




LF Edge eKuiper(以下简称 eKuiper)是 Golang 实现的轻量级物联网边缘分析、流式处理开源软件,可以运行在各类资源受限的边缘设备上。
eKuiper 设计的一个主要目标就是将在云端运行的实时流式计算框架 (如 Apache Spark、Apache Storm、Apache Flink) 迁移到边缘端。eKuiper 参考了上述云端流式处理项目的架构与实现,结合边缘流式数据处理的特点,采用了编写基于源 (Source)、SQL (业务逻辑处理)、目标 (Sink) 的规则引擎来实现边缘端的流式数据处理。
eKuiper 项目填补了边缘端实时计算的空白,在工业物联网、车联网等领域得到了越来越广泛的应用。根据 GitHub、微信群、论坛等多个渠道收集到的大量用户反馈,我们对 eKuiper 的易用性和可靠性进行了持续提升,并于近日正式发布了 1.5.0 版本(https://github.com/lf-edge/ekuiper/releases/tag/1.5.0)。
本次更新主要亮点有:
SQL 改进:用于定义数据流和分析规则的 eKuiper 核心功能 SQL 提供了包括变化检测函数以及 object_construct 函数等在内的更多内置函数,提升了表达能力;
生态连接:提供内置的 Neuron 连接支持,可以轻松处理 Neuron 生态中的数据;同时通用的 SQL 插件可以接入多种传统 SQL 数据库,一定程度上实现批数据的流式处理。
运维和文档改进:规则运行时稳定性提升,支持按需编译。文档的导航结构重构,阅读体验和查询效果提升。
社区站网址:
https://ekuiper.org/zh
GitHub 仓库:
https://github.com/lf-edge/ekuiper
Docker 镜像地址:
https://hub.docker.com/r/lfedge/ekuiper
各种 source/sink 是 eKuiper 连接数据处理生态的途径。新版本中,eKuiper 添加了更多的连接类型 Neuron 和 SQL。同时我们也改进了原有连接,例如 TDEngine sink 中添加了超级表的支持。
Neuron(https://github.com/emqx/neuron)是一个EMQ 发起并开源的工业物联网(IIoT)边缘工业协议网关软件,用于现代大数据技术,以发挥工业 4.0 的力量。它支持对多种工业协议的一站式访问,并将其转换为标准 MQTT 协议以访问工业物联网平台。
Neuron 和 eKuiper 整合使用,可以方便地进行 IIoT 边缘数据采集和计算。
在之前的版本中,Neuron 与 eKuiper 之间需要采用 MQTT 作为中转。二者协同时,需要额外部署 MQTT Broker。同时,用户需要自行处理数据格式,包括读入和输出时的解码编码工作。
Neruon 2.0 版本与 eKuiper 1.5.0 版本将无缝整合,用户无需配置即可在 eKuiper 中接入 Neruon 中采集到的数据,进行计算;也可以方便地从 eKuiper 中反控 Neuron 。
两个产品的整合,可以显著降低边缘计算解决方案的部署成本,简化使用门槛。使用 NNG 协议,使用进程间通信,也可显著降低网络通信消耗,提高性能。
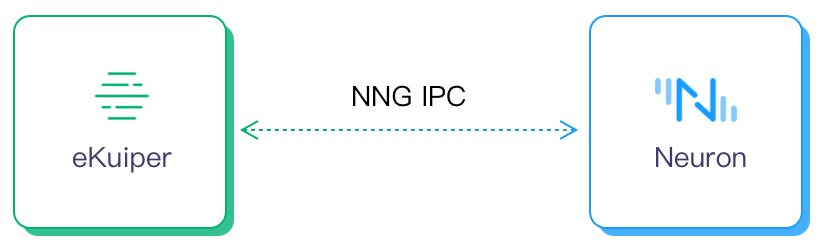
用户接入 Neuron 时,只需要在 eKuiper 中创建一个类型为 Neuron 的流:
CREATE STREAM demo() WITH (TYPE="neuron",SHARED="TRUE")
反控 Neuron 时,需要在规则的动作里添加 Neuron 动作,指定需要写入的组名,节点名和 tag 名(均可为动态属性)。eKuiper 将会自动转换格式,适配 Neuron 的输入格式。
"neuron": {"nodeName": "{{.node}}","groupName": "grp","tags": ["tag0"]}
详细信息,请参考以下文档:
https://ekuiper.org/docs/zh/latest/rules/sources/builtin/neuron.html
https://ekuiper.org/docs/zh/latest/rules/sinks/builtin/neuron.html
