





Gartner(高德纳,又译顾能公司,NYSE: IT and ITB)全球最具权威的IT研究与顾问咨询公司,成立于1979年,总部设在美国康涅狄克州斯坦福。其研究范围覆盖全部IT产业,就IT的研究、发展、评估、应用、市场等领域,为客户提供客观、公正的论证报告及市场调研报告,协助客户进行市场分析、技术选择、项目论证、投资决策。为决策者在投资风险和管理、营销策略、发展方向等重大问题上提供重要咨询建议,帮助决策者作出正确抉择。
1. 解读数据技术领域《Hype Cycle》报告
1).Hype Cycle
Hype cycle描述了一项技术从诞生到成熟的过程,并将现有各种技术所处的发展阶段标注一张曲线图上。图中从成熟度、关注度两个维度来衡量技术的发展过程。就其一般规律而言,技术发展遵循从早期萌芽、到受到热捧关注度急增,再到泡沫破裂进入幻没期,然后慢慢复苏逐步回升,最终进入平稳发展的成熟期。当然有些技术,因发展速度可能跨过其中某个或几个阶段,或直接接入成熟后的阶段。当从这一过程中消失的技术,并不是说明其已经过时,而是说明其已经相对成熟、受到关注的程度变化不大;也有可能不再受到关注逐步消亡。
技术发展曲线的分析结果,经常作为对行业整体发展趋势的判断。也常常作为投资或选择某项技术的参考依据。通常来说,不要仅仅因为某项技术受到关注度很高就投资或选择它,也不要因为其未达到早期过高的预期而忽视它。要结合企业整体发展策略,有针对性的进行选择。在早期投入核心关键技术,将有利于企业构建核心竞争力,占据关键赛道。而对其他技术领域,可采取跟随策略,长期关注其发展,在相对技术成熟、风险较小的阶段再介入。
 图中,横坐标表示技术的成熟度(Time),纵轴表示技术受关注的程度(Visibility)。其中的曲线表明:在相关领域里,每项技术的发展过程均可分为五个阶段:萌芽期、过热期、幻灭期、复苏期、成熟期。
图中,横坐标表示技术的成熟度(Time),纵轴表示技术受关注的程度(Visibility)。其中的曲线表明:在相关领域里,每项技术的发展过程均可分为五个阶段:萌芽期、过热期、幻灭期、复苏期、成熟期。
萌芽期(上升期)
这一时期处于技术早期的理论研究阶段,此时还没有研究成果出来,但已经吸引一定人群的关注。
过热期(快速发展期)
随着理论研究的深入,其出现快速增长的趋势,并很快达到高峰。这一时期大量理论研究成果出现,人们的关注程度激增。但这一阶段,也还没有出现太多商业化应用出现。
幻灭期(下降期)
随着到达关注度的顶端,基础理论基本成熟,研究成果的总量已经很多,理论探索空间越来越小。此后,理论工作者对该项技术的关注程度逐渐降低。而此时,该项技术在产业上的应用尚未成熟,因此,新技术的受关注程度进入下降期。
复苏期(爬坡期)
随着新技术在产业应用中的逐渐成功,产业技术的研究热潮使得该项技术的受关注程度再次增加,并将其带入一个持续发展的爬坡期。相对于理论研究而言,产业技术研究的内容要细致和深入得多。因此,这个阶段的发展速度已远远不如之前那么迅速。
成熟期(稳定应用期)
最终,随着基本产业技术的成熟,大量应用技术研究成果出现,技术进入稳定应用期。即这个阶段之后,这项技术不再作为一种“新技术”受到人们的关注。
2).衍生报告:投资回报
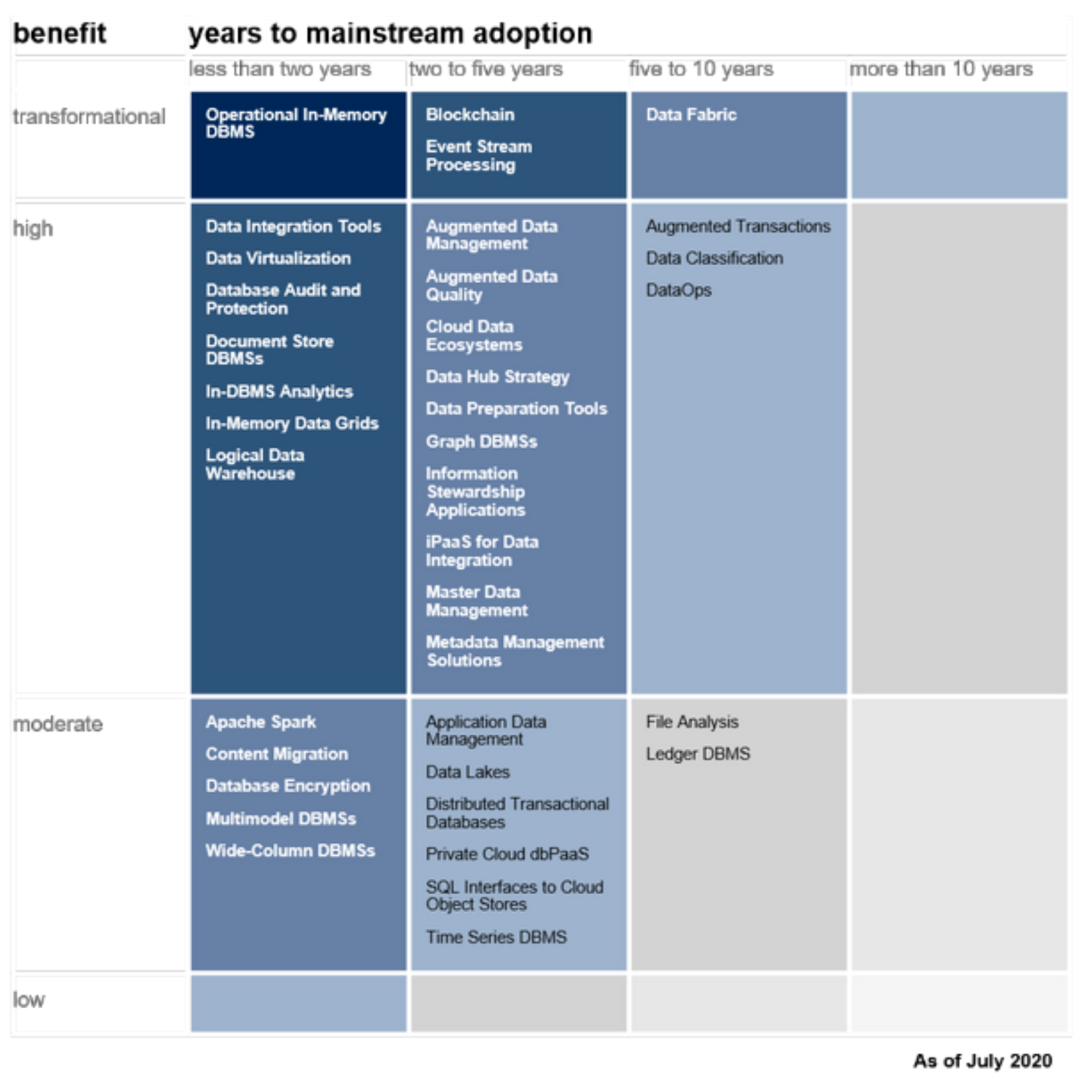
除了上面报告外,Gartner还衍生提供了技术投资回报分析报告(如下图)。其纵向代表投资某技术的收益情况,横向代表技术成熟度与市场接受时间。显然,左上角的技术是属于短期挣快钱且收益较大的方向,当然其风险也很大;反之则相对收益较小或属于中长期投资方向。
2. 解读数据领域《Hype Cycle》报告
Gartner每年都会针对不同领域技术,出具相关的Hype Cycle报告。下面将以以数据(库)技术关联较高的《Hype Cycle for Data Management》进行说明。其整理当年受关注的技术及其发展阶段。
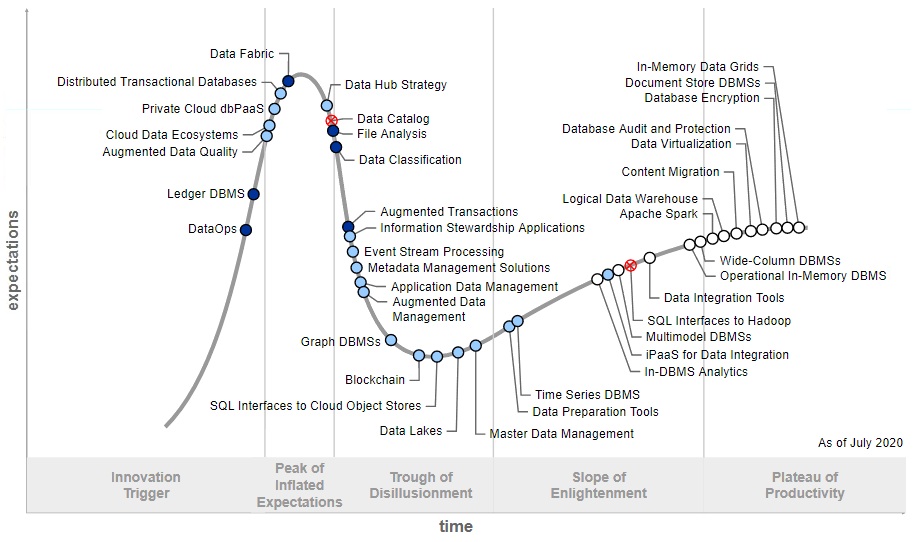
在2020年的报告中共收录39种相关技术,其中萌芽期2种、过热期9种、幻灭期11种、复苏期9种,成熟期8种。其中也有部分技术从前年榜单中退出。具体技术内容的说明,可参见后面。除了上面报告外,Gartner还衍生提供了技术投资回报分析报告(如下图)。其纵向代表投资某技术的收益情况,横向代表技术成熟度与市场接受时间。显然,左上角的技术是属于短期挣快钱且收益较大的方向,当然其风险也很大;反之则相对收益较小或属于中长期投资方向。
3. 数据技术近期发展综述
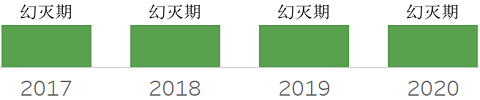
图例说明
为表明每项技术的发展阶段,使用如下图例进行标识。

