




原文作者 Jun G核心 ·xiaofan luan · 22年3月17日 · 数据库专区 · 教程
原文地址https://dzone.com/articles/building-a-vector-database-for-scalable-similarity
博客系列中的第一篇,详细介绍了构建最流行的开源矢量数据库背后的思维过程和设计原则。

据统计,全球约80%-90%的数据是非结构化的。在互联网快速发展的推动下,预计未来几年非结构化数据将出现爆炸式增长。因此,公司迫切需要一个功能强大的数据库,以帮助他们更好地处理和理解此类数据。然而,开发数据库总是说起来容易做起来难。本文旨在分享构建用于可扩展相似性搜索的开源云原生向量数据库 Milvus 的思考过程和设计原则。本文还详细讲解了 Milvus 架构。
非结构化数据需要完整的基本软件堆栈
随着互联网的发展和发展,非结构化数据变得越来越普遍,包括电子邮件、论文、物联网传感器数据、Facebook 照片、蛋白质结构等等。为了让计算机理解和处理非结构化数据,这些数据使用嵌入技术转换为向量。
Milvus 对这些向量进行存储和索引,并通过计算它们的相似距离来分析两个向量之间的相关性。如果两个嵌入向量非常相似,则意味着原始数据源也相似。
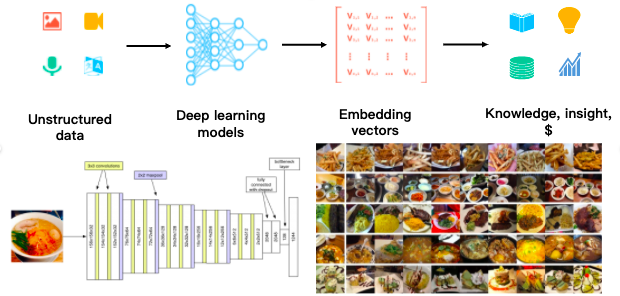
处理非结构化数据的工作流程。
向量和标量
