




作者:David Rowley
译者:阎书利
正文
近年来,PostgreSQL 进行了一些优化,使排序速度更快。在 PostgreSQL 15 开发周期(于 2022 年 4 月结束)中,我和 Ronan Dunklau、Thomas Munro、Heikki Linnakangas 对 PostgreSQL 做出了一些更改,以加快排序的速度。
当 PostgreSQL 15 于 2022 年底推出时,排序的每一项优化都应该是可用的状态。
为什么要关心排序性能?当您在 PostgreSQL 上运行应用程序时,有几种情况 PostgreSQL 表示您需要对记录(也称为行)进行排序。主要用于 ORDER BY 查询。排序也可以用于:
- 使用 ORDER BY 子句聚合函数
- GROUP BY 查询
- 具有包含合并联接的计划的查询
- UNION 查询
- DISTINCT 查询
- 带有 PARTITION BY 和/或 ORDER BY 子句的窗口函数的查询
如果 PostgreSQL 能够更快地对记录进行排序,那么使用 sort 的查询将运行得更快。
让我们探索 PostgreSQL 15 中使排序性能更快的 4 项优化:
变化1:对单个列的排序的优化
变化2:使用生成内存上下文来减少内存消耗
变化3:为常见数据类型添加专门的排序例程
变化4:用多路归并 (k-way merge)代替多阶段合并 (Polyphase Merge)算法

变化 1:优化对单个列的排序
PostgreSQL 14 的查询执行器总是会在排序操作期间存储整个元组。此处的更改使得 PostgreSQL 15 仅在排序结果中有单个列时存储 Datum。仅存储 Datum 意味着不再需要将元组复制到排序的内存中。
优化适用于以下查询:
SELECT col1 FROM tab ORDER BY col1;
而不是
SELECT col1, col2 FROM tab ORDER BY col1;
上述第一个查询在实际中可能很少见。使用单列排序的其中一个更常见的原因是组合排序半连接 (merge join semi )和 组合排序反连接 (merge join anti )。这些很可能出现在包含 EXISTS 或 NOT EXISTS 子句的查询中。
下图显示了通过测试对10,000个整数值进行排序的性能,仅使用Datum可以帮助存储多少数据。
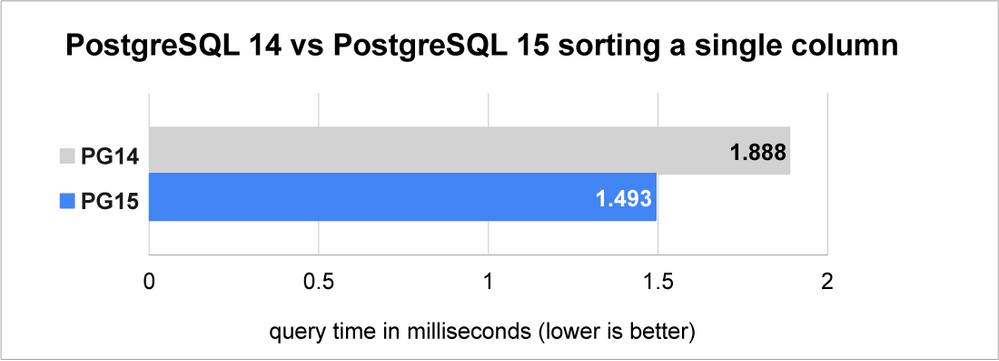