概述情况
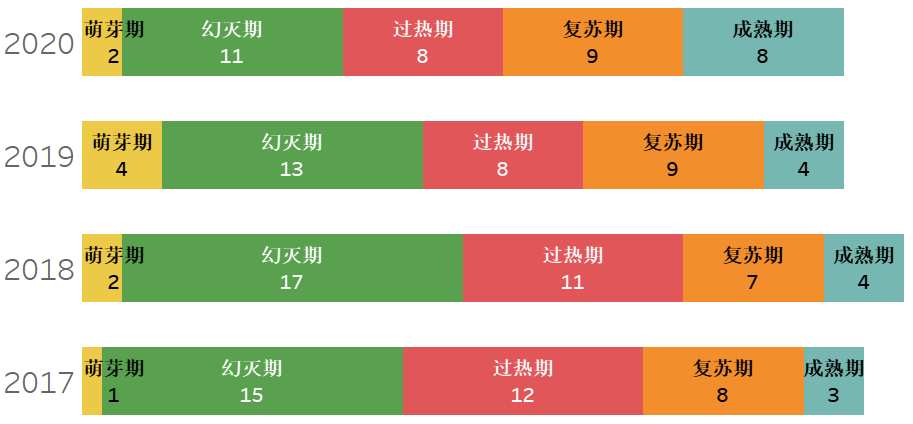
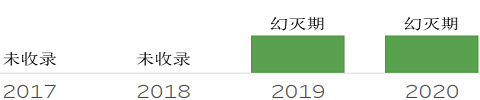
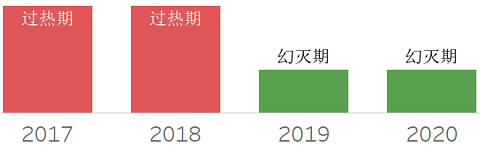
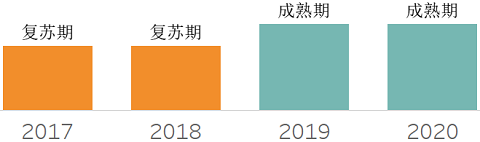
追踪历年Hype Cycle报告,可以观察到技术的演进之路。下面将收集近四年的报告,并针对主要的数据技术加以分析说明。从整体来看,每年都有3、40种技术被收录。
❖ Analytical In-Memory DBMS
❖ Application Data Management
应用数据管理系统,可理解为ERP、CRM之类的系统。
Chain-Sys;Epicor Software;Oracle;PiLog;
SAP;Tealium;Utopia Group;
Winshuttle (EnterWorks)
❖ Augmented Data Management
增强数据管理,是指利用人工智能和机器学习,来优化改进数据管理过程。这里包括数据集成、数据质量、主数据管理、数据库管理系统(RDBMS)本身。近些年来比较热门的自治数据库,就是这一场景。
Amazon;Cinchy;CluedIn;IBM;Informatica;
Microsoft;Oracle;SAP;SnapLogic;Teradata
❖ Augmented Data Quality