标量是仅在一次测量中描述的量 - 幅度。标量可以表示为数字。例如,一辆汽车以 80 公里/小时的速度行驶。在这里,速度(80km/h)是一个标量。同时,向量是在至少两个测量值(幅度和方向)中描述的量。如果汽车以 80 公里/小时的速度向西行驶,这里的速度(向西 80 公里/小时)是一个向量。下图是常见标量和向量的示例。

标量和向量。图片来源:美国宇航局格伦研究中心。
由于大部分重要数据都具有多个属性,因此将它们转换为向量可以更好地理解这些数据。我们处理向量数据的一种常见方法是使用欧几里得距离、内积、谷本距离、汉明距离等度量来计算向量之间的距离。距离越近,向量越相似。为了有效地查询海量矢量数据集,我们可以通过在矢量数据上建立索引来组织矢量数据。对数据集编制索引后,可以将查询路由到最有可能包含与输入查询相似的向量的集群或数据子集。
要了解有关索引的更多信息,请参阅向量索引。
从矢量搜索引擎到矢量数据库
从一开始,Milvus 2.0 的设计目的就不仅仅是作为一个搜索引擎,更重要的是作为一个强大的矢量数据库。
帮助您理解此处差异的一种方法是在InnoDB和MySQL或Lucene和Elasticsearch之间进行类比。
与 MySQL 和 Elasticsearch 一样,Milvus 也建立在Faiss、HNSW、Annoy等开源库之上,专注于提供搜索功能并确保搜索性能。然而,将 Milvus 降级为 Faiss 之上的一层是不公平的,因为它存储、检索、分析向量,并且与任何其他数据库一样,还为 CRUD 操作提供标准接口。此外,Milvus 还具有以下功能:
- 分片和分区
- 复制
- 灾难恢复