SQL 拉取源提供了一种批量数据转为流式数据的方式,使得 eKuiper 支持初步的流批一体处理的方式。
在旧的系统升级改造过程中,我们往往还需要考虑对原有系统的兼容。大量的老旧系统采用传统关系数据库存储采集的数据。在新的系统中,可能也有保存在数据库中,不方便提供流式接入的数据却需要进行实时计算的数据。还有更多的场景需要接入形形色色数量庞大的支持 SQL 的数据库或其他外部系统。
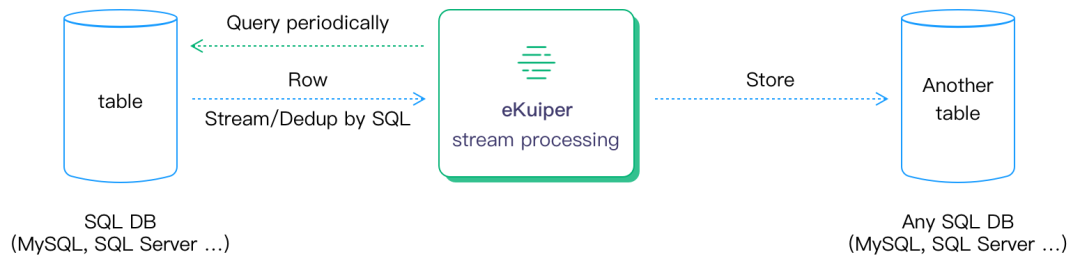
eKuiper 提供了统一的\多数据库通用的 SQL 拉取 source,可定时拉取支持 SQL 的数据源的数据,并提供基础的去重能力,形成流式数据进行统一的流式计算处理。
该插件的预编译版本支持 MySQL、PostgresSQL 等常见数据库的接入;同时插件中搭载了几乎所有常见数据库的连接能力,用户只需要在编译时提供所需支持的数据库的参数,即可自行编译支持自定义数据库类型的插件。
除了数据拉取,我们也提供了数据写入的通用 SQL 插件。
需要注意的是,eKuiper 本身已经提供了针对 InfluxDB、TDengine 等时序数据库的专用插件。通用 SQL 插件同样可以支持连接这些数据库,但提供的是 insert 功能,不支持特定数据库的非标准概念,例如 TDengine 的超级表只能使用 TDengine 插件进行写入。
更多信息以及支持的数据库列表,请参见以下文档:
https://ekuiper.org/docs/zh/latest/rules/sources/plugin/sql.html
https://ekuiper.org/docs/zh/latest/rules/sinks/plugin/sql.html
内置函数是 SQL 完成各种计算的主要组织形式,也是 SQL 表达能力的重要来源。新版本中的 SQL 改进主要通过添加新的函数来实现。
新的版本中添加了三个通用的变化检测相关函数:CHANGED_COLS,CHANGED_COL 和 HAD_CHANGED 。
CHANGED_COLS 函数的作用是检测指定的列是否发生变化,如果发生变化,则返回变化的列的值,否则不返回。
在变化检测的场景中,用户经常需要检测多个列/表达式,而且数量不固定。因此,该函数可接收不定数量的参数,同时其返回值为多个列。
相比于普通的标量函数固定返回单一结果列(多列结果会被包含在 map 中),这是第一个返回多列的函数,我们对函数的实现进行了重构以实现多列函数的支持。该函数的参数个数是可变的,同时列的参数也可以是别的表达式。列参数也支持 * 号,表示检测所有列,例如 SELECT CHANGED_COLS("c_", true, *) FROM demo
。
多列函数仅可在 Select 子句中使用,其选出的值不能用于 WHERE 或其他子句中。若需要根据变化值做过滤,可以使用 CHANGED_COL 函数获取变化后的值做为过滤条件;或者使用 HAD_CHANGED 函数获取多个列的变化状态作为过滤条件。
详细信息和使用示例,请参考文档:
https://ekuiper.org/docs/zh/latest/sqls/built-in_functions.html#监控变化的函数
规则的 SQL 语句中 select 选择出的所有列会组成一个对象,供 sink 插件和下游的应用进行处理。
在有些场景中,下游应用需要对选择的列进行分组,然后灵活地对每个分组进行处理。例如,把选择出来的结果分成多个 key/value 集合,其中 key 为文件名,这样可以动态地把结果写入到多个文件中。
新的内置方法 object_construct 可以轻松实现列的分组和命名。其语法为 object_construct(key1, col, ...),可支持多个参数,并返回由参数构建的对象 。参数为一系列的键值对,因此必须为偶数个。键必须为 string 类型,值可以为任意类型。例如,用户需要把列 1,2,3 写入到文件 1;而列 4,5 写入到文件 2 中。则可使用一条 SQL 规则对列进行分组,并对组名进行赋值:
SELECT object_construct("key1", col1, "key2", col2, "key3", col3) AS file1, object_construct("key4", col4, "key5", col5) AS file2 FROM demoStream