增强数据质量,在2020年得到极高的关注度。随着数字化深入,企业中拥有更多的数据资产,如何保证如此大规模数据的质量,为后续数据应用做好铺垫。传统的数据质量过程,面临着效率低下等问题。新出现的增强数据质量,正迎合这一现象,通过引入人工智能、机器学习、自然语言理解等技术手段,在数据分析、清洗、关联、监控、整合等领域,解决传统方式的种种不足。此外Data,在数据安全、隐私保护等领域上,增强数据质量也同样大有可为。当然也要看到,数据质量问题是要在企业整体数据治理下考虑,相应的元数据等能力也需要增强。
Ataccama;IBM;Informatica;MIOsoft;Oracle;
Precisely;SAP;SAS;Talend
❖ Augmented Transactions

增强交易,是指在交易流程中通过增加分析能力,来辅助交易行为的一种技术,包括在交易中使用高级分析、人工智能、机器学习等。通过对关键业务指标的实时分析,可以影响交易主流程。通常我们所说的HTAP,其实也是一种增强交易,只不过是后者范围更加广泛。增强交易的瓶颈在于性能和可扩展性,因而内存计算技术是增强交易的技术关键。
Aerospike;GigaSpaces;GridGain Systems;
IBM;MemSQL;Microsoft;Oracle;SAP;
ScaleOut Software;VoltDB
❖ Blockchain
区块链,大家已经很熟悉了。之前是非常火热的状态,近两年有所降温。原因是其技术价值变现尚未找到明确方向。
Algorand;Block.one;Cardano;Ethereum;
Hyperledger;Neo;R3;Zilliqa
❖ Cloud Data Ecosystems

云数据生态系统,旨在通过统一的方式,将数据及分析交付给业务。其承诺在整个数据生命周期提供一个整体的管理框架,并致力于解决数据集成、数据质量、数据共享、主数据管理及分析需求等难题。通过整体、统一的方式可以将整个交付过程在更短的时间、更好的质量、更少的工作的方式提供出来。为了达到上述能力,是需要云服务商与独立软件提供方合作起来。这一技术当前还处于早期阶段,是需要评估各个组件间的兼容性,进而提供统一的生态系统。
Amazon;Cloudera;Databricks;GCP;IBM;
Microsoft Azure;Oracle;SAP
❖ Content Migration
内容迁移,指将非结构化内容(文件、文档、对象) 永久存储在一个或多个内容存储库中,并传输到一个新的环境(云内容服务)的过程。
AvePoint;Binary Tree;Proventeq;Quest Software;
ShareGate;Simflofy;SkySync,
T-Systems;Tervela(Cloud FastPath);Xillio
❖ Crosss-Platform Structured Data Archiving
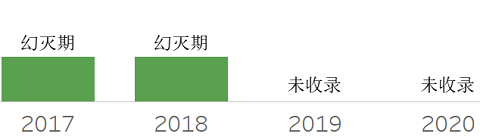
❖ Data as a Service

❖ Data Catalog

数据目录,是一种用来发现、组织、描述数据资产的方法,可方便企业内数据使用者来更好地定位数据集并理解数据含义,从而洞察业务价值。随着企业内数据规模、复杂度的提高(特别是分布式、异构的复杂环境),如何找到并理解数据成为难点,通过数据目录可解决这点。数据目录近些年来有两个发展特点,一是随着机器学习等技术使用数据目录领域,自动化的数据目录能力成为必然,而传统的声明式的数据目录将要过时;二是对非关系的数据源的支持。
Allation;Collibra;IBM;Informatica
❖ Data Classification