- 负载均衡
- 查询解析器或优化器
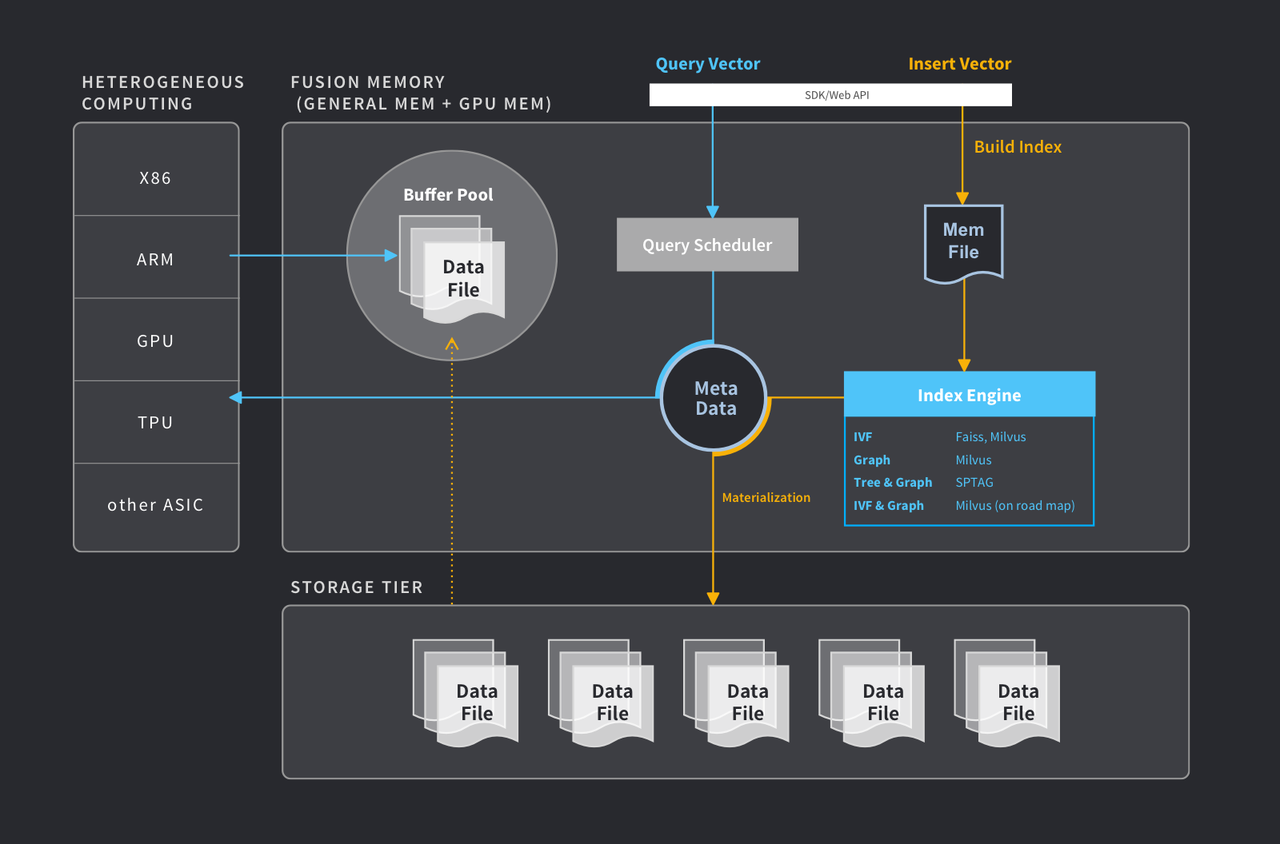
要更全面地了解什么是矢量数据库,请阅读此处的博客。
云原生优先方法
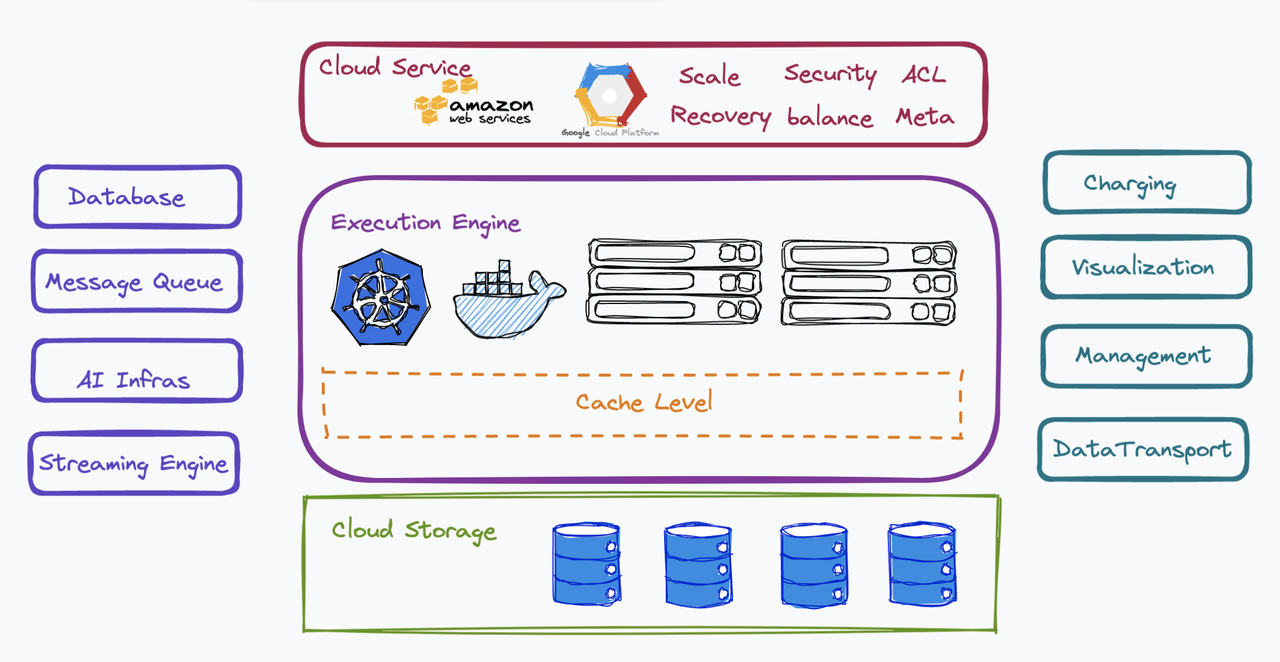
云原生方法。
从无共享到共享存储,再到共享某些东西
传统数据库过去采用“无共享”架构,分布式系统中的节点相互独立,但通过网络连接。节点之间不共享内存或存储。然而,Snowflake通过引入计算(查询处理)与存储(数据库存储)分离的“共享存储”架构彻底改变了行业。通过共享存储架构,数据库可以实现更高的可用性、可扩展性并减少数据重复。受到 Snowflake 的启发,许多公司开始利用基于云的基础架构来实现数据持久性,同时使用本地存储进行缓存。这种类型的数据库架构被称为“共享的东西”,已经成为当今大多数应用程序中的主流架构。
除了“共享的东西”架构之外,Milvus 还支持每个组件的灵活扩展,使用 Kubernetes 管理其执行引擎,并通过微服务分离读取、写入和其他服务。
数据库即服务 (DBaaS)
数据库即服务是一个热门趋势,因为许多用户不仅关心常规的数据库功能,而且渴望更多样化的服务。这意味着我们的数据库除了传统的CRUD操作之外,还要丰富它可以提供的服务类型,比如数据库管理、数据传输、计费、可视化等。
与更广泛的开源生态系统的协同作用
