




2022年4月21日,Aurora Serverless V2 正式发布 ,适用于 MySQL 8 和 PostgreSQL,具有克服 V1 缺点的有希望的功能。以下是这些主要功能:
特征
- 在线自动实例升迁(垂直扩展)
- 读取扩展(最多支持 15 个只读副本)
- 支持混合配置集群,即master可以是普通的Aurora(provisioned),reader可以是serverlessv2,反之亦然
- 多可用区功能 (HA)
- Aurora 全局数据库 (DR)
- 基于内存压力的缩放
- SQL 运行时垂直缩放
- 允许公共 IP
- 与自定义端口一起使用
- 与 Aurora 版本 3.02.0 兼容,即 >= MySQL 8.0.23(仅支持)
- 支持二进制日志
- 支持 RDS 代理。
- 高成本节约
现在让我们开始着手为 MYSQL 启动 serverless-v2
启动无服务器 V2
是时候选择启动我们的无服务器 v2 的引擎和版本了
引擎类型 :亚马逊极光
版本 :Amazon Aurora MySQL – 兼容版本(仅使用 MySQL)
过滤器 :打开显示支持 ServerlessV2 的版本(节省时间)
版本 :Aurora MySQL 3.02.0(兼容 MySQL 8.0.23)

实例配置和可用性
数据库实例类 :无服务器“无服务器 v2 – 新”
容量范围 :根据您的要求和成本设置(1 到 64 个 ACU)
Aurora 容量单位(ACU):2GB RAM+ CPU + N/W
可用性和耐用性 :创建 Aurora 副本

在选择容量范围时,Minimum ACU 将定义它缩小到的最低容量,即 1ACU,Maximum ACU 将定义它可以放大到的最大容量
连接和其他设置:
根据您的应用需求选择以下设置
- 专有网络
- 子网
- 公共访问,(避免有利于基本安全)
- VPC 安全组
- 附加配置(集群组、参数组、自定义数据库端口、性能洞察、备份配置、自动小版本升级、删除保护)
为了简短起见,我接受了所有默认设置以继续“创建数据库”


单击“创建数据库”后,您可以看到集群已创建,最初集群中的两个节点都将标记为“Reader instance”——不要惊慌,这很正常。

一旦第一个实例可用,它将被提升为“写入器”,现在集群已准备好接受连接,读取器在相邻 AZ 中创建的帖子,参考下图

连接和端点:
ServerlessV2 集群还提供了 3 个端点,即高可用集群、只读端点和单个实例端点
- 集群终端节点– 此终端节点将您的应用程序连接到该无服务器 v2 集群的当前主数据库实例。您的应用程序可以执行读取和写入操作。
- 读取器端点——无服务器 v2 集群有一个内置读取器端点,仅用于只读连接。这还可以平衡多达 15 个只读副本实例的连接。
- 实例端点——无服务器 v2 集群中的每个数据库实例都有自己唯一的实例端点
您应该始终将集群和 RO 端点与应用程序映射以实现高可用性
监控:
尽管 Cloudwatch 涵盖了所需的指标,但为了使用 PMM 深入了解 DB 行为,我使用此链接进行快速安装,简而言之,无服务器我想查看以下内容
- 数据库正常运行时间,查看数据库是否在扩展或缩减期间重新启动
- 连接失败
- 内存调整大小(InnoDB 缓冲池)
这里我拿了一台 T2.large 机器来安装和配置 PMM。

现在让我们来看看 Serverlessv2:
Aurora Serverless V2 的美妙之处在于它支持垂直扩展,即自动实例升迁以及具有只读副本的水平扩展。
在本博客的剩余部分中,将介绍 Serverless V2 的垂直扩展特性。
垂直缩放:
对于大多数集群来说,最困难的部分是在不中断现有连接的情况下即时升级编写器实例。即使使用代理/DNS 进行故障转移,也会出现连接失败。
我对垂直扩展功能的测试更加好奇,因为 AWS 声称它是在线的并且不会中断现有的连接连接,即在查询运行时。哇 !!手指交叉。
来吧让我们开始测试,所以我决定先删除“阅读器实例”,下面是我们现在集群的视图。