数据分类,是将数据“标签化”的过程,这将有利于数据在其生命周期内的被使用和治理。在涉及数据价值、安全、访问、隐私、质量等领域,均可从数据分类中收益。从数据管理角度来看,分类也有助于归档、销毁、风险评估、安全需求等。数据分类的过程,是一个持续的、自适应、自我迭代的过程。
Boldon James;Collibra;Dathena;IBM;
Informatica;Microsoft Netwrix;OpenText;Titus;Varonis
❖ Data Fabric
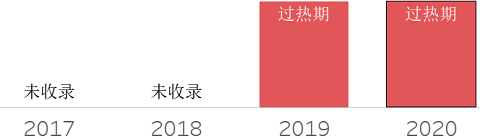
数据组织,是一种新兴的数据管理设计概念,用于获得灵活的、可重用的和增强的数据集成管道、服务和语义,以支持跨多个部署和编排平台交付的各种运营和分析用例。数据结构支持不同数据集成风格的组合,利用元数据、知识图、语义和ML来增强数据集成设计和交付。数据组织,是一种利用现有工具和平台并添加元数据共享、元数据分析和元数据支持的自修复功能以及管理工具来管理环境的设计。随着数据结构变得越来越动态,它会发展为“支持自动数据集成交付”。由于市场上的炒作和对如何交付这些数据的固有困惑,数据结构几乎处于预期膨胀的顶峰。数据结构本身并不是一个可以购买的工具/平台—它是一个设计概念,需要工具、流程和技能集的组合来交付。
Cambridge Semantics;Cinchy;Cluedln;data.world;
Denodo;Informatica;
Semantic Web Company(PoolParty);
Stardog;Talend
❖ Data Hub Strategy

数据总线策略,是将企业的数据应用之于数据共享基础之上。通过建立数据生成者与数据消费者之间的逻辑链接,完成数据的共享。比较典型的例子就是主数据管理。通过建立一个个数据中心,可实现更为有效的数据应用和分析治理,并推动集成工作。随着接入数据消费的终端增多,可获得更多的业务收益,而付出的成本是线性(而非指数级)增长。在初期选择时,可考虑企业内使用最多、最优价值、最为复杂的领域,作为建立总线的起点,因为这样的领域往往收益也最大。注意,其与数据湖、数据仓库的区别,后者更多是数据存储、流转、加工的地点,而非经过有效数据归集、分析治理的场所,后者的目的也不是为了共享而存在。
❖ Data Integration Tool Suites
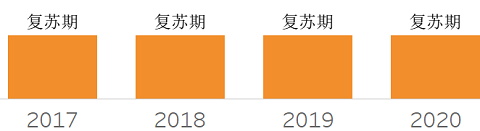
❖ Data Lakes
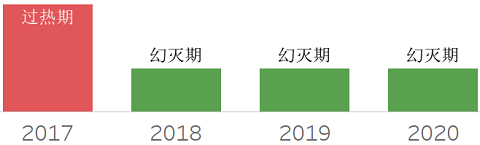
数据湖,可理解为各种原始格式数据的集中存储。这一概念已经兴起多年,但目前公众仍然对数据湖概念不很清晰,其与数据仓库、数据中台的关系如何。很多公司使用数据湖产品后,很难对其产生的ROI做出合理的评估,这也导致后续使用数据湖的犹豫。
Amazon;Cambridge Semantics;Cazena;GCP;
IBM;Informatica;Microsoft;Oracle;Zaloni
❖ Data Prepartion Tools
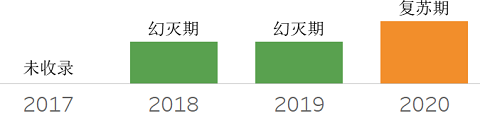
数据准备,是数据发现、数据集成、数据清理过程,为用户准备数据集。是企业以更快洞察力保持持续竞争力的能力要求之一。通过嵌入机器学习算法能力,可减少甚至自动化某些任务,进一步缩短数据准备时间。
Altair;Alteryx;Boomi;DataRobot;Infogix;
Informatica;SAP;SAS;Talend;TrifactaI
❖ Data Quality Tools

❖ Data Virtualization
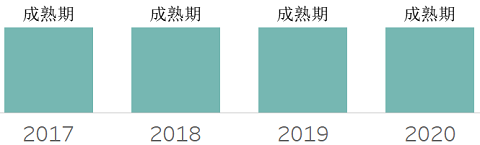
数据虚拟化,指对异构数据源执行查询,将结果缓存在虚拟视图中,应用可使用物理库一样使用结果。其提供屏蔽物理异构数据源的一层抽象。
Data Virauality;Denodo;Dremio;Gluent;
IBM;Informatica;Oracle;TIBCO Software
❖ Database Audit and Protection