图 1:在 PostgreSQL 15 中对单个列进行排序的速度比在 PostgreSQL 14 中快 26%。
有关详细信息,请参阅 https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=91e9e89dc
变化2:使用生成内存上下文来减少内存消耗
当 PostgreSQL 存储记录以准备排序时,它必须将记录复制到准备排序的内存区域中。在 PostgreSQL 14 和更早的版本中,当分配内存来存储要排序的记录时,使用“aset”内存分配器。这些内存分配器用于管理 PostgreSQL 中的内存。它们充当 PostgreSQL 和底层操作系统之间的缓冲区。“aset”分配器(AllocSet)总是将内存分配请求的大小向上取整为 2 的下一个幂。例如,24 字节的分配请求变为 32 字节,而 600 字节变为 1024 字节。舍入到 2 的下一个幂,因为当内存被释放时,PostgreSQL 希望能够重用该内存以满足未来的需要。完成向上舍入以便可以根据分配的大小在空闲列表中跟踪内存。
向上取整到 2 的下一个幂会导致平均 25% 的内存被浪费。
通常,PostgreSQL 在排序时不需要为记录释放任何内存。正常它只需要在排序完成后立即释放所有内存,并消耗记录。当要排序的数据不适合内存并且必须溢出到磁盘时,PostgreSQL 也会立即释放所有内存。因此,对于一般情况,PostgreSQL 永远不必释放单个记录,并且内存分配大小的四舍五入只会导致内存浪费。
PostgreSQL 有另一个名为“generation”的内存分配器。这个generation分配器:
- 从不维护任何空闲列表
- 从不四舍五入分配大小
- 假设分配模式是先进先出的。
- 当不再需要每个块上的所有块时,依赖于释放完整块
因为"generation" 不会对分配大小进行四舍五入,所以 PostgreSQL 可以用更少的内存存储更多的记录。从 CPU 缓存的角度来看,将 sort 的元组存储切换为使用生成内存上下文而不是 aset 上下文也可以改善这种情况。
这种变化能提高多少性能取决于存储的元组的宽度。略高于 2 次方的元组大小提高最多。例如,PostgreSQL 14 会将一个 36 字节的元组四舍五入为 64 字节——接近所需内存的两倍。我们可以预见到,已经是 2 次方大小的元组的性能提升最少。