数据库开发的另一个趋势是利用数据库和其他云原生基础设施之间的协同作用。就 Milvus 而言,它依赖于一些开源系统。例如,Milvus 使用etcd来存储元数据。它还采用消息队列,一种用于微服务架构的异步服务到服务通信,可以帮助导出增量数据。
未来,我们希望将 Milvus 构建在Spark或Tensorflow等 AI 基础设施之上,并将 Milvus 与流引擎集成,从而更好地支持统一流和批处理,以满足 Milvus 用户的各种需求。
Milvus 2.0的设计原则
Milvus 2.0 作为我们的下一代云原生矢量数据库,围绕以下三个原则构建。
记录为数据
数据库中的日志连续记录对数据所做的所有更改。如下图所示,从左到右分别是“旧数据”和“新数据”。并且日志是按时间顺序排列的。Milvus 有一个全局定时器机制,分配一个全局唯一且自动递增的时间戳。
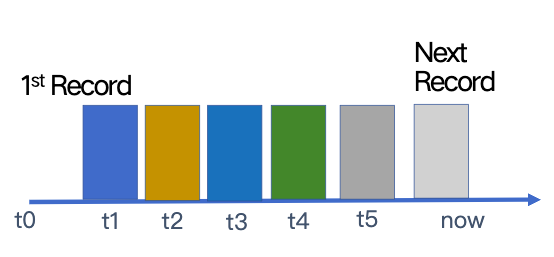
登录数据库。
在 Milvus 2.0 中,日志代理作为系统的骨干:所有的数据插入和更新操作都必须经过日志代理,工作节点通过订阅和消费日志来执行 CRUD 操作。
表和日志的对偶性
表和日志都是数据,只是两种不同的形式。表是有界数据,而日志是无界的。日志可以转换成表格。对于 Milvus,它使用 TimeTick 的处理窗口聚合日志。根据日志顺序,将多条日志聚合成一个小文件,称为日志快照。然后将这些日志快照组合成一个segment,可以单独用于负载均衡。
日志持久性
日志持久性是许多数据库面临的棘手问题之一。分布式系统中日志的存储通常依赖于复制算法。