数据库审计与保护,是指通过监控数据库用户行为、提供数据库审计日志,进而监测异常活动,发送报警,防止泄露。是对数据安全、隐私保护很重要的能力之一。
Beijing DBSec Technology;DataSunrise;
IBM;Imperva;McAfee;MENTIS;Oracle;SecuPi;
Trustwave;WareValley
❖ Database Encryption
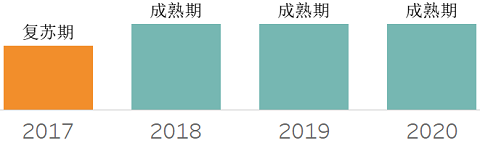
数据加密,保护数据库系统的内对象(行、列、表)及实例。随着数据保护、隐私保护愈发受到关注,为减少数据泄露风险,通过数据保护、执行职责隔离和访问控制来维护隐私,加密变得越来越重要。
eperi;IBM;Micro Focus;NetLib;Oracle;
Penta Security Systems;PKWARE; Protegrity;
Thales eSecurity;Townsend Security
❖ Database Platform as a Service
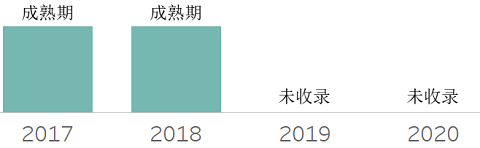
❖ DataOps
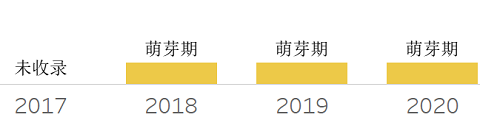
作为一个较新的概念,还没有对DataOps有一个准确的定义。近几年的发展还是在逐步摸索之中。可简单将其类别与“DevOps”,其描述从数据准备、数据集成、数据计算、数据编排及数据应用的方向,通过自助式的、自动化的方式辅助完成。这不是具体某项技术,更多是数据最佳实践过程的一种抽象。
Composable Analytics;Datakitchen;
Delphix;Hitachi Vantara;IBM;Informatica;Nexla;
Saagie;Unravel
❖ Distributed Ledgers
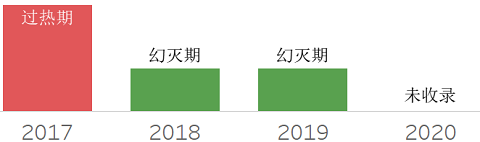
❖ Distributed Transactional Databases

分布式事务数据库,可满足物理分布的多个节点上,实现数据读取与写入,且满足数据完整性和一致性。在网络中断的情况下,数据库必须在向用户提供可用性和冒着失去数据完整性的风险之间做出选择,或者选择加强数据完整性并面临数据库可用性的损失。分布式事务数据库提供了高度的数据完整性,同时通过软件和硬件基础设施的组合最小化了可用性的损失。分布式事务数据库的健壮实现允许在数据库实例的任何分布式节点上执行事务。一些分布式事务系统不允许事务活动的完全透明性,这需要在设计和实现方面做出一些妥协;而有些则对用户交互几乎没有限制。
CockroachDB;FaunaDB;FoundationDB;
Google(Cloud Spanner);NuoDB;RavenDB
❖ Document Store DBMSs
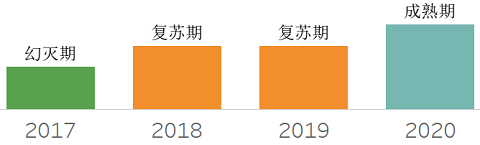
文档数据库,存储缺乏预定义模式的数据。其中文档通常使用JSON自我描述。现在正有更多企业在生产中使用文档库,而文档库自身也在安全、SQL接口、事务等能力逐步增强。
Amazon;Couchbase;GCP;Hibernating Rhinos;IBM;MarkLogic;Microsoft;Mongodb
❖ Enterprise Information Archiving
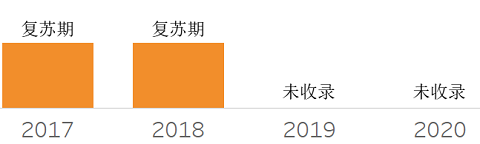
❖ Enterprise Taxonomy and Ontology Management

❖ Event Stream Processing

事件流处理,是针对事件对象进行计算,主要为完成流数据集成及分析场景的。当新鲜活跃数据达到时,需要提供实时的数据感知、分析、预警的能力,事件流处理正解决此类问题。当传统数据库无法满足实时数据需求或者需要针对SaaS应用需要扩展功能时,都可以考虑使用它。
Apache Software Foundation;Confluent;Evam;IBM;
Microsoft;Oracle;SAS;Software AG;
TIBCO Software;Ververica
❖ File Analysis

文件分析,是指对文件的元数据和文件内容进行分析、索引、搜索、跟踪和报告的能力。通过文件分析能力,可对企业中的所谓“暗数据”进行挖掘,对数据治理(数据安全、数据共享)、风险管理(识别个人敏感数据、知识产权数据等)、优化成本(数据重要分层,清理腐化数据)、业务挖掘等均大有好处。随着各类隐私法规的出现,人们对隐私的保护更加重视,文件分析提供了有力的支持。
Active Navigation;Adlib;Condrey;Ground Labs;
Index Engines;SailPoint;Stealthbits Technologies;
Titus;Varonis;Veritas Technologies
❖ Graph DBMSs
图数据库,用来描述数据元素及元素之间的关系的一种数据库。针对某些特定场景(如社交),关系型数据库无法满足,使用图数据库是不错的选择。但图数据库当前的主要问题在于使用上面。用户在使用图数据库建模、计算、分析时,是需要特殊技能,这也带来较高的复杂度,影响了图数据库的普及使用。其突破点是在将图数据库应用在特定领域,通过后者来凸显价值(例如数据治理、血缘分析、财务反欺诈、典型网络分析等)。
Amazon;Cambridge Semantics;DataStax;MarkLogic;
Microsoft;Neo4j;Oracle;TigerGraph
❖ Hadoop Distributions