为了显示这种变化使排序的速度有多快,我们需要测试几个不同大小的元组。我所做的是从 1 列开始并测试其性能,然后再添加另一列并重复。我停在 32 列。每列使用 BIGINT 数据类型,每次添加一列时会消耗额外的 8 个字节。
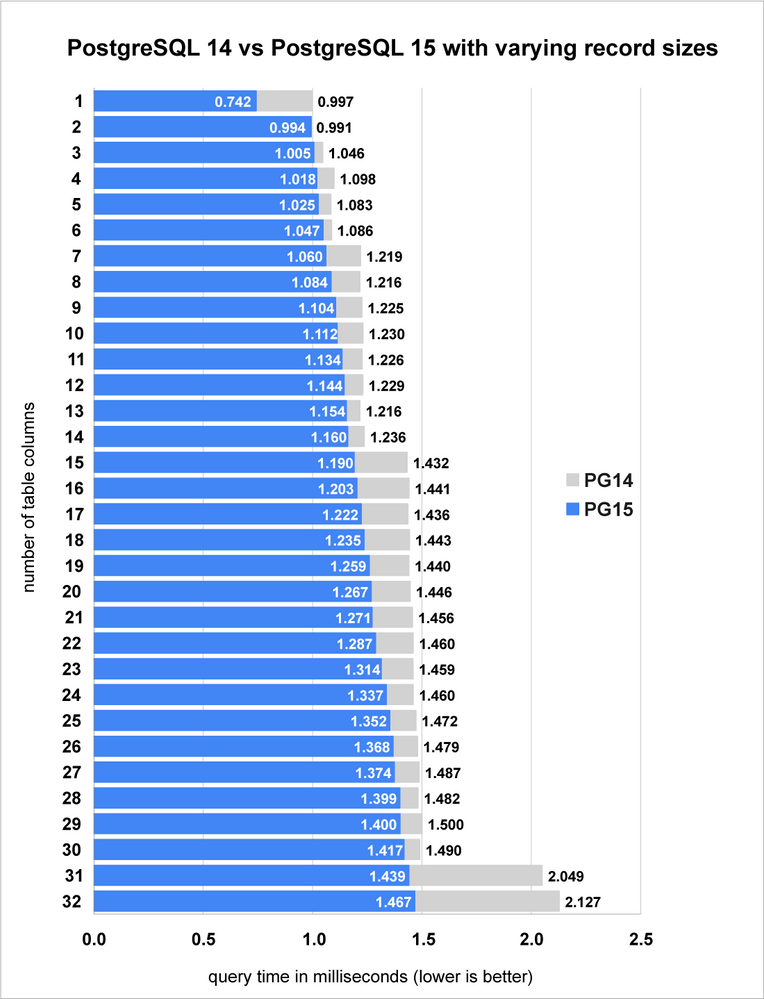
图 2:图表显示 PostgreSQL 15 中内存排序的性能提高了 3% 到 44%。
测试结果表明,PostgreSQL 15 的性能提升了 3% 到 44%,具体取决于元组的宽度。
- 仔细观察 PostgreSQL 14 的时间,您可以看到条形图呈阶梯状上升。当元组大小超过另一个 2 的幂时,每一步都对齐。
- 而对于 PostgreSQL 15,您看不到与 Postgres 14 一样(7 列、15 列和 31 列)查询时间明显更长的“步骤”。相反,在 PostgreSQL 15 中,查询时间随着列数的增加而逐渐增加。
PostgreSQL 15 不使用生成内存上下文进行有界排序。例如,带有 ORDER BY 和 LIMIT N 子句的查询。此处未使用优化的原因是有界排序仅存储前 N 个元组。一旦获取了 N 条记录,PostgreSQL 将开始丢弃超出范围的元组。丢弃元组需要释放内存。PostgreSQL 无法提前确定释放元组的顺序。如果生成内存上下文用于有界排序,它可能会浪费大量内存。
有关详细信息,请参阅 https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=40af10b57
变化 3:为常见数据类型添加专门的排序例程
使用经过调整的快速排序算法在 PostgreSQL 中完成排序。PostgreSQL 有大量不同的数据类型,用户甚至可以自行扩展。每种数据类型都有一个比较函数,该函数提供给快速排序算法以在比较 2 个值时使用。比较函数返回负数、0 或正数以说明哪个值更高或它们是否相等。
使用这个比较函数的问题是,要执行排序,PostgreSQL 必须多次调用该函数。
- 在平均情况下,当对 10,000 条记录进行排序时,PostgreSQL 需要调用比较函数 O(n log2 n) 次。也就是大约 13.2 万次。
- 对 100 万条记录进行排序时,平均比较次数约为 2000 万。
PostgreSQL 是用 C 编程语言编写的——虽然 C 函数调用开销很低,但 C 函数调用不是免费的。多次调用函数会产生明显的开销,尤其是在和它自己原本开销很低的情况比较更为明显。
