





GBase UP技术白皮书,南大通用数据技术股份有限公司
GBase 8a UP (统一数据平台)
技术白皮书
GBase版权所有©2004-2016,保留所有权利。
版权声明
本文档所涉及的软件著作权、版权和知识产权已依法进行了相关注册、登记,由南大通用数据技术股份有限公司合法拥有,受《中华人民共和国著作权法》、《计算机软件保护条例》、《知识产权保护条例》和相关国际版权条约、法律、法规以及其它知识产权法律和条约的保护。未经授权许可,不得非法使用。
免责声明
本文档包含的南大通用公司的版权信息由南大通用公司合法拥有,受法律的保护,南大通用公司对本文档可能涉及到的非南大通用公司的信息不承担任何责任。在法律允许的范围内,您可以查阅,并仅能够在《中华人民共和国著作权法》规定的合法范围内复制和打印本文档。任何单位和个人未经南大通用公司书面授权许可,不得使用、修改、再发布本文档的任何部分和内容,否则将视为侵权,南大通用公司具有依法追究其责任的权利。
本文档中包含的信息如有更新,恕不另行通知。您对本文档的任何问题,可直接向南大通用数据技术股份有限公司告知或查询。
未经本公司明确授予的任何权利均予保留。
通讯方式
南大通用数据技术股份有限公司
天津华苑产业区海泰发展六道6号海泰绿色产业基地J座(300384)
电话:400-013-9696 邮箱:info@gbase.cn
商标声明

目 录
GBase UP统一数据平台产品简介
产品简介
南大通用统一数据平台系统,简称:GBase UP,它是融合了GBase 8a MPP、GBase 8t、开源Hadoop生态系统的大数据平台产品,兼顾大规模分布式并行数据库集群系统、稳定高效的事务数据库,以及Hadoop生态系统的多种大规模结构化与非结构化数据处理技术,能够适应OLAP、OLTP和NOSQL三种计算模型的业务场景,是构建企业数据平台的重要基础设施。
GBase UP以成熟的GBase 8a MPP商用数据库为基础,扩展出针对Hive & Spark、HBase、GBase 8t的计算和存储引擎,建立引擎之间高效数据交换通道,构建了对外统一,对内可扩展的集群数据库产品。
对于企业而言,GBase UP建立了一个多种数据存储和混搭计算的基础设施,将存储资源和计算资源合理调配,破除数据竖井,通过统一接口完成数据的加工生产,从而创造更多的数据价值;对于信息集成厂商,GBase UP提供了能够处理结构化数据和非结构化数据、关系型和非关系型数据的一站式解决方案。对于最终用户和App开发者而言,GBase UP为用户提供经典的数据库接入方式和结构化查询语言,从而大大降低维护和开发成本。
与数据网关、数据库代理&路由、中间件等方案不同:GBaseUP是一款分布式数据库集群产品,对外构建完整的Schema定义和数据库访问控制,能够对用户数据库访问进行解析、优化、数据缓冲等操作,完成透明高效的中间数据存储、关联、聚合等操作,对内构建Gbase 8a MPP、GBase 8t、Hadoop之间的内部数据传输协议,实现高效的数据交换,构建统一的监视和控制系统,进行资源调度。为用户提供高效的、易管理的、总体拥有成本低的产品和服务。
借助GBase UP,企业可以在实施大数据项目时实现四减二增,四减:在项目前期避免陷入MPP数据库和Hadoop生态的选型困难,减少决策成本;在系统业务信息架构阶段,借助统一模式,减少业务建模成本;在应用开发阶段,开发者采用标准的ODBC、JDBC等传统方式访问平台,减少开发成本;在项目交付后,通过统一的监控系统,减少运营成本;二增:破除数据孤岛,打破“竖井”型数据中心间的隔离,实现数据增值;融合MPP和Hadoop各自计算能力,实现计算增值。
产品技术特点