❖ Hadoop SQL Interfaces
Hadoop SQL接口,通过SQL查询语言访问Hadoop数据。随着Cloudera和Hortonworks的合并,Apache Hive(面向批处理的)和Apache Impala(交互式的)加入了Apache Arrow、Apache Drill、Apache Presto和Apache Spark等,它们都对多个目标文件和DBMS数据有不同程度的支持。但在使用中缺乏处理大规模和/或高并发性的真正复杂查询的能力。诸如基于成本的优化器、索引和复杂的连接技术等功能仍处于开发的早期阶段,不会在所有情况下提供实质性的性能改进。在某些情况下,它们与特定的数据存储配对,例如与Apache Impala一起使用的Apache Kudu。但是,增加多个接口会产生额外的复杂性和锁定性。在用户并发性方面也存在持续的限制。随着数据库产品也逐渐支持访问Hadoop生态数据,Hadoop的SQL接口因此被包含在更广泛的访问工具中,不再是一个单独的类别。AWS;Cloudera;Databricks;Dremio;GCP;
HP;IBM;Microsoft;Oracle;SAP
❖ In-DBMS Analytics
库内分析,是一种将数据密集计算处理(如数据准备、在线分析、预测建模、数据挖掘等)下放在数据库平台,贴近数据,减少移动数据,进而支持快速分析的技术。主流的数据仓库厂商,现在都已支持这种方式的计算。甚至是更为复杂的计算,如R、Python的分析,也是可以在库内支持。未来从数据产生、集成、建模、执行、管理均在同一平台完成,完全可将分析建模的工作转移到库中。
Google;IBM;Micro Focus;Microsoft;Oracle;relationalAl;
RapidMiner;SAP;Teradata;VMware(Pivotal)
❖ Information Stewardship Applications
信息管理应用,是指支持企业数据管理工作的解决方案。这里包括但不限于数据治理的各种活动,例如:数据质量监控、数据模型访问、数据审计跟踪等。这项内容更多是利用已有技术,统一打包提供整体方案。
❖ In-Memory Data Grids
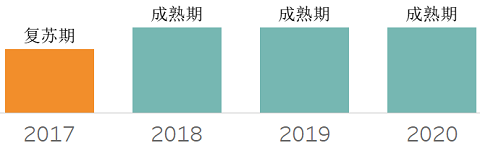
内存数据网格,提供了一个分布式的、可靠的、可扩展的、一致的内存对象存储(数据网格),它可以跨多个分布式应用程序共享。可以在在低延迟数据网格中并发地执行事务和或分析操作,从而大大减少了传统的高延迟存储的使用。这一通过复制、分区和持久存储的持久性来维护数据网格的一致性、可用性和持久性。
GigaSpaces;GridGain;Hazelcast;Oracle;
Red Hat;ScaleOut Software;TIBCO Software;VMware
❖ In-Process HTAP

❖ iPaaS for Data Integration
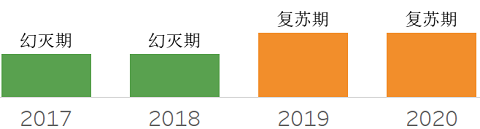
数据集成PaaS化,将数据集成的功能云化,进而支持多种环境下的数据集成需求,例如在云数据集成、多云数据、本地数据、企业间数据、边缘数据及上述混合部署情况。企业数字化转型,带来了数据集成策略的复杂性,iPaaS化降低了使用难度,适用于更多场景。
DBSync;Dell Boomi;Etlworks;Informatica;Jitterbit;
Oracle;SAP;SnapLogic;Talend;TIBCO Software
❖ Key-Value DBMSs
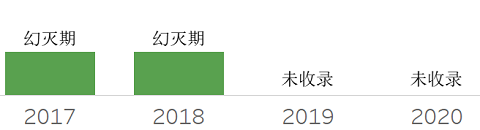
❖ Ledger DBMS
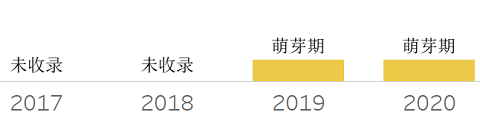
“总账”数据库,是一种仅支持数据追加、不可改变、天然具备加密及审计能力的数据库。其与区块链不同,其不需要分布式共识机制,可通过单一实体来控制,并指定其他用户访问它、追加它。它避免了区块链平台由于分布式所带来的天然复杂性,而使得它使用起来更加容易、安全、性能更佳。这一技术尚在早期阶段,推出的产品也非常的少。相对有名的如Amazon的QLDB,已经推出多年。相信在未来将有更多的产品不断涌现。近期传统数据库的代表-Oracle,在其最新的20c版本中也推出了名为BlockChain Table。
AWS;Fauna;Fluree;Oracle
❖ Logical Data Warehouse
逻辑数据仓库,它将多个物理分析引擎组合成一个逻辑集成的整体。现代的数据分析工作需要支持多种类型数据,多种分析处理技术,使用逻辑数仓可以集成多种技术能力来满足这些需求,同时提供统一视图。这对增强企业敏捷性,提高投资回报比均有好处。Amazon;Cloudera;Databricks;Denodo;IBM;Microsoft;Oracle;Snowflake;Teradata;VMware(Pivotal)
❖ Machine Learning-Enabled Data Management

