




作者 | gongyouliu
编辑 | auroral-L
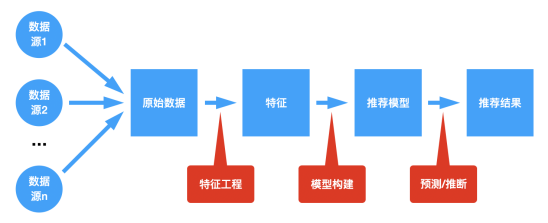


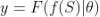 ,这里 F 是我们要学习的模型,
,这里 F 是我们要学习的模型,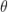 是模型的参数(包括超参数),S 是样本,f 是样本到模型特征的映射,这个过程可以看作特征工程的过程,
是模型的参数(包括超参数),S 是样本,f 是样本到模型特征的映射,这个过程可以看作特征工程的过程, 就是样本S对应的特征,记为:
就是样本S对应的特征,记为: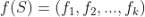 ,这里
,这里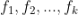 是 k 个特征。y 是最终的预测值,一般可以是一个实数值,可以理解为预测评分或者用户点击、喜欢的概率(具体怎么理解,需要根据选择的模型而定)。
是 k 个特征。y 是最终的预测值,一般可以是一个实数值,可以理解为预测评分或者用户点击、喜欢的概率(具体怎么理解,需要根据选择的模型而定)。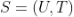 ,这里 U 是用户, T 是物品。那么样本集是所有这些用户 U 对物品 T 有操作行为的“用户物品对”构成的集合,即
,这里 U 是用户, T 是物品。那么样本集是所有这些用户 U 对物品 T 有操作行为的“用户物品对”构成的集合,即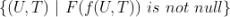 。的特征 了,这个过程就是特征工程的过程。下面图8以可视化的形式展示了每个样本按照5个维度的特征拼接获得的训练样本。
。的特征 了,这个过程就是特征工程的过程。下面图8以可视化的形式展示了每个样本按照5个维度的特征拼接获得的训练样本。
,采用跟训练集中样本一样的方法构建这个待预测的“用户物品对”的特征,然后灌入训练好的模型获得最终的预测结果。 的关联推荐下点击了
的关联推荐下点击了 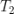 ,那么三元组
,那么三元组  就可以作为一个样本。如果你的产品没有关联推荐,那么我们可以将用户在相近时间浏览的两个商品(比如用户搜索手机这个关键词,在搜索结果中同时浏览了iPhone13和华为P50)可以构成一个样本对。之所以选择时间相近的,是考虑到用户在相近时间点兴趣点是一致的,这个一致性刚好是关联推荐需要挖掘出的信息。 三元组),但是我们这里讲的是非个性化的关联推荐,所以特征中不应该包含用户特征,同时行为特征中也不是单个用户的特征,而是群体相关的特征(比如 的平均播放时长等),由于是两个物品
就可以作为一个样本。如果你的产品没有关联推荐,那么我们可以将用户在相近时间浏览的两个商品(比如用户搜索手机这个关键词,在搜索结果中同时浏览了iPhone13和华为P50)可以构成一个样本对。之所以选择时间相近的,是考虑到用户在相近时间点兴趣点是一致的,这个一致性刚好是关联推荐需要挖掘出的信息。 三元组),但是我们这里讲的是非个性化的关联推荐,所以特征中不应该包含用户特征,同时行为特征中也不是单个用户的特征,而是群体相关的特征(比如 的平均播放时长等),由于是两个物品  的关联推荐,那么特征中是可以包含两个物品的特征的。读者可以参见下面图9直观地看看具体的特征情况。
的关联推荐,那么特征中是可以包含两个物品的特征的。读者可以参见下面图9直观地看看具体的特征情况。
的特征灌入模型获得它们之间的关联度。有了任何两个物品的关联度。我们就可以将与 最相关的N个物品按照相似度降序排列作为 的关联推荐。

文章转载自数据与智能,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