与Aurora、HBase、Cockroach DB和TiDB等数据库不同,Milvus 采用了一种突破性的方法,引入了发布-订阅(pub/sub)系统来进行日志存储和持久化。发布/订阅系统类似于Kafka或Pulsar中的消息队列。系统内的所有节点都可以使用日志。在 Milvus 中,这种系统称为日志代理。多亏了日志代理,日志与服务器解耦,确保 Milvus 本身是无状态的,并且能够更好地从系统故障中快速恢复。
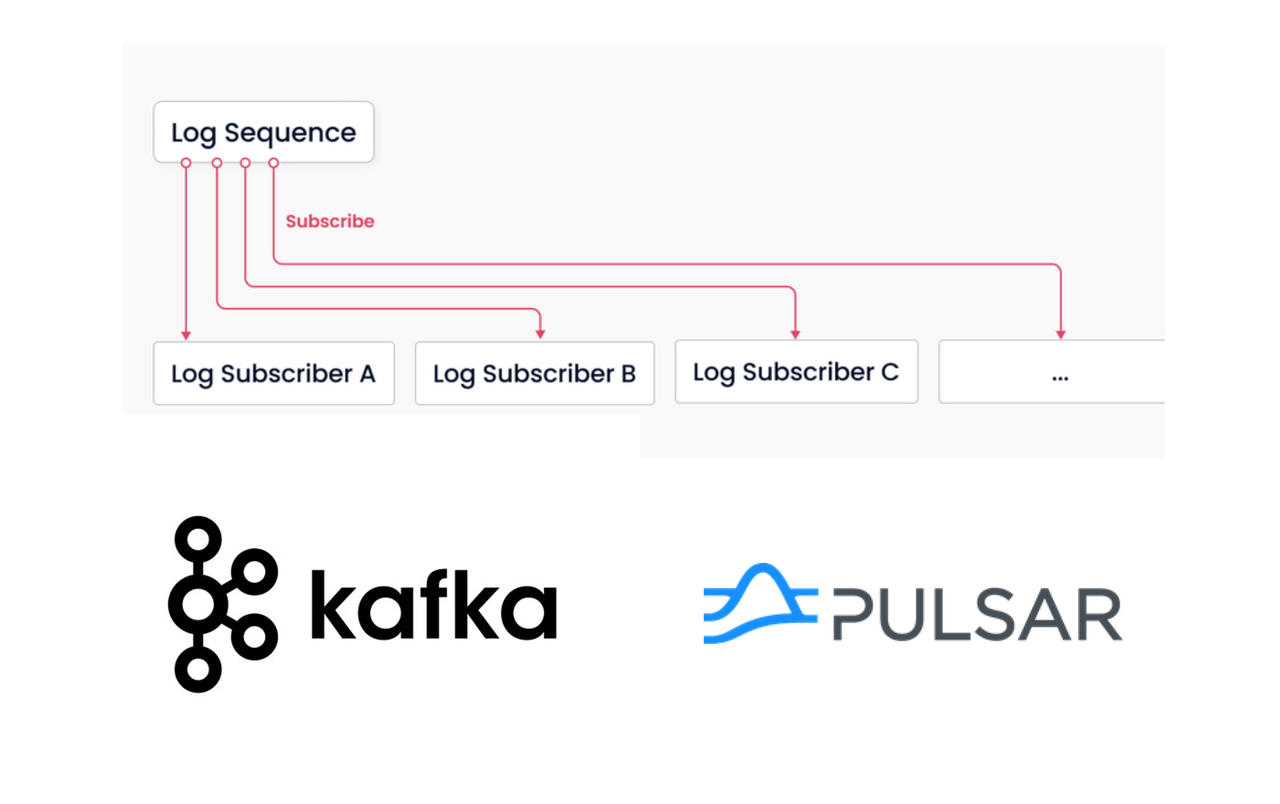
Milvus 中的日志代理。
为可扩展的相似性搜索构建向量数据库
Milvus 建立在流行的矢量搜索库(包括 Faiss、ANNOY、HNSW 等)之上,旨在对包含数百万、数十亿甚至数万亿矢量的密集矢量数据集进行相似性搜索。
独立和集群
Milvus 提供两种部署方式——单机或集群。在独立的 Milvus 中,由于所有节点都部署在一起,我们可以将 Milvus 视为一个单独的进程。目前,Milvus Standalone 依赖 MinIO 和 etcd 进行数据持久化和元数据存储。在未来的版本中,我们希望消除这两个第三方依赖,以保证 Milvus 系统的简单性。Milvus 集群包括 8 个微服务组件和 3 个第三方依赖:MinIO、etcd 和 Pulsar。Pulsar 作为日志代理,提供日志发布/订阅服务。
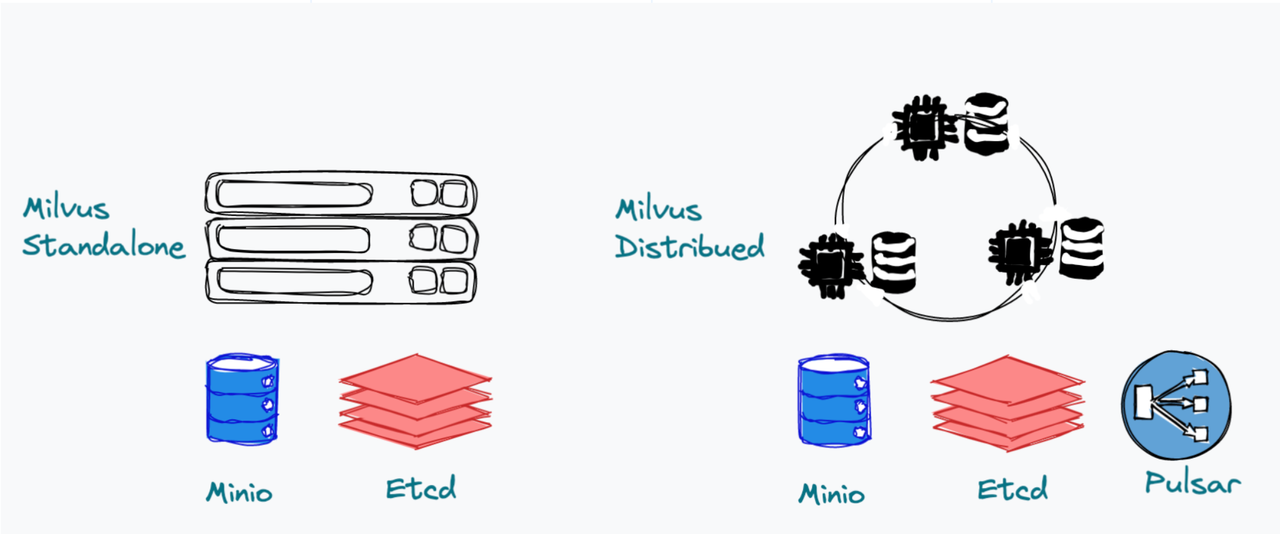
Milvus 的两种部署方式:Milvus 单机版和 Milvus 集群版。