❖ Machine Learning-Enabled Data Quality
❖ Master Data Management
主数据管理,是描述企业内核心实体数据的一种技术,是企业业务决策的核心。其描述的准确性、一致性、可靠性,对于企业更好地满足业务发展、响应变化、打破业务竖井等均有意义。但建设主数据的过程,是一个复杂而艰难的任务,仅仅依靠技术本身不足以成功,还需要组织、流程等协助。
Ataccama;IBM;Informatica;Profisee;Reltio;
Riversand Technologies;SAP;Semarchy;
Stibo Systems;TIBCO Software
❖ Metadata Management Solutions
元数据,描述信息的各个方面,在企业中数据治理、安全风险、隐私保护、数据分析和价值挖掘领域发挥了重要作用。元数据管理方案,则是针对元数据使用的具体方面进行管理。随着新时期的变化,利用机器学习等技术,将元数据从静态存储到动态产生,可以更好地适应现有情况;同时也有助于消除传统方案的的孤岛现象。
Alation;Alex Solutions;ASG;Collibra;erwin;
IBM;Infogix;Informatica;Oracle;SAP
❖ Multimodel DBMSs
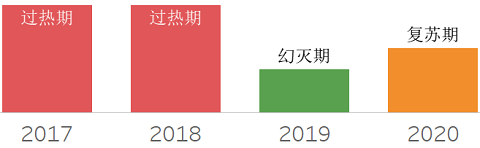
多模数据库,在单一平台上支持多种类型(例如文档、键值、图、时序、宽列)数据的存储,并提供通用的访问机制。这种方式降低了用户使用复杂度(简化开发、集成、管理需求)。此类产品的难点在于生态,即有多少用户愿意按这种方式使用数据库,而不是选择专有的产品。
AWS;DataStax Enterprise;
EnterpriseDB;GCP;IBM;MarkLogic;
Microsoft;MongoDB;Oracle;SAP
❖ Operational In-Memory DBMS
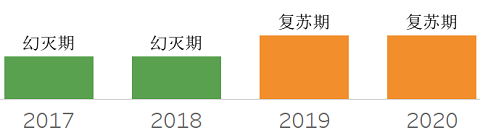
操作型内存数据库,所有必要的数据均保存在内存中,相关增删改查的操作也在内存中完成。这一技术面临两个痛点,一是成本,二是易失性。这两点正通过英特尔傲腾技术及内存价格的降低,而部分解决。主要场景是在HTAP(操作与分析混合)、人工智能与机器学习、实时事件处理等场景使用。
Aerospike;IBM;MemSQL;Microsoft;Oracle;Redis Labs;SAP;VoltDB
❖ Point-of-Decision HTAP
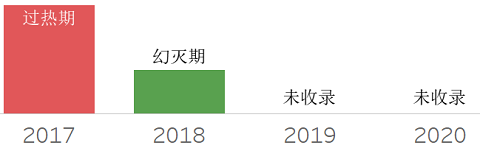
❖ Private Cloud dbPaas
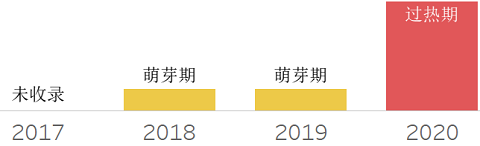
私有云数据库平台,提供一种类似公有云类似的云数据库服务能力。它提供了自服务、可伸缩、弹性、多租户等云端能力,区别在于仅在内部使用。可以作为企业私有云框架的一部分部署和管理。对于那些基于安全、监控考虑或其他原因无法使用公有云的用户,很具有吸引力。在评估中需关注一下这些点:
支持用户所需的所有数据库种类
支持弹性的、可持久的存储层
支持按需付费的计费能力
可实现资源弹性(包括ScaleUP、ScaleOut)
核心能力(高可用、容灾能力)
断网离线操作能力
Alibaba Cloud Apsara Stack;AWS Outposts;
GCP(Anthos);IBM;Microsoft Azure Stack;
OpenStack;Oracle Cloud at Customer;
Robin;VMware
❖ SaaS Archiving of Messaging Data
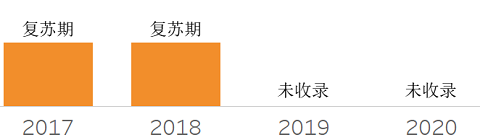
❖ Self-Service Data Preparation

❖ Spark
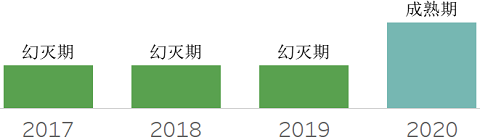
Spark,用于大规模数据处理和分析的开源内存分布式计算框架。经过多年发展,其已逐步成熟,成为某种意义上的事实标准。
Amazon;Cloudera;Databricks;GCP;IBM;Azure
❖ SQL Interfaces to Cloud Object Stores
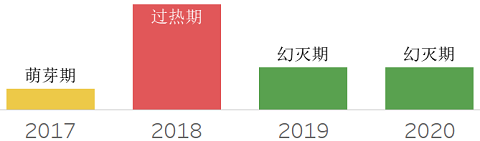
对象存储SQL接口,是指通过SQL接口访问云存储中的对象数据。与块存储不同,对象存储是将数据作为对象处理,而不是在更为底层的磁道、扇区处理。其非常适合保存大量多结构化数据,常见用来支持数据湖应用。之前人们通常使用SQL on Hadoop的方案,现在已逐步转向对象存储SQL接口方式。其原因是在于后者更好地利用云存储,提供了廉价的数据存储能力。包括常见的Amazon S3、Azure Blob Storge、GCP的云存储等。在SQL接口产品上,包括Amazon Athena、Amazon Redshift Spectrum、Apache Spark、Starburst、Cloudera Impala、Google BigQuery、Microsoft Azure Data Lake Analyze等。此外,一些RDBMS和Hadoop产品也通过外表方式支持访问对象存储。目前这一技术的问题,主要在于SQL标准型,其具体行为还是与标准SQL有一定差异。
AWS;Apache Software Foundation;
Cloudera;Databricks;GCP;IBM;Microsoft Azure;
Snowflake;Starburst;Varada
❖ Time Series DBMS

