




在 2019 年的时候,当时所在的团队正在开始大规模使用 containerD,我们初期遇到较多 containerd-shim 的死锁等稳定性问题,我们不得不去思考去除 containerd-shim 进程的可能性。由于当时技术选型上的限制,containerd-shim 必须作为容器 subreaper 而存在。直到去年才留意到 pidfd pollable,我才发现 containerd-shim 管控面其实是可以被移除。我顺着这个思路作出了 embedshim 这个 containerD 第三方插件。在介绍这个插件之前,我们先简单回顾下 containerd-shim 的发展历程。
1. 从 docker 的原地升级到 containerd-shim
1.1 原地升级的需求
最初 dockerd 的容器进程管理是非常简单粗暴的,它采用了 Fork-and-Wait 模式来监控容器状态,并通过无名管道接管容器的标准输入输出。如果 dockerd 进程重启,那么它将无法重新监控容器的状态变化,而这些已运行的容器都将变成 孤儿
。为了防止资源残留,dockerd 重启后的第一件事就是停掉正在运行的容器。然而节点组件的重启和周期性升级都属于正常操作,dockerd 停服重启应保证正在运行的容器不受影响。
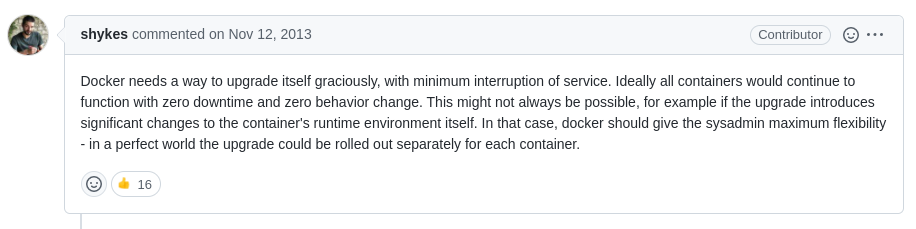
这 docker#2658 帖子记录了当时 dockerd 原地升级的细节讨论;当然除了方案讨论外,用户对该需求落地呼声评论是更强烈些的。组件进程重启涉及到的细节比较多,但可以归类为状态恢复以及临时(残留)数据的清理,比如有讨论清理未完成的网络初始化资源,有讨论如何恢复接管容器的标准输出,还有讨论如何做镜像下载的断点续下等等。而对于本文的主题 - 如何重新接管存量容器进程的场景而言,个人认为仅需要考虑下面两个问题即可:
如何保证容器退出事件不丢失?
如何重新接管容器的标准输入输出?
首先,我们来看第一个问题。进程退出码能正确反映一个进程是以什么状态结束的,有正常退出的,有收到 SIGTERM 信号优雅停服的,还有因无法分配新的内存而被内核 SIGKILL 的。开发者和运维人员可以根据进程退出码以及关键日志信息来做 非预期退出事件
的诊断,所以对于进程管理方案而言,进程退出码必须要能被正确捕获,而当时最稳妥的方式是有一个常驻进程来做容器进程的 subreaper。
相比于第一个问题,第二个问题处理起来要简单些。经历过早期节点运维的朋友都知道,在容器化之前呢,大部分业务进程的管理是通过 systemd-service 来实现。业务进程直接被一号进程所监管,同时它们采用了 Headless 无界面无交互的方式运行。它们的标准输出通常以 UDS 流的形式传递给 systemd-journald 服务,由 systemd-journald 来做日志持久化和轮动存储。
容器化后的节点运维比 systemd 模式要稍微复杂些。容器化产生了根路经和资源视图隔离,容器管理面需要封装 nsenter 和 chroot/pivot 等系统调用来提供便捷的运维通道。dockerd 进程提供了 execCreate/execStart/execAttach HTTP 接口来进入到容器隔离视图,这种具有交互能力的运维通道必定会感知 dockerd 停服。但个人认为这种感知是可接受的,只要能保证容器标准输出不因 dockerd 停服而丢失即可。在标准输入输出的接管上,dockerd 并没有采用 UDS 流模式,而是采用有名管道的方式。
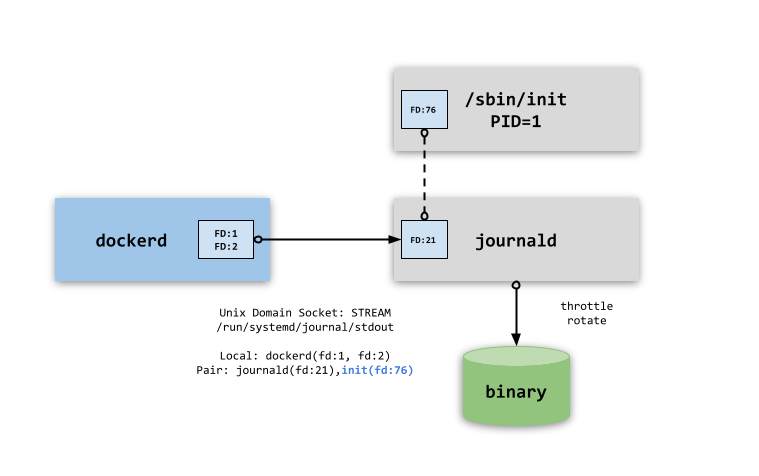