Milvus 架构的简陋骨架
Milvus 将数据流与控制流分离,分为四层,在可扩展性和容灾方面是独立的。
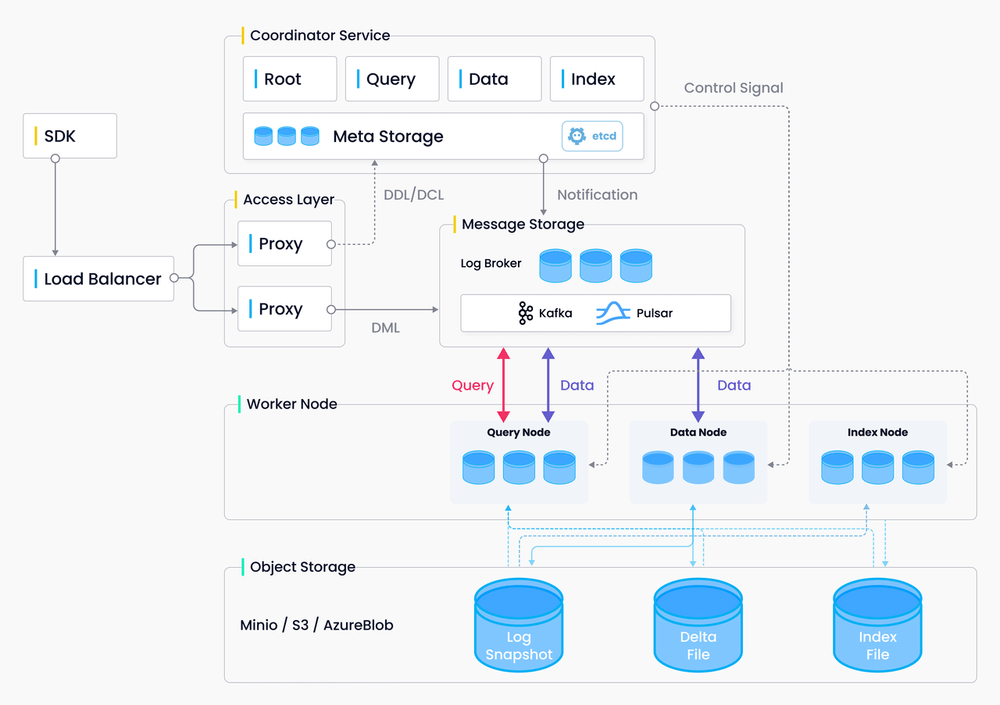
风筝建筑。
接入层
接入层充当系统的面孔,将客户端连接的端点暴露给外界。它负责处理客户端连接,进行静态验证,对用户请求进行基本的动态检查,转发请求,收集并返回结果给客户端。代理本身是无状态的,通过负载均衡组件(Nginx、Kubernetes Ingress、NodePort、LVS)对外提供统一的访问地址和服务。Milvus 使用大规模并行处理 (MPP) 架构,其中代理返回从工作节点收集的全局聚合和后处理的结果。
协调员服务
协调器服务是系统的大脑,负责集群拓扑节点管理、负载均衡、时间戳生成、数据声明和数据管理。各个协调器服务功能的详细解释,请阅读Milvus 技术文档。
工作节点
工作节点或执行节点充当系统的肢体,执行协调服务发出的指令和代理发起的数据操作语言 (DML) 命令。Milvus 中的工作节点类似于Hadoop中的数据节点,或者 HBase 中的区域服务器。每种类型的工作节点对应一个协调服务。各个worker节点功能的详细解释,请阅读Milvus 技术文档。
贮存
存储是 Milvus 的基石,负责数据的持久化。存储层分为三部分:
- Meta store:负责存储元数据的快照,如集合模式、节点状态、消息消费检查点等。这些功能 Milvus 依赖于 etcd,而 Etcd 还承担了服务注册和健康检查的责任。