GBase UP继承了GBase 8a MPP的Shared Nothing节点对等的扁平架构,能够运行在普通的X86服务器上,同时还具备以下技术特征:
- 统一的标准化接入:支持C API、ODBC、JDBC、ADO.NET等接口规范。
- 统一的标准化查询语言:支持SQL92标准,并在此基础上支持HiveHQL、GBase 8t的SQL扩展,DDL部分支持方言,DML尽可能采用标准SQL。
- 统一的数据视图:通过统一的元数据管理,将OLTP、OLAP、Hadoop数据库可以看作一个视图,供数据建模工程师构建统一的信息的生产流程。
- 统一安全:基于GBase 8a MPP的安全体系,扩展对其他引擎的安全认证,避免了多种认证模式,弥补如HIVE等对安全实现不足的短板。
- 统一事务:支持跨异构集群的事务管理。
- 统一调度:透明实现跨引擎关联查询。
- 统一日志:增加保存日志到hadoop的机制,供诸多分析工具访问。
- 统一监控:监视UP平台的各个服务器的软硬件指标。
- 高效数据交换:内置引擎之间建立高速多对多的内部通道。
- 高可扩展性,GBase 8a MPP、GBase 8t、Hive是GBase UP的内置引擎,还可以通过开发对应的扩展插件实现各层的扩展。
- 数据生命周期管理:根据数据在不同时期的存储和计算特征,实现跨异构引擎的数据分区功能,实现数据透明的跨分区访问和在线迁移。
- 增强的管理能力:数据通过副本提供冗余保护,自动故障探测和管理,自动同步元数据和业务数据。提供图形化工具,对GBase 8t、GBase 8a MPP和Hadoop生态提供统一的管理工作。
产品功能简介
功 能 | 描 述 |
|---|---|
结构化查询语言 | 符合SQL 92标准,支持CREATE、ALTER、DROP等DDL语法,支持SELECT、INSERT、UPDATE、DELETE、MERGE等DML语法,支持单表,多表联合查询。 支持HiveQL的扩展语法。 |
数据类型 | INT、TINYINT、SMALLINT、BIGINT、DECIMAL、FLOAT、DOUBLE数值数据类型 CHAR、VARCHAR、TEXT字符数据类型 DATE、TIME、DATETIME、TIMESTAMP日期类型 BLOB二进制数据类型 |
数据库对象 | 提供了数据库,表,索引,视图,存储过程,自定义函数等常用数据库对象的创建,修改和删除操作,支持数据库用户的创建,删除操作,以及用户权限的分配与回收 |
融合GBase 8t | 支持完整高效的事务数据的存储、计算和事务管理、支持时间序列、地理信息系统等特殊业务场景。 |
融合Hadoop生态 | 支持以Spark为引擎的Hive,实现低质量低密度大数据量的Hadoop数据仓库;支持HBase,配合HDFS实现海量中小文件的存储方案。 |
图形化工具 | 提供了企业管理工具和集群监控工具。 |
接口 | 符合并支持C API、ODBC、JDBC、ADO.NET等接口规范 |
GBase UP系统架构
混搭集群

图 2-1 GBase UP部署示意图
GBase UP是以GBase 8a MPP最新超大规模集群版本为基础,融合GBase 8t和Hadoop Hive/Spark,实际部署时可以理解为5个小集群/集合,其中:GBaseUP负责连接接入,元数据管理,跨集群查询调度,安全认证,日志记录等一系列分布式数据库的功能;GBase 8a集群(集合)负责高质量高密度高性能的数据存储和计算;Gbase 8t负责支撑高端事务处理;Hive集群负责驱动Hadoop或Spark集群实现对低密度、低质量、结构化/非结构化的大数据进行分析;Hadoop集群的HDFS负责高效高可用的存储海量数据,HBase负责存储海量中小文件,以及作为分布式可扩展的KV型数据仓库。