一般情况下,systemd-journald 服务会备份 UDS 通信的文件句柄在一号进程那,否则 systemd-journald 重启将自动关闭 UDS 通信管道,业务进程将收到 SIGPIPE 错误,该通信管道将无法接受数据,只能通过重启业务进程来解决问题。但 dockerd 进程没有这样的福利,它只能选择通信管道可文件实体化的有名管道。只要数据产生者以 读写模式
开启有名管道,即使作为接收端的 dockerd 停服了也不会产生 SIGPIPE 错误,最差也就是停服时间长导致业务进程阻塞(systemd-journald 同样有该问题)。
所以回到最初的问题上,dockerd 需要一个常驻进程来做容器进程的 subreaper。
1.2 live-restore: containerd-shim 的雏形
从 2013 年到 2016 年期间,docker 社区先后将 libcontainer(runC) 实现捐赠给 OCI 以及 libcontainerd 组件进程化,这些里程碑的出现推动了 docker 原地升级的落地,并在 2016 年的 v1.12 大版本里推出了 live-restore: true
原地升级的能力。
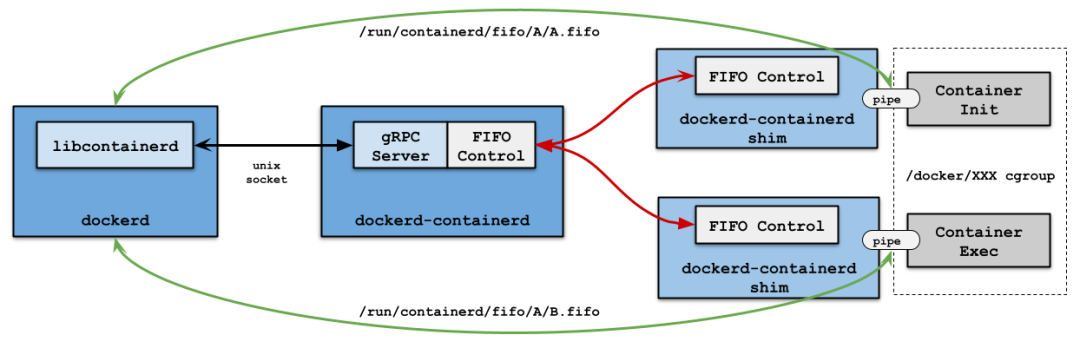
如上图所示,docker-containerd-shim(后称 shim) 将作为容器进程的父进程,它仅用于转发容器的标准输入输出和监控容器状态变化。由于 shim 功能单一,它编译后仅有 2 MB 左右。如果容器数目不多,而且没有过多的数据转发给 dockerd,节点上的 shim 进程消耗资源属于可控的状态。至于这里为什么会多一个 docker-containerd 进程,个人猜测这和后续捐赠动作有关,docker-containerd 后续将会成为独立项目 containerD 并捐赠给 CNCF 基金会;而 containerD 的定位是 an industry-standard container runtime,开发者可以根据自己的需要来定制容器管控面,比如早期的 containerd-CRI 组件,buildkitd 镜像构建服务以及阿里巴巴的 PouchContainer 引擎等等,所以 v1.12 大版本把 dockerd 拆成三层管控,个人理解这是为了方便后续的集成。
docker v1.12 版本是一个重要的里程碑,它的出现基本上预示着容器技术将会在生产环境的大规模使用。当时 docker 社区的版本里称之为 Deamonless Container,即不需要常驻进程来管理容器。其实阿,这里的 Deamonless 指的是 dockerd。
1.3 CNCF 版本的 containerd-shim
到了 2017 年,docker 将 docker-containerd 组件捐赠给了 CNCF 基金会,并以 containerD(Con-tay-ner-D) 全新的项目出现。从个人角度来看,containerD 是 OCI 镜像格式标准、镜像分发标准以及容器运行时管控的最佳实践。containerD 目标是成为一个工业级别的容器引擎,可用它来对接任何自定义的管控需求:向上可以对接 Kubernetes Container Runtime Interface(CRI) 和构建镜像的 buildkitd;对下可以管理 Kata-Container, gVisor, Windows-Container 等不同的容器运行时。
但在 containerD 项目初期,容器生命周期管控逻辑集中在 containerD 进程里。为了对接不同的容器运行时,containerD 将管控逻辑下沉到 shim 实现上,如下图所示。容器运行时的作者仅需要实现 shim 接口就可以和 containerD 做第三方插件的集成。