其输出结果形如下列 JSON 对象:
{"file1":{"key1":"aValue","key2":23,"key3":2.5},"file2":{"key4":"bValue","key5":90}}
新的版本在运维方面的主要改进包括提升了运行时的稳定性,提供了方便的编译参数方便用户根据需求进行软件功能的裁剪以适应更小算力的设备。
新的版本中,我们对规则运行和生命周期进行了优化和重构,增加了规则运行的稳定性,提高规则之间的隔离性。主要表现在以下几个方面:
规则错误隔离:即使是使用共享源的规则,某个规则的运行时错误也不会影响另外的相关规则。同时,新版本的规则系统级的 panic 错误也会在规则级别进行处理,不再导致整个 eKuiper 进程崩溃。
规则负载隔离:使用共享源或者内存源的兄弟规则之间,在保持消息顺序的同时,消息流入吞吐量不受其他规则的影响。
作为边缘流式处理引擎,需要部署的异构目标系统很多,既有算力较好的边缘端的机房、网关等,也有出于成本以及业务的特殊要求考虑而采用成本更便宜或是定制化的软硬件方案。
随着功能的逐渐增强,全功能的 eKuiper 在极端资源受限的设备上,例如内存少于 50MB 的终端上,可能会稍显臃肿。
新的版本中,我们将 eKuiper 的核心功能和其他功能通过 go 语言的编译标签进行剥离。用户在使用的时候,可以通过设置编译参数的方式,按需编译部分功能,从而得到更小的运行文件。例如,仅编译核心功能,可使用 make build_core 得到一个只包含核心功能的运行文件。
详细信息,请参考:
https://ekuiper.org/docs/zh/latest/features.html
在 4 月上线的官网(https://ekuiper.org)中,eKuiper 文档进行了目录结构的重构,并编译到文档网站上。
新的文档网站增加了概念介绍、教程等模块,调整了导航树,希望能帮助用户更方便地找到有用的信息。
eKuiper 的版本迭代会尽量保持新旧版本的兼容,新的版本也不例外。升级到 1.5.0 版本,大部分功能无需改动即可平稳升级,但是有两处改动需要用户手动更改:
Mqtt source 的服务器配置项由 servers 改成 server,配置值由数组改为字符串。用户的配置文件 etc/mqtt_source.yaml 中需要进行更改。若使用环境变量,例如Docker 启动和 docker compose 文件启动等,需要更改环境变量:MQTT_SOURCE__DEFAULT__SERVERS =》 MQTT_SOURCE__DEFAULT__SERVER 。Docker 启动的命令更改为
docker run -p 9081:9081 -d --name ekuiper MQTT_SOURCE__DEFAULT__SERVER="$MQTT_BROKER_ADDRESS" lfedge/ekuiper:$tag
。若使用 Tdengine sink, 其属性名 ip 改为 host , 属性值必须为域名。
为了让大家能够快速且直观地了解 eKuiper 1.5.0 的新特性,在 5月26日(本周四) 20:00 的 EMQ Demo Day 中,eKuiper 团队将为大家演示 eKuiper 和 Neuron 的整合、变化检测、通用 SQL 插件以及按需编译等特性。
扫描下方二维码即可免费报名:

开源之夏是由「开源软件供应链点亮计划」发起并长期支持的一项暑期开源活动,旨在鼓励在校学生积极参与开源软件的开发维护,培养和发掘更多优秀的开发者。
作为开源项目,LF edge eKuiper 也参加了今年的开源之夏活动,并开放了两个项目。其中,流式计算窗口函数优化探索项目涉及通用的流式处理知识和前沿研究方向,是以实战方式深入了解流式处理的硬核项目。而 WASM 函数扩展项目侧重于 eKuiper 的生态扩展,上手比较容易,有助于了解时下较为热门的 WASM 技术在边缘侧的应用。
关于本届开源之夏的更多信息请查看:开源集结令!参与开源之夏 EMQ 项目开发,赢最高 12000 元奖金!
期待大家的参与!
关注本公众号并回复关键字:
【0401】- 加入 eKuiper 技术交流社群
【0402】- eKuiper 快速上手
【0403】- 参与 eKuiper 社区周会