最小部署
在没有单点故障的前提下,最小规模部署模式需要7台服务器(如果不需要GBase 8t,则仅需5台服务器),如下图所示,服务器由万兆网连接,编号分别为s1、s2、s3、s4、s5、s6和s7。

图 2-2 没有单点故障的最小部署
7台服务器上部署的软件列表如下:
类型 | 运行程序或服务 | s1 | s2 | s3 | s4 | s5 | s6 | s7 |
GBase 8a MPP | gclusterd | ● | ● | ● |
|
|
|
|
gbased | ● | ● | ● |
|
|
|
| |
corosync | ● | ● | ● |
|
|
|
| |
gc_sync_server | ● | ● | ● |
|
|
|
| |
gcrecover | ● | ● | ● |
|
|
|
| |
GBase 8t | 8t相关服务 |
|
|
|
|
| ● | ● |
hadoop | NameNode | ● | ● |
|
|
|
|
|
Journalnode | ● | ● |
|
|
|
|
| |
Datanode | ● | ● | ● | |||||
DFSZKFailoverController | ● | ● |
|
|
|
|
| |
yarn | ResourceManager | ● | ● |
|
|
|
|
|
NodeManager |
|
| ● | ● | ● |
|
| |
zookeeper | ZookeeperMain | ● |
|
|
|
|
|
|
QuorumPeerMain | ● | ● | ● | ● | ● |
|
| |
hbase | HMaster |
|
|
| ● | ● |
|
|
ThriftServer |
|
|
| ● | ● |
|
| |
HRegionServer | ● | ● | ● |
|
|
|
| |
spark | Worker | ● |
| ● | ● |
|
|
|
| Master |
| ● |
|
| ● |
|
|
hive | HiveServer2 | ● | ● |
|
|
|
|
|
mysql | mysqld | ● | ● |
|
|
|
|
|
monitor | gmetad | ● | ● | ● | ● | ● | ● | ● |
gmond | ● | ● | ● | ● | ● | ● | ● | |
nagios | ● | ● |
|
|
|
|
|
注:Hadoop生态内容变化较快,其中的列表会随着相关系统稳定版的发行而变化。
整体架构
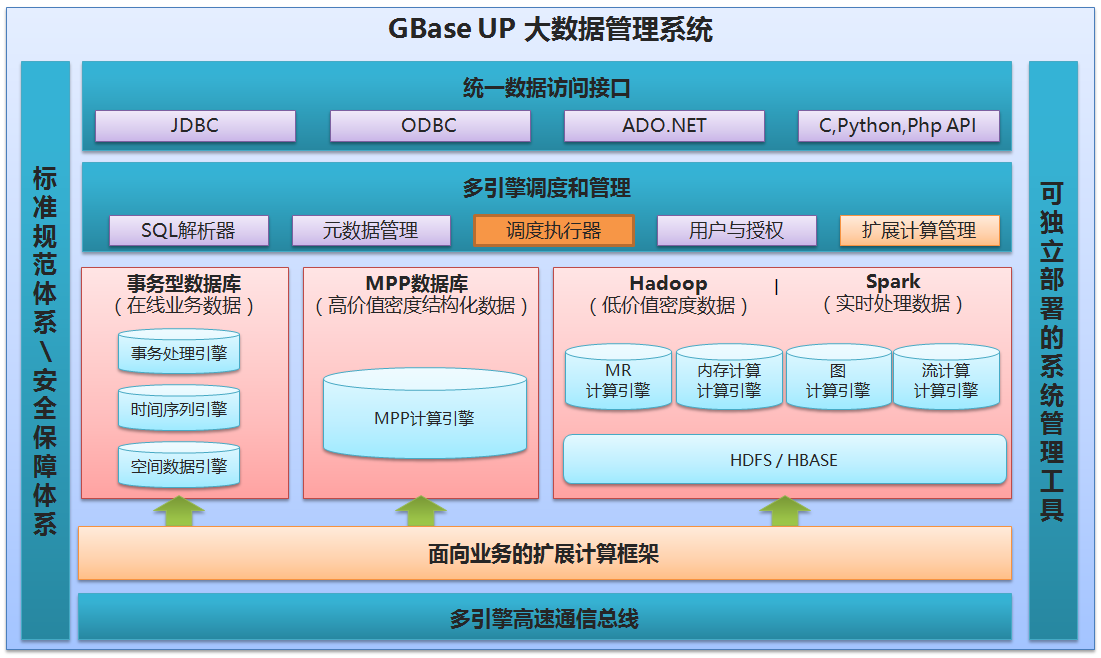
图 2-3 GBase UP系统架构图
整体系统分作6大模块:
1.统一数据访问接口,建立标准接入层和规划可扩展的查询语言;
2.多引擎的调度和管理,包含解析标准SQL和各处理引擎的SQL方言,借助强一致性的元数据管理,用户授权管理,最终实现基于规则和基于代价的高效的跨引擎关联查询;
3.高可扩展的面向业务的扩展计算架构,结合Linux容器技术、数据库扩展用户自定义函数,实现处理关系数据、图数据、KV数据和非结构化数据的计算引擎的计算能力的融合与扩展;
4.基于分布式文件系统(DFS)、远程直接数据存取(RDMA)等先进技术的数据路由和交换功能,构建多引擎间的高速通讯总线。
5.数据库企业管理器集合Hadoop生态的部署、监控工具,提供完整的部署、监控、调优、诊断等管理功能。
6.通过GBase 8a MPP完备的安全机制,增强各处理引擎的安全管理。
支持的操作系统和平台
支持如下的操作系统和平台:
- CentOS 6.X
