




点击上方"数据与人", 右上角选择“设为星标”
分享干货,共同成长!


主机类型:x3850 X6
操作系统:DB:CentOS Linux release 7.4.1708、APP:CentOS Linux release 7.2.1511 (Core)
存储:IBM存储,2TB,MULTIPATH
内存:64 G
CPU型号:E7-4830 v3 @ 2.10GHz ( 4 U * 12 core)
CPU核数:32CORE
数据库环境:11.2.0.4(RAC)
排序、SQL解析、执行计划突变、全表扫描、会话阻塞等都会导致CPU飙升,可能的原因较多,需要层层递进,逐步定位根因;
主要由主机top/topas占CPU高的进程查询相应SQL、会话增长趋势、阻塞分析、ASH/AWR报告分析、SQL执行时间/执行计划变化等;
了解业务场景,业务上有没有变更,例如开发功能变更、业务使用量增加等。

通过分析日志定位、分析故障原因;
追溯历史数据,分析关键指标的历史波动,这些关键指标可以用来做为数据库健康度参考指标。
用实际数据来验证推断,排除掉其它干扰因素,定位数据库问题的根本原因,帮助快速修复。
set linesize 200col username for a15col event for a35col program for a20col cpu_p for 99.99select ta.*, round(ta.cpu_time tb.total_cpu * 100, 1) cpu_usagefrom (select s.username,s.program,s.event,s.sql_id,sum(trunc(m.cpu)) cpu_time,count(*) sumfrom v$sessmetric m, v$session swhere (m.physical_reads > 100 or m.cpu > 100 orm.logical_reads > 100)and m.session_id = s.sidand m.session_serial_num = s.serial#and s.status = 'ACTIVE'and username is not nullgroup by s.username, s.program, s.event, s.sql_idorder by 5 desc) ta,(select sum(cpu) total_cpu from v$sessmetric) tbwhere rownum < 11;
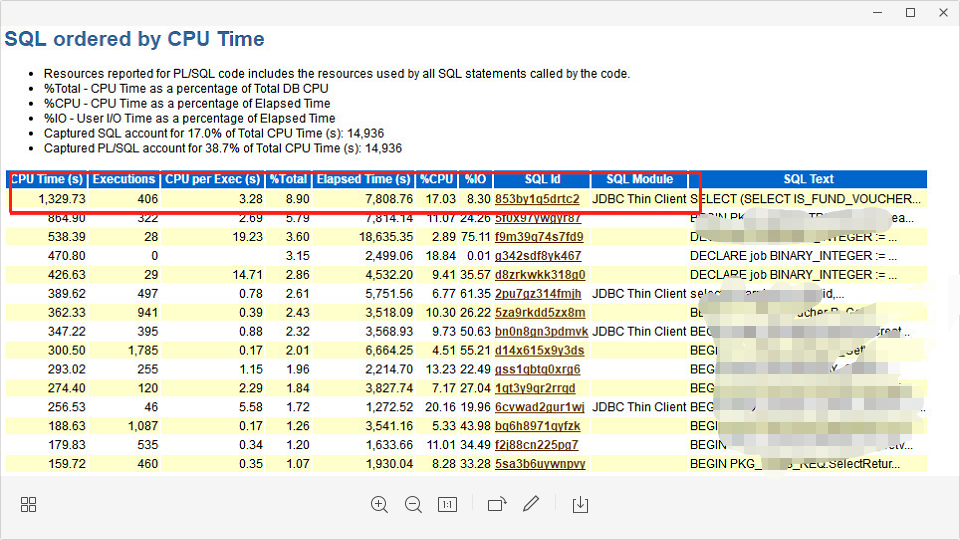
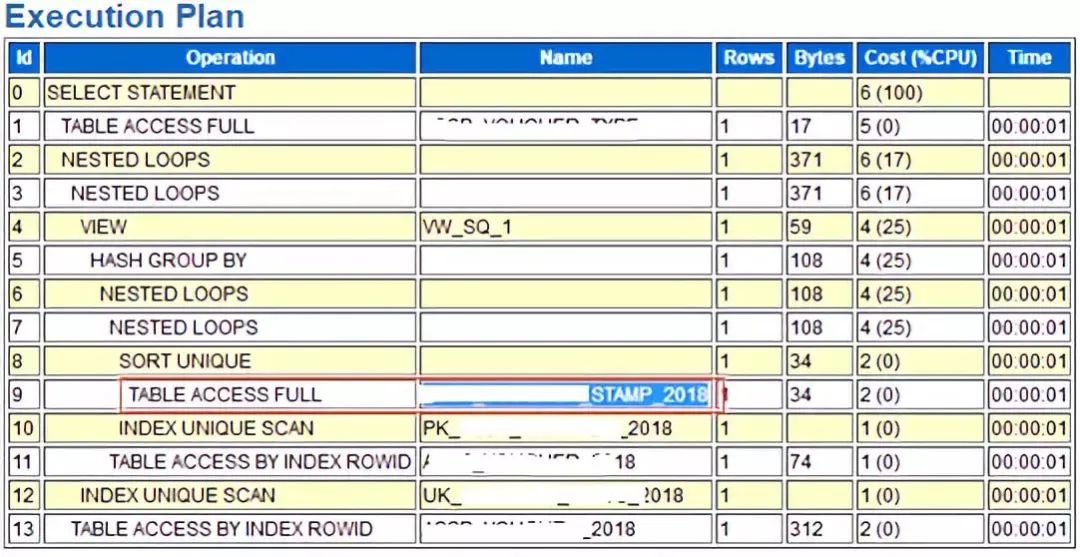
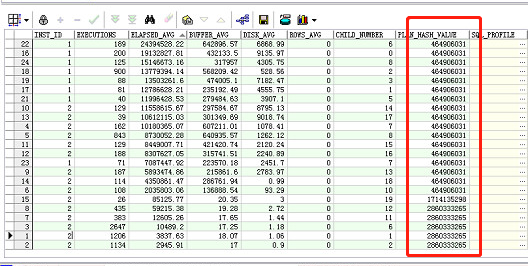
select owner,table_name,partition_name,object_type,stale_stats,last_analyzedfrom dba_tab_statisticswhere table_name = upper('&table_name');

1)当系统有很大的分区表时,如果总是全部收集则会比较慢,11g之后可以设置INCREMENTAL只对数据有变动的分区做收集,如下示:
exec dbms_stats.set_table_prefs('JD','IMS_RES_MONITOR_2','INCREMENTAL','TRUE');exec dbms_stats.set_table_prefs(user,'table_name','INCREMENTAL','TRUE'); --只收集数据变动的分区select dbms_stats.get_prefs('INCREMENTAL',null,'table_name') from dual; --查看分区表INCREMENTAL的值
2)延长自动统计信息收集时间
自动收集统计信息的时间是周一到周五每晚22:00:00到第二天2:00结束,周六周日两天全天收集。可进一步考虑工作日时段延长2小时,即周一到周五时段统计信息收集到第二天4:00结束。
本次故障就是一次统计信息失真导致SQL执行计划走错的简单案例,但有时往往入手的思路错了,导致中间分析的道路过于曲折,在实践中,针对故障和问题需要充分考虑多个可能性,以求一击中的。
文章转载自数据与人,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