除了插件化增强外,CNCF 版本的 shim 针对普通容器管理做了两个优化:
Exec 管理将由容器所属的 shim 管理
不同容器之间可以共享同一个 shim 进程
不同容器共享同一个 shim 进程的方案是用来优化 kubernetes 场景下的内存资源问题。一个具有 RPC 能力的 shim 活跃内存就有 3 MB (计算逻辑为 memory.usage_in_bytes - memory.stat.inactive_file), 而一个 Pod 默认就有两个容器;而在云原生场景下,业务容器配置个日志采集、Service Mesh 等边车型容器是非常常见的。如果一个容器就需要 3 MB 常驻内存,kubernetes 场景下节点一般都有 10-20+ Pod, 啥都没做就轻松消耗上百兆资源,放大到整个基建以及数据中心都是比较客观的数字。共享模式可优化多容器的 Pod 资源,边车型的容器越多时,效果越明显。
1.4 有可能去除 runC shim 吗?
在 containerD 架构设计里,shim 是一个很关键的抽象概念,它做到了 Out-of-Tree 模式对接各式各样的容器运行时,尤其是对 Kata-Container Host 管控面的优化上发挥了重要作用。但对于我们常用的 runC 运行时而言,它并不需要常驻的 QEMU 进程,也不需要常驻的 Application Kernel,容器进程和普通进程一样,进程间共享同一个内核。那么回顾下最初 dockerd 的管控逻辑,如果我们能保证进程退出码不会丢失,那么 runC shim 是否可以被优化掉?
答案是可以!
我个人开源了 embedshim 项目,它是一个 containerD 第三方容器管控插件,它不仅保证容器退出码不会丢失,还能确保 containerD 重启后依然能感知到容器进程的退出事件。使用它之后,runC shim 将被移除,缩短整个容器管控链路,节省不必要的资源开销。
2. 内核是我们的边车!
embedshim 将监控进程退出码的工作几乎都交给了内核。
首先内核支持使用 sched_process_exit
来追踪处理进程退出的事件。在当前讨论的场景下,我们不仅需要能感知到容器进程退出事件,还需要将容器进程退出码持久化,以防止 containerD 进程重启过程中丢失。在这里,eBPF 是我们的最佳选择。临时文件系统 BPF-FS 可以持久化 关联后
的 eBPF 程序和 Map 存储。即使注入 eBPF 程序的进程退出了,内核依然可以调用这些持久化后 eBPF 程序来响应事件,比如 sched_process_exit
事件。
除此之外,更重要的是 v5.4 内核还提供了 pidfd pollable 能力。pidfd 是和某一个正在运行的进程相关联的文件句柄,这个句柄可用来给关联进程定向发送信号、复制被关联进程的文件句柄以及感知被关联进程的退出事件。感知被关联进程的退出事件
便是我们提到的 pidfd pollable。它打破了 subreaper 必须是父进程的限制,即使是非父进程也可以感知到类 SIGCHLD 信号。这个信号通知发生在 sched_process_exit
事件处理之后,换句话说,pidfd 文件句柄可读则意味着我们可以从 eBPF Map 中读取关联进程的退出码了。
有了 sched_process_exit
事件处理程序以及 pidfd pollable 这两大神器,containerD 将不再需要 subreaper,容器进程可以放心交给一号进程管理。在过去 shim 是我们的边车,而现在内核是我们的边车,而且车将开的更稳!