时序数据,旨在处理时间序列上的数据,包括活动窗口内的明细数据以及在活动窗口之外的历史数据聚合类操作。这一技术最初是为金融服务,后随着IOT技术出现,而受到广泛关注。
AWS;IBM;InfluxData;Machbase;Microsoft;
OpenTSDB;Redis Labs
❖ Wide-Column DBMSs
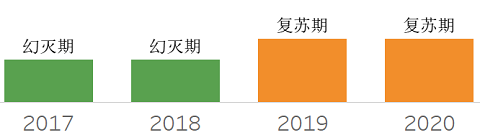
宽表,支持灵活模式定义,通常没有关联,适合存储大数据了的半结构化数据。一般在分布式,对数据没有强事务要求的场景使用。
Alibaba Cloud;AWS;Cloudera;DataStax;GCP;
HP; Microsoft Azure;ScyllaDB
4. 附录:近几年Hype Cycle报告
附上近几年的Hype Cycle报告,供参考。
2017年报告
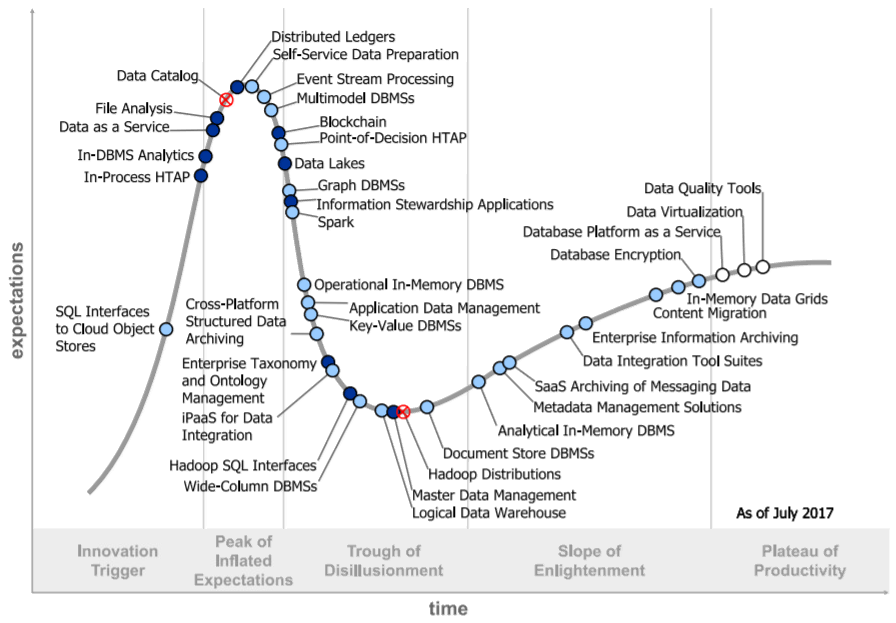
2018年报告
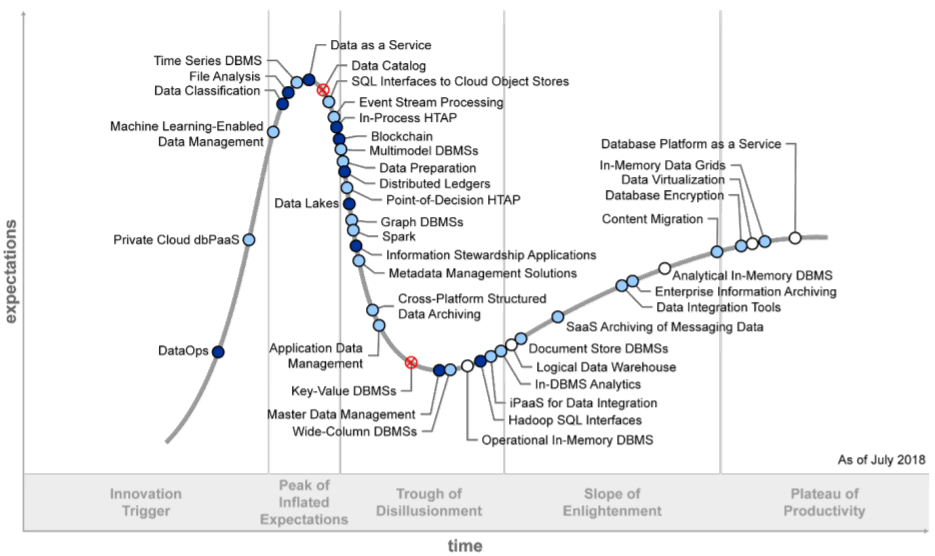
2019年报告
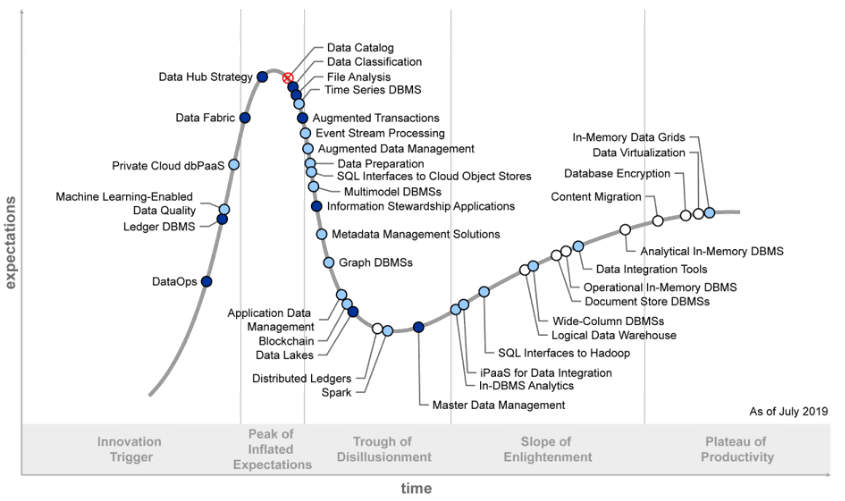

韩锋频道:
关注技术、管理、随想。
长按扫码可关注