- 日志代理: 支持回放的发布/订阅系统,负责流式数据持久化、可靠的异步查询执行、事件通知和返回查询结果。当节点进行宕机恢复时,日志代理通过日志代理回放来保证增量数据的完整性。Milvus 集群使用 Pulsar 作为其日志代理,而独立模式使用 RocksDB。Kafka 和 Pravega 等流式存储服务也可以用作日志代理。
- 对象存储: 存储日志快照文件、标量/向量索引文件、中间查询处理结果。Milvus 支持AWS S3和Azure Blob,以及MinIO,一种轻量级的开源对象存储服务。由于对象存储服务的高访问延迟和每次查询计费,Milvus 将很快支持基于内存/SSD 的缓存池和热/冷数据分离,以提高性能并降低成本。
数据模型
数据模型在数据库中组织数据。在 Milvus 中,所有的数据都是按照集合、分片、分区、段和实体来组织的。
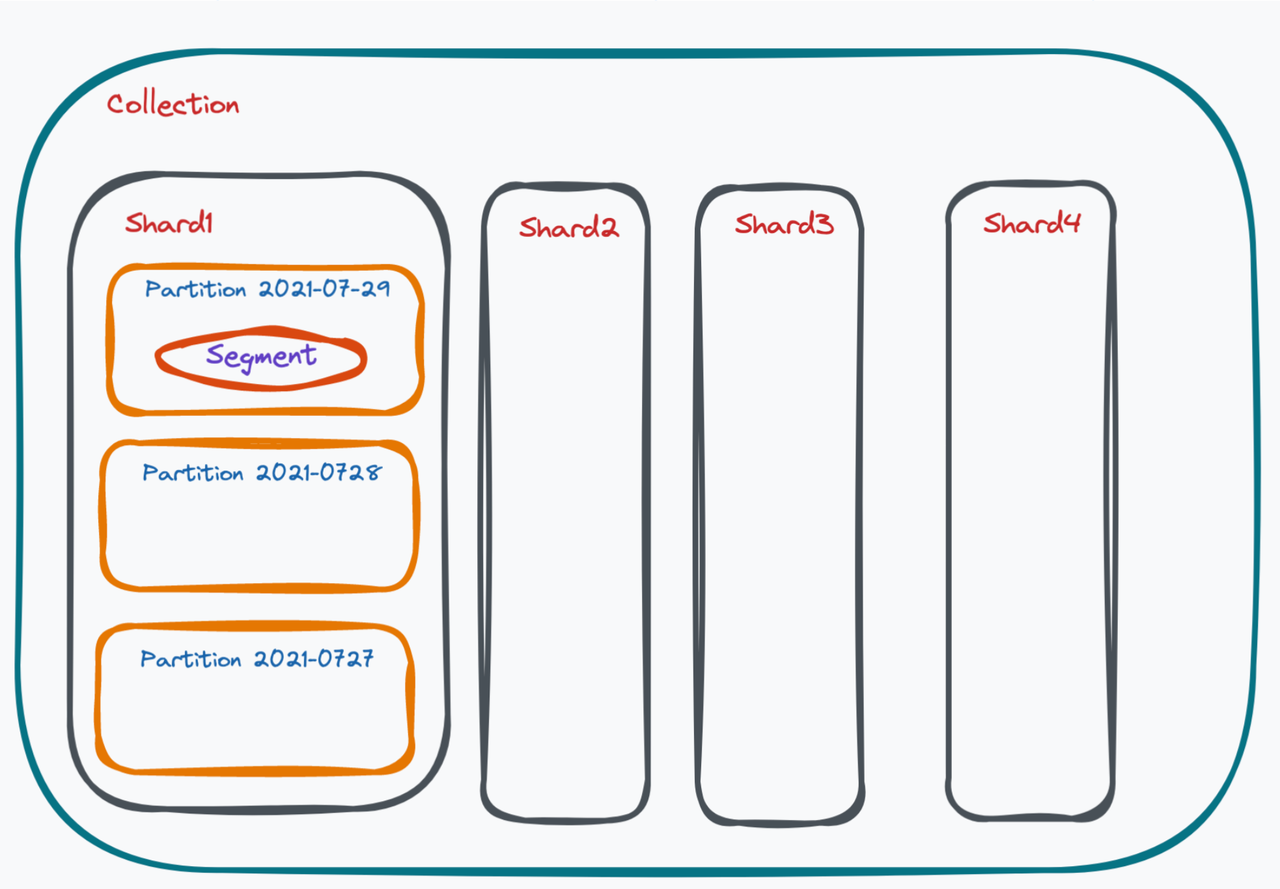
Milvus 中的收集、分片、分区和分段。
收藏
Milvus 中的集合可以比作关系存储系统中的一张表。集合是 Milvus 中最大的数据单元。
分片
为了在写入数据时充分利用集群的并行计算能力,Milvus 中的集合必须将数据写入操作分散到不同的节点。默认情况下,单个集合包含两个分片。根据您的数据集量,您可以在集合中拥有更多分片。Milvus 使用主密钥散列方法进行分片。
分割