3. embedshim 进程管理
下图为 embedshim 设计概况,除了借助内核能力外,embedshim 还依赖 OCI runC 容器创建流程设计。
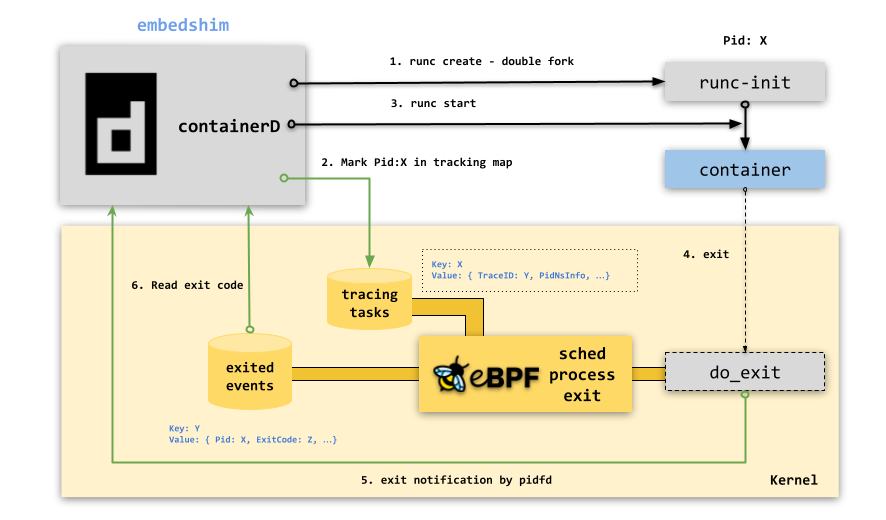
runC 把创建容器分为两阶段: create 和 start。早期我并没有参与过定制 OCI Runtime 标准的讨论,但从个人角度来看,两阶段的设计其实是有利于做进程管理的。首先 runC-create 会 fork 出 runC-init 进程,然后它通过 UDS 和 runC-init 进程进行交互,比如 cgroup 参数写入、数据卷的挂载、capability 权限配置、当然还有一些 Hook 的调用等等。之后 runC-create 进程将退出,而 runC-init 进程通过 exec.fifo 有名管道等待 runC-start 的指令来完成最后的 exec 系统调用(切换成容器进程)。runC-create 和 runC-start 两命令行之间所产生的停端间隔可以让集成方做一些能力拓展,尤其是那些需要在 exec 系统调用前完成的事情。
在 embedshim 这个场景下,我用它来追踪容器进程的状态变化。如果 runC 创建容器不是两阶段,那么遇到 短命
的容器进程,比如 flannel CNI initContainer,我们很可能还没开始注册追踪任务,容器进程就退出了,而两阶段创建可确保不出现这样的问题。所以在 runC-create 成功执行后, embedshim 会给该容器分配一个独一无二的 TraceID 来标识容器进程 PID,它将追踪任务注册到 tracking_tasks
eBPF Map 存储里,并使用 pidfd_open 来监控进程退出事件。一旦监控准备工作完毕, containerD 就会开始调用 runC-start 来启动容器进程。只要容器进程一退出,embedshim 注册的 eBPF 追踪程序便会将其退出码持久化到 exited_events
eBPF Map 存储里,并去除追踪任务,其中 exited_events
使用 TraceID 做容器退出码的索引。因为 PID 有复用的风险,利用 exited_events
存储可确保退出码信息准确。内核调用追踪程序后,它会通过 pidfd 来通知 embedshim 有容器退出了,而 embedshim 会拿着容器退出码来更新容器状态。
当然除了容器进程外,我们还需要支持容器的运维进程。runC-exec 运维命令并非两阶段创建模型,它直接采用 execve 模型来创建运维进程。这些运维进程一般都比较短命,尤其是 Pod Probe 类型的探针性命令。为了保证能正确捕捉到 exec 进程的退出事件,embedshim 通过 runcext 进程以 subreaper 的身份调用 runC-exec。runcext 进程调用完毕 runC-exec 后,它会通过 UDS 将 exec 进程状态反馈给 embedshim。即使 exec 进程真的短命,runcext 也能通过 waitpid 系统调用感知它的退出码。针对这种场景,embedshim 可直接将状态更新到 exited_events