此处所做的更改添加了一组新的快速排序函数,这些函数适合一些常见的数据类型。这些快速排序函数具有内联编译的比较函数,以消除函数调用开销。
如果您想检查您在 PostgreSQL 15 中排序的数据类型是否使用这些新的快速排序函数之一,您可以执行以下操作:
set client_min_messages TO 'debug1';
并运行您的 SQL 查询:
explain analyze select x from test order by x;
如果您的调试消息显示:
- qsort_tuple_unsigned
- qsort_tuple_signed
- qsort_tuple_int32
那么你很幸运。如果调试消息显示其他内容,则排序使用原始(较慢)快速排序功能。
添加的 3 个专业化快速排序不仅仅涵盖整数类型。这些新到 PostgreSQL 15 的函数还涵盖了时间戳和所有使用缩写键的数据类型,其中包括使用 C 排序规则的 TEXT 类型。
让我们看一下排序专业化函数带来的性能提升。我们可以通过在查询中添加 LIMIT 子句来欺骗 PostgreSQL 的执行程序,使其不应用变化 2 的优化。
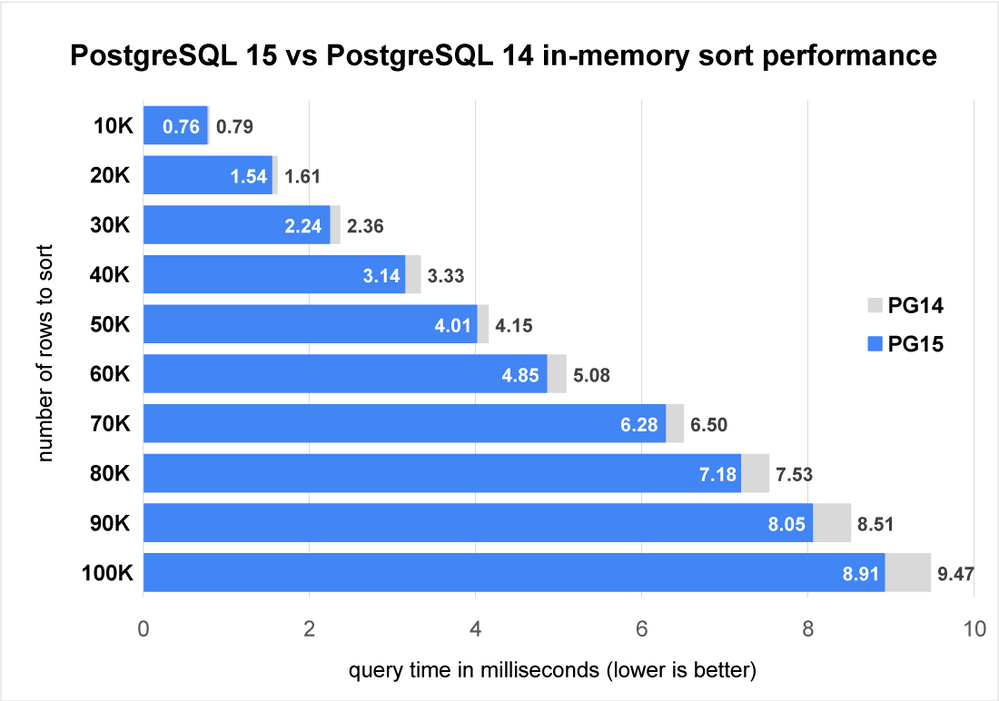
图 3:图表显示 PostgreSQL 15 的内存排序性能提高了 4% 到 6%。
在这里我们可以看到,在这种小规模排序中,性能确实会随着排序的更多行而提高。这是符合预期的,因为排序专业化这个更改减少了排序期间比较元组的常数因子。平均而言,对更多记录进行排序需要对每条记录进行更多比较。因此,我们可以看到大量记录带来更大的节省。这些加速仅适用于 CPU 缓存效果由于更频繁的 CPU 缓存未命中而导致性能再次下降之前。
有关详细信息,请参阅 https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=697492434
变化4:用多路归并 (k-way merge)代替多阶段合并 (Polyphase Merge)算法
最后的变化是针对work_mem明显超过大小的更大规模的排序。合并单个磁带的算法已更改为使用多路归并 (k-way merge)。当磁带数量很大时,所需的 I/O 比原来的多阶段合并 (Polyphase Merge)要少。
让我们做一些基准测试,看看合并算法的变化如何影响 PostgreSQL 15 的性能。
