





上周写过一篇关于PG锁的文章,不过只是开了个头,并没有做深入的探讨。如果你理解了PG的PG_LOCKS表,那么对于PG的应用相关的锁也不难理解,比如我们打交道最多的PG事务锁。
对于PG数据库来说,事务锁的类型是transactionid,似乎刚刚看到这个名字的时候觉得有点费解。不过其实PG的事务锁锁定的就是事务号,通过事务号实现锁的互斥操作实际上在大多数数据库里都是类似的,只是其他数据库都称之为事务锁,而PG成为针对TransactionId的对象锁,以Oracle为例,Oracle的事务锁TX锁实际上也是指向了一个事务。不过PG的事务号还有一些让人觉得有点不容易理解的东西。我们来看一个例子,首先我们登录一个PG数据库,然后执行下面的查询语句:
SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted FROM pg_locks WHERE pid = pg_backend_pid();
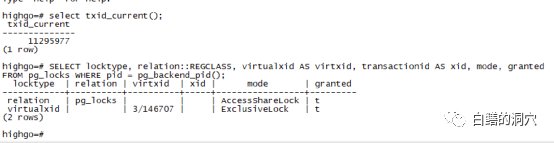

因此对于此类事务,只需要一个虚拟的XID,让这个虚拟xid只要在某个时间段内是唯一的,不会引起冲突就行了,这个虚拟XID不会被记录在CLOG中,因此PG采用了上面的这个数据结构来实现。
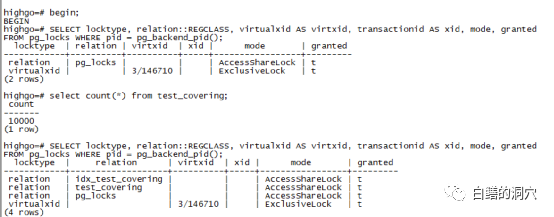
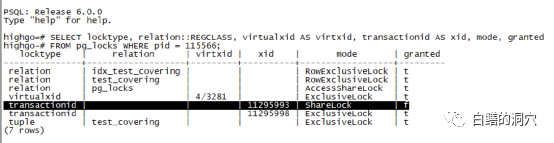
PostgreSQL 将行锁排他性地存储在数据页内的行版本中而不是存储在共享内存里。这意味着它不是通常意义上的锁,而只是一些TUPLE中的标识。实际上PG使用在tuple的XMAX字段上实现行锁(Oracle则更为节省,使用行头里的一个表示位)。这种实现方式的优点是我们可以在不消耗任何资源的情况下锁定任意数量的行。有利必有弊,由于锁的信息没有存储在共享内存中,其他会话要排队等待该行锁的时候,需要一些其他的算法来辅助实现,同时如果我们想查询哪些行被锁定了,就必须从PAGE中去统计了。这种锁的算法的另外一个副作用就是在DML增加了一个tuple类型的排它锁,这就是我们上面看到的情况。
如果某个会话需要等待某个行锁被释放,PG并不会等待这个行的行锁,而是需要等到锁定事务完成:所有锁在事务提交或回滚时被释放。并且为此,我们可以在锁定事务的 ID 上请求一个锁。因此,使用的锁数与同时运行的进程数成正比,而不是与正在更新的行数成正比。
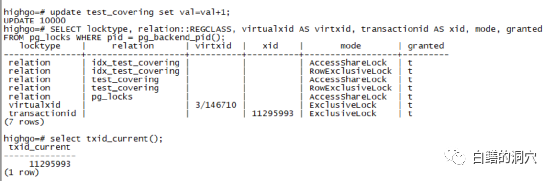
元组锁(Tuple)是和数据行上的DML操作有关的锁,但是并不是行锁,上面一段已经说明了,行锁是通过元组里的XMAX和INFOMASK等来实现的。元组锁(TUPLE)是元组对象上的锁。那么元组锁是怎么产生的呢?这和DML的行锁实现有关。当事务要更改行时,它会执行以下步骤序列:
1)获取要更新的元组的排他锁;
2)如果 xmax 和信息位显示该行已锁定,则请求锁定 xmax 事务 ID(此时会产生TransactionId锁的等待请求);
3)写入自己的 xmax 并设置所需的信息位;
4)释放元组锁。
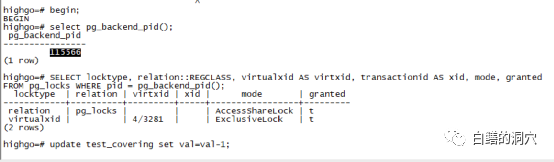
当第一个事务更新行时,它也获得了一个元组锁(步骤 1),但立即释放它(步骤 4)。当第二个事务到达时,它获得了一个元组锁(第 1 步,因为已经第一个会话被释放,所以能够直接获得),但通过XMAX发现该元组已经被会话一的事务锁定,不得不在这个事务的 ID 上请求一个TransactionId锁(第 2 步),并把这个操作挂起了。如果出现第三次类似的交易会怎样?它将尝试获取元组锁(第 1 步),因为这个tuple锁已经被会话二持有,因此会话三无法获得tuple锁,因此会直接挂起。我们可以通过做个实验来验证这个步骤。
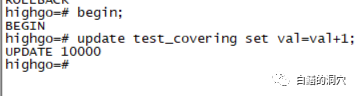
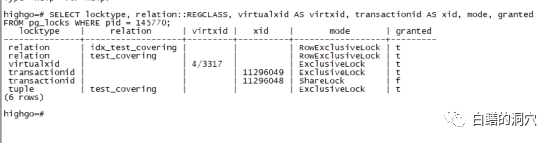

我们可以看到第三个会话的锁的数量和类型都和会话二类似,不过区别是等待的位置不同,这个会话并不是在等待TransactionId锁,而是在等待tuple锁。
至此行锁、tuple锁、事务锁、虚拟事务锁这几个概念都介绍完了,我想大家看到这里已经基本上了解了PG事务锁的实现方式。关于行锁的实现,以前老白写过几篇文章,大家有兴趣可以在公众号上查阅。
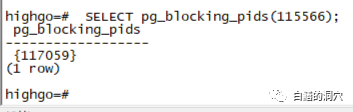
通过今天的分析,可能大家再去看pg_locks是不是更容易一些了呢?



文章转载自开源软件联盟PostgreSQL分会,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
