




原文链接:https://dev.to/yugabyte/sqlcl-to-transfer-data-from-oracle-to-postgresql-or-yugabytedb-lha
原文作者:Franck Pachot
以前的dba有过这样的故事:oracle提供了一个“SQLLoader”而没有任何“SQLUnloader”,因为Larry Ellison 不希望他的客户搬走。 现在已经改变了:有一种简单的方法可以使用简单set sqlformat csv的 SQLcl 导出到 CSV。 关注Jeff Smith 博客以了解更多信息。
举个例子。 我想将一些示例数据从Oracle移动到YugabyteDB以比较大小。 我有一个始终免费的自治数据库,其中包括 SSB 示例模式。有一个LINEORDER表,大小为几百GB。 我将使用dbms_metadata获取DDL。 我必须做的唯一更改是sub(" NUMBER,"," NUMERIC,")禁用约束和排序规则。
当然,有一些专业工具可以将Oracle模式转换为PostgreSQL。好的旧的ora2pg或 AWS SCT也非常适合评估迁移所需的更改级别。但是对于一些快速的操作,我很擅长使用awk😉
然后,通过设置set sqlformat csv和一些只输出数据的设置,如feedback off pagesize 0 long 999999999 verify off,导出就很容易了。我将所有awk构建\copy命令的所有内容都通过管道传递给这些 CSV 行。 我喜欢先执行一些小步骤,然后在 COPY 命令的开头设置 10000 行 COPY(NR-data)%10000命令data。并行发送它们很容易,但我可能不需要它,因为YugabyteDB是多线程的。
这是我使用的脚本 - 我在 TNS_ADMIN 中有我的自治数据库钱包,我家中安装了 SQLcl(一个 Oracle 免费层 ARM,我也在其上运行我的 YugabyteDB 实验)。
{
TNS_ADMIN=/home/opc/wallet_oci_fra ~/sqlcl/bin/sql -s demo/",,P455w0rd,,"@o21c_tp @ /dev/stdin SSB LINEORDER <<SQL
set feedback off pagesize 0 long 999999999 verify off
whenever sqlerror exit failure
begin
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'SEGMENT_ATTRIBUTES', false);
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'STORAGE', false);
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'CONSTRAINTS', false);
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'REF_CONSTRAINTS', false);
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'SQLTERMINATOR', true);
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'COLLATION_CLAUSE', 'NEVER');
end;
/
set sqlformat default
select dbms_metadata.get_ddl('TABLE','&2','&1') from dual ;
set sqlformat csv
select * from "&1"."&2" ;
SQL
} | awk '
/^ *CREATE TABLE /{
table=$0 ; sub(/^ *CREATE TABLE/,"",table)
print "drop table if exists "table";"
schema=table ; sub(/\"[.]\".*/,"\"",schema)
print "create schema if not exists "schema";"
}
/^"/{
data=NR-1
print "\\copy "table" from stdin with csv header"
}
data<1{
sub(" NUMBER,"," numeric,")
}
{print}
data>0 && (NR-data)%1000000==0{
print "\\."
print "\\copy "table" from stdin with csv"
}
END{
print "\\."
}
'
输出可以直接通过管道传输到psql😎
这是我开始加载时的屏幕:
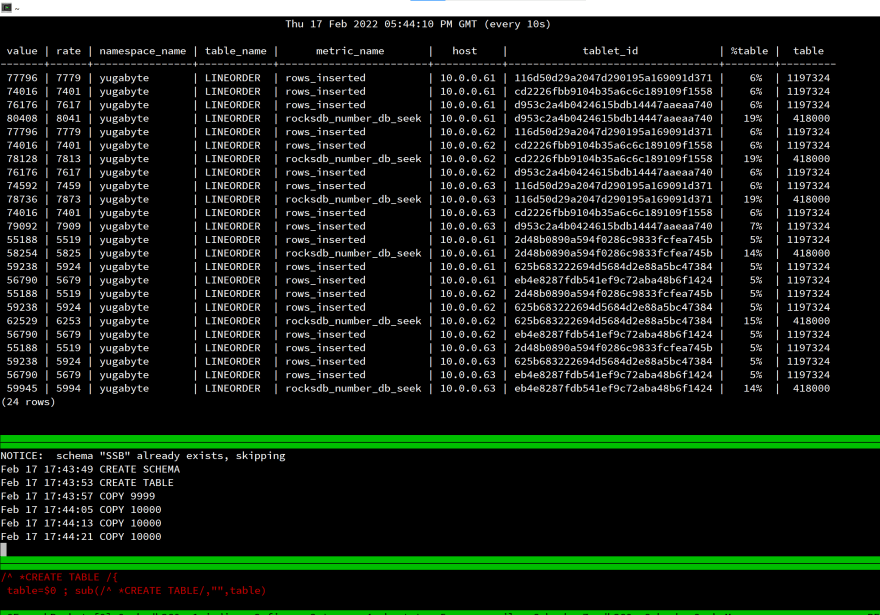
这是一个实验,测量运行时间没有意义,但我查看了rows_inserted统计信息,以验证所有数据都分布在分布式SQL数据库的3个节点上。 即使使用单个客户端会话,负载也会分布在所有集群上。
这对于PostgreSQL也是一样的,因为它们是相同的API: YugabyteDB在分布式存储上使用了PostgreSQL。
此测试中的所有组件都是免费且易于使用的:
- 虚拟机位于 Oracle 云免费层 (ARM) 上,Oracle 数据库是免费的自治数据库 👉 https://www.oracle.com/cloud/free/
- PostgreSQL 是开源免费的👉 https://www.postgresql.org
- YugabyteDB 是开源免费的👉 https://www.yugabyte.com