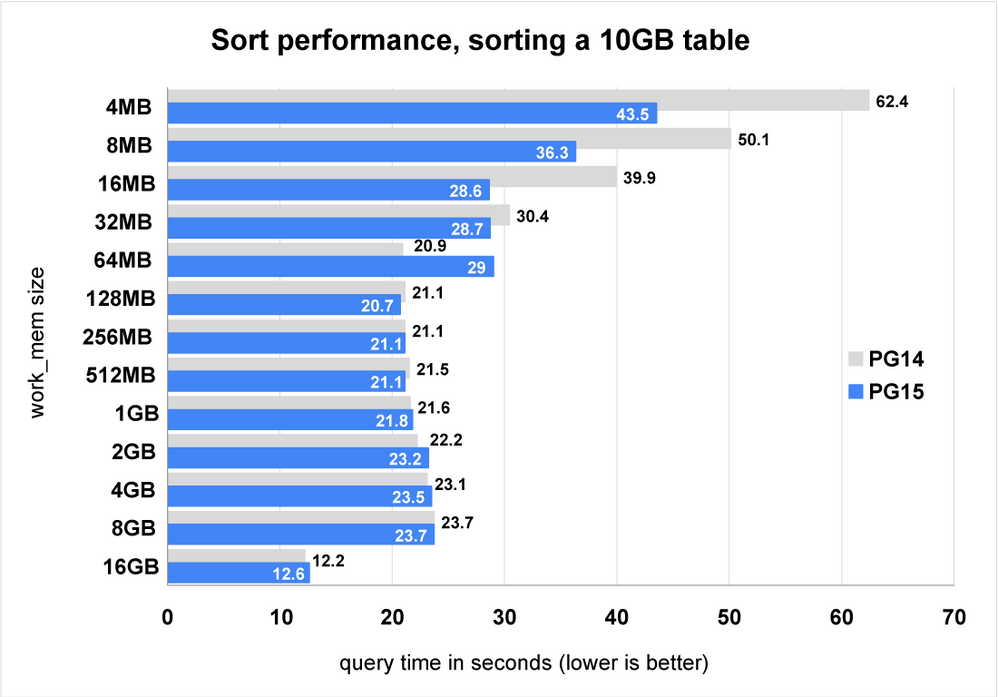
图 4:图表显示 PostgreSQL 15 对大型排序的执行速度提高了 43%。
上面的图 4 向我们展示了 PostgreSQL 15 在具有非常小的work_mem. 随着work_mem设置的增加,性能差距缩小。使用最大值work_mem(16GB) 时,排序不再溢出到磁盘。我们还可以看到work_mem设置为 64MB 的测试导致查询运行更慢。这需要在 PostgreSQL 15 发布之前进行一些进一步的调查。
有关详细信息,请参阅 https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=65014000b
Postgres 中sort未来的工作
我们很可能会在未来的 PostgreSQL 版本中看到排序函数专业化领域的进一步改进。例如,当 PostgreSQL 在排序期间比较两个值时,它需要检查 NULL。这对于几个值来说花销是很小的,但请记住,这种比较必须进行多次。比较的成本迅速增加。如果 PostgreSQL 在存储记录时通过检查它们已经知道不存在 NULL,那么在比较两条记录以进行排序时就不需要检查 NULL。许多列都有 NOT NULL 约束,因此这种情况应该很常见。PostgreSQL 也可以使用 NOT NULL 约束作为证明,这样它就不必在运行时检查 NULL。
为什么不立即尝试 PostgreSQL 15,看看这些变化如何影响您的负载?
我在减少排序的内存消耗时运行的第一个测试将性能提高了 371%。这是由于存储要排序的记录所需的内存消耗减少,不再超出我的work_mem设置。以前排序溢出到磁盘,更改后整个排序在内存中完成。
在 PostgreSQL 上运行的许多 SQL 查询都需要对记录进行排序。在 PostgreSQL 15 中使排序速度更快可能会使您的许多查询比在 PG 14 上更快。
如果您想在 PostgreSQL 15 中提供排序性能,请尝试:
- PostgreSQL 15的发行说明现已上线
- PostgreSQL 15 beta 1 于 2022 年 5 月 19日发布(随后几个月将发布“候选发布”版本)
- PostgreSQL 15 的最终版本将于 2022 年 10 月/11 月左右发布
- 您可以在此处下载 PostgreSQL 15 beta 1