一个分片中也有多个分区。Milvus 中的分区是指在一个集合中标记相同标签的一组数据。常见的分区方法包括按日期、性别、用户年龄等进行分区。创建分区可以使查询过程受益,因为可以通过分区标签过滤大量数据。
相比之下,分片在写入数据时更多的是扩展能力,而分区在读取数据时更多的是增强系统性能。
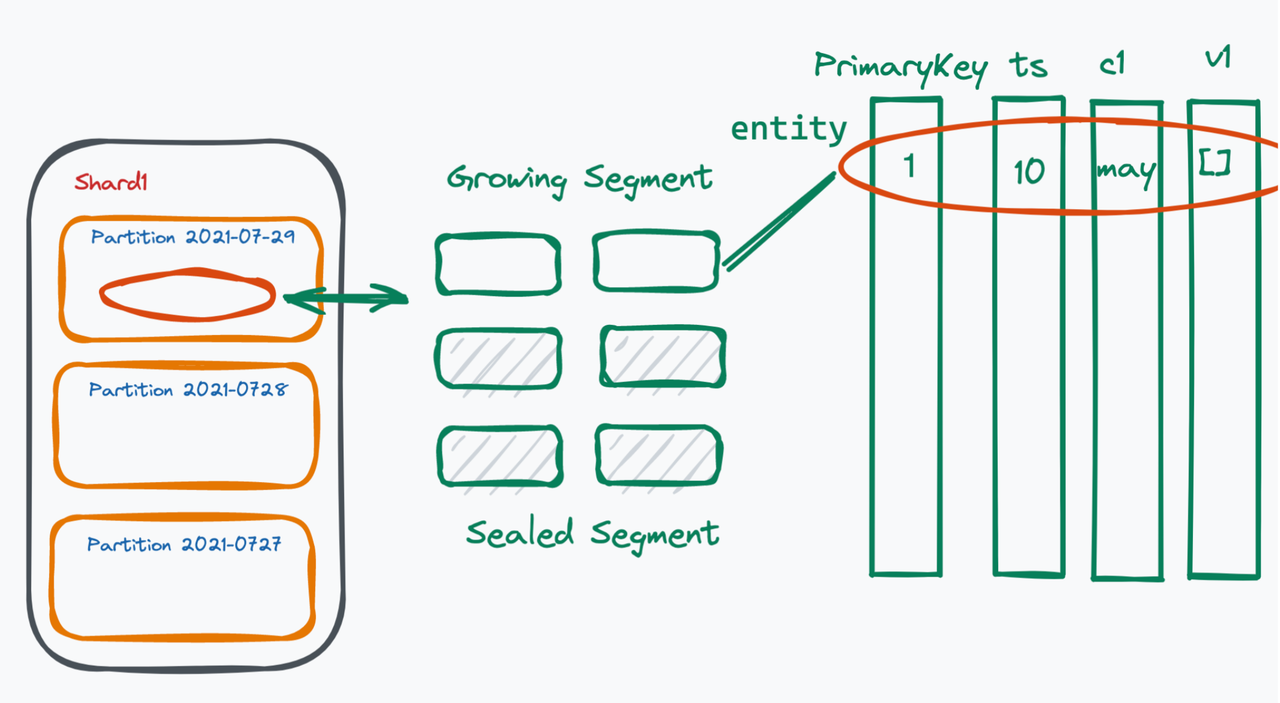
Milvus 中的细分和实体。
细分市场
在每个分区内,有多个小段。段是 Milvus 中系统调度的最小单位。有两种类型的段,生长段和密封段。增长段由查询节点订阅。Milvus 用户不断将数据写入不断增长的细分市场。当增长段的大小达到上限(默认为 512 MB)时,系统将不允许向该增长段写入额外的数据,从而密封该段。索引建立在密封段上。
为了实时访问数据,系统读取增长段和密封段中的数据。
实体
每个段都包含大量的实体。Milvus 中的一个实体相当于传统数据库中的一行。每个实体都有一个唯一的主键字段,也可以自动生成。实体还必须包含时间戳(ts)和向量场—— Milvus 的核心。
下一步是什么?
随着 Milvus 2.0 正式发布,我们计划发布这个 Milvus Deep Dive 博客系列,旨在为社区提供对 Milvus 架构和源代码的深入解读。
本博客系列涵盖的主题包括:
- Milvus 架构概述
- API 和 Python SDK
- 代理和主要数据处理流程
- 数据管理
- 实时查询
- 标量执行引擎
- 质量保证系统
- Milvus_Cli 和 Attu
- 矢量执行引擎
Deep Dive 系列博客将定期发布。所以请继续关注