存储里,无需走 sched_process_exit
事件处理模式。
runcext 一定程度上模拟了两阶段创建,并不原生化。为了解决这个问题,我在 runC 社区提出了 Feature Request: Support Two Phases to Start Exec Process like Init 请求,目前已两个 runC Maintainer 同意了该提案,后续我会把这部分优化提交到社区。
这就是 embedshim 管理容器进程的整体思路。embedshim 监控一个容器进程的退出码仅需要 32B 的内存空间,即使有上千个容器进程也仅需 KB 级别的内存, 它不仅去除了 shim subreaper 缩短了调用链路,还减少了不必要的内存开销,这可能就是内核边车的价值所在。
4. 简化容器 stdio 重定向:可支持 99% 场景
shim 边车并非直接将有名管道作为容器进程的标准输入输出,而是中间加了一层转发,如下图所示。
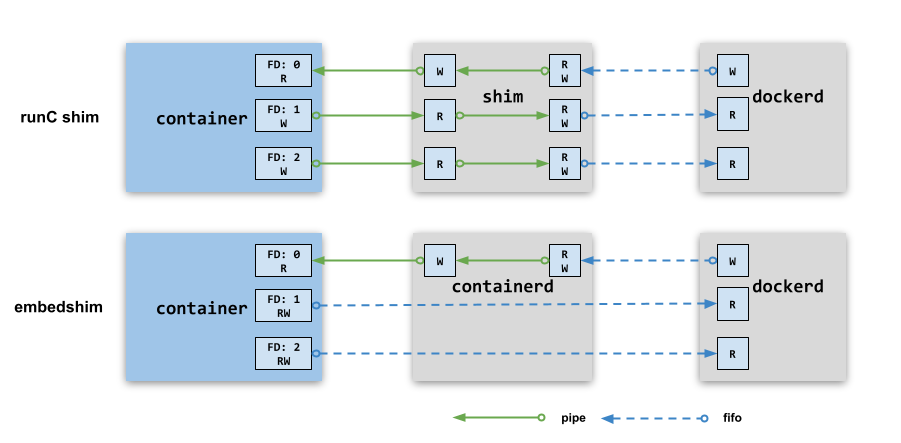
shim 边车将无名管道的一端作为容器的标准输出,另外一端用来将数据同步到有名管道上,由接收方 dockerd 或者 containerD 消费。因为有名管道开启了读写模式,所以即使接收端退出了也不会出现 SIGPIPE 错误,接收端重启后还是可以接管容器输出。同样地,标准输入的处理和标准输出一样,只是数据方向相反。
单纯从容器标准输出来看,shim 边车的确不应该做这一层转化,直接将有名管道交给容器即可。但交互模式下的标准输入是必要的。*nux 系统提供了管道来将多个命令行串联在一起,比如 echo hello | cat
,echo 传递 hello 之后并发送 EOF,这样 cat 打印 hello 完毕后会认为已经没有输入,它便自动会退出。这种模式在容器场景下也十分常见。但如果我们直接将 读写模式
的有名管道作为容器进程的标准输入,那么我们将无法给容器进程发送 EOF,它将永远等待用户的输入,所以 shim 边车只能利用无名管道的模式来做 EOF 信号通知。可能是为了方便管理吧,shim 边车也将这种中转模式应用到了标准输出。
embedshim 同样也采用中转的方式来处理标准输入,但它直接将读写模式的有名管道交给了容器的标准输出,减少标准输出的拷贝。embedshim 插件属于 containerD 进程的一部分,一旦 containerD 重启,那么容器进程的 输入端
将收到 SIGPIPE 错误。对于这种情况,个人觉得是可以接受的。在交互模式下,用户会感知到容器引擎的停服。而线上环境的大部分场景都是采用 Headless 无交互模式,容器进程的输入端都是 /dev/null,而标准输出的状态由有名管道做持久化,不会因为 containerD 停服而出现 容器输出端
的 SIGPIPE 错误。
所以从个人使用经验来看,只要不强求恢复停服前的交互输入,embedshim 基本上能满足大部分人的需求,至少 Kubernetes 场景下的容器都可以满足。
5. v0.1.0 版本发布
最后,我刚发布了 embedshim v0.1.0 版本,它目前经过 CRI-TEST 测试套件的验证,也欢迎大家使用来提提意见。
