg(idx))[3]) idx3_def
FROM (
SELECT indrelid::regclass AS relname,
indexrelid::regclass AS idx,
(indrelid::text || indclass::text || indkey::text || COALESCE(indexprs::text,'') || COALESCE(indpred::text,'')) AS KEY
FROM pg_index) sub
GROUP BY relname, KEY
HAVING count(*) > 1 \gx
-[ RECORD 1 ]-------------------------------------------------
relname | foo
idx1 | od_idx1
idx1_def | CREATE INDEX od_idx1 ON public.foo USING btree (id)
idx2 | od_idx2
idx2_def | CREATE INDEX od_idx2 ON public.foo USING btree (id)
idx3 |
idx3_def |
-- 2.
SELECT
indrelid::regclass AS TableName
,array_agg(indexrelid::regclass) AS Indexes
FROM pg_index
GROUP BY
indrelid
,indkey
HAVING COUNT(*) > 1;
tablename | indexes
-----------+---------------------------
foo | {od_idx1,od_idx2,od_idx3}
(1 row)
-- 3.
SELECT indrelid::regclass relname,
indexrelid::regclass indexname,
indkey
FROM pg_index
GROUP BY relname,indexname,indkey;
relname | indexname | indkey
-------------------------+-----------------------------------------------+---------
pg_toast.pg_toast_59571 | pg_toast.pg_toast_59571_index | 1 2
pg_index | pg_index_indexrelid_index | 1
pg_toast.pg_toast_2615 | pg_toast.pg_toast_2615_index | 1 2
pg_constraint | pg_constraint_conparentid_index | 11
foo | od_idx1 | 1
-- 4.
SELECT indrelid::regclass relname, indkey, amname
FROM pg_index i, pg_opclass o, pg_am a
WHERE o.oid = ALL (indclass)
AND a.oid = o.opcmethod
GROUP BY relname, indclass, amname, indkey
HAVING count(*) > 1;
relname | indkey | amname
---------+--------+--------
foo | 1 | btree
(1 row)
对于判断重复索引,要根据不同的情况来看是否要进行删除
3、Unused Indexes - 未使用的索引
SELECT relname, indexrelname, idx_scan
FROM pg_catalog.pg_stat_user_indexes;
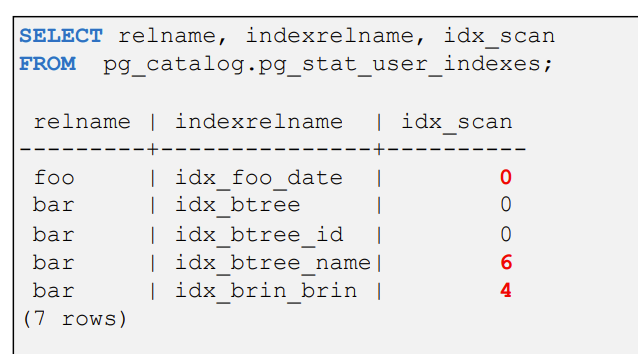

如果有些索引长期未被使用,那么有可能这些索引是错误的创建的,这些索引不会发挥任何作用,而且会占用不必要的空间让数据插入修改删除的成本变大,增加备份的开销。清理这些长期未使用的索引对系统整体性能提升帮助很大。
通过pg_stat_user_indexes统计视图我们可以很清晰的了解到某个索引最近是否使用过。如果对于一段时间(比如几个月,半年)没有使用的索引,我们可以列入未使用索引清理备选清单,经过甄别确认后,进行清除。
-- 无效的索引
select indexrelid,indisvalid from pg_index where indisvalid = 'f' ;