我的初始缓冲池分配是 672MB,因为我们的最小值 (1ACU) 我们有 2GB,其中 ¾ 分配为 InnoDB-buffer-pool

测试用例:
测试用例非常简单,使用简单的负载仿真器工具 Sysbench 施加仅插入工作负载(写入)
下面是使用的命令
# sysbench /usr/share/sysbench/oltp_insert.lua --threads=8 --report-interval=1 --rate=20 --mysql-host=mydbops-serverlessv2.cluster-cw4ye4iwvr7l.ap-south-1.rds.amazonaws.com --mysql-user=mydbops --mysql-password=XxxxXxXXX --mysql-port=3306 --tables=8 --table-size=10000000 prepare我开始使用 8 个线程并行加载 8 个表和每个表 1M 记录的数据集
观察和时间表:
放大:
以下是我在放大过程中的观察
- 插入在 03:57:40 开始,正好COM_INSERTS达到 12.80/秒,Serverless 以 672MB 的 buffer_pool 运行,恰好在 3:57:40 10 秒后,第一次缩放过程开始,buffer_pool 内存增加到 2GB,让我们仔细看看

- 在 03:58:40 的一分钟后,第二个扩展过程开始,buffer_pool 大小跃升至 ~9G

- 我一直在密切关注 MySQL 的每个扩展过程的正常运行时间,也观察线程故障,但令我惊讶的是,两者都完好无损,内存(缓冲池)以 60 秒的定期间隔线性扩展,最大达到 60GB 04:11:40
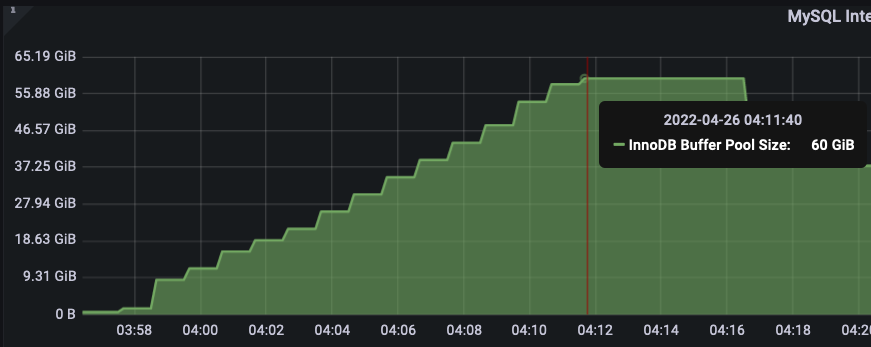
- 数据加载于 04:10:50 完成(图形统计)

缩小:
- 在 DB 中完成插入后,有一个短暂的 5 分钟时间,因为在生产中必须以缓慢而稳定的方式缩小规模。DB 现在完全空闲,连接已关闭,在 04:16:40 缓冲池内存从 60G 下降到 48GB

- 缩减过程从上一次缩减操作开始每隔 3 分钟定期启动,最后在 04:34:40 无服务器又回来了

自适应放大和缩小
我想说整个放大和缩小的过程是非常适应的、智能的、组织良好的
- 数据库性能没有滞后。
- 保持资源的线性增加和减少
- 没有数据库重新启动和连接失败被阻止
下面是 buffer_pool 内存扩展和缩减过程的完整快照以及 INSERT 吞吐量统计信息,这两个过程都花费了大约 40 分钟
除了 buffer_pool 无服务器还自动调整以下特定于 MySQL 的变量
innodb_buffer_pool_size
innodb_purge_threads
table_definition_cache
table_open_cache
AWS 建议在 serverlessV2 的自定义参数组中将此值保持为默认值
下面是整个放大和缩小过程的图像摘要。

AWS 已经通过 aurora serverless 实现了垂直扩展,从我的角度来看,它的生产虽然处于早期 GA 阶段。
概括:
- Upsize 每 1 分钟按需逐渐发生。
- 每 3 分钟在理想负载下逐渐缩小尺寸。
- 来自 MySQL 8.0.23 的支持
- Untouch上面说的MySQL变量
用例:
以下是 Aurora serverless V2 非常适合的一些用例
- 应用程序,例如游戏、零售应用程序和在线赌博应用程序,其中在已知时间段内(例如白天或比赛期间)使用率很高,而在其他时间段内空闲或使用较少
- 适用于测试和开发环境
- 负载不可预测的多租户应用程序
- 批处理作业
这只是一个起点,在 Aurora ServerlessV2 上还有很多未决的对话,例如水平扩展(读取扩展)、迁移、参数、DR、MutiAZ 故障转移和定价。请继续关注这里!!
文章来源:https://mydbops.wordpress.com/2022/05/22/exploring-aurora-serverless-v2-for-mysql/