- Red Hat Enterprise Linux 6.x
- SUSE 11.x
硬件环境
- 支持基于x86_64的标准PC服务器;
- 支持本地存储(SATA、SAS、SSD etc);
- 支持阵列部署(SAN、NAS);
- 支持SSD、Flash存储介质作为二级I/O缓存;
- 支持千兆、万兆 Ethernet网络;
- 支持InfiniBand网络。
技术指标
技术指标 | 描 述 |
|---|---|
数字精度 | 65 |
表的个数 | 每个数据库 65536 |
每个表中列的个数 | 2000 |
每个表中行的个数 | 247 |
表中一行的内部长度 | 300000字节 |
一个INTEGER类型列的长度 | 8字节 |
日期类型列中表示年的位数 | 4位 |
用户名包含字符的个数 | 16字符 |
CHAR类型列的长度 | 255字符 |
BLOB列的长度 | 32K字节,URI扩展类型最大16G |
VARCHAR类型列长度 | 32K字节,URI扩展类型最大16G |
行存列的长度 | 最长16G字节 |
数据库名长度 | 64字符 |
表名长度 | 56字符 |
列名长度 | 64字符 |
索引名长度 | 64字符 |
别名长度 | 255字符 |
注:不同的计算引擎有不同的参数指标,本表以GBase 8a MPP引擎为参考。
GBase UP核心技术与核心价值
异构引擎透明访问
GBase UP数据平台中GBase 8a MPP、GBase 8t、Hive on Spark都是数据存储和数据计算的引擎,DBA可以将各种引擎构建为统一的Schema,对于普通的用户的DML查询,引擎是透明的。
扩展标准SQL DDL中的创建表的语法:
创建表
CREATE [TEMPORARY] TABLE [IF NOT EXISTS]
[database_name.] table_name
(column_definition [,column_definition], ... [, key_options])
[table_options];
其中
table_options:
[DEFAULT] Engine = GBase8a| GBase8t|Hive
| SQL 92 create table options
| GBase 8a create table options方言
| GBase 8t create table options方言
| Hive create table options方言
即DBA创建数据表时,可以通过Engine关键字设置表的存储引擎。应用开发工程师,编写数据读写时,无需关注数据表的引擎,采用标准SQL92 DML访问,从而简化应用开发,降低数据建模的复杂度。
跨引擎数据交换
对于混搭架构的应用而言,数据清洗和历史数据管理是最常见的业务场景。从Hadoop中执行复杂的信息分析算法,从大规模,低价值数据中抽取大规模高价值数据,接着存入MPP数据库进行高性能分析。以及在MPP的数据按时间或者其他条件逐渐老化,将部分“冷数据”转存到低成本的Hadoop集群,在必要时进行历史数据查询。
在GBase UP中,数据清洗和历史数据管理就可以分别简化为:
代码示意:
Insert into t_8a select …(单表或者复杂多表查询)
Insert into t_hive select …(单表或者复杂多表查询)
UP的核心技术是构建引擎间高吞吐率的多对多通讯机制,通过底层的数据交换,实现引擎间高效的数据迁移。
跨引擎关联查询
与数据清洗和历史数据管理相比,更加灵活的业务场景是:实时进行跨引擎的关联查询。如最简单的:
代码示意:
Select * from t_8a inner join t_hive on t_8a.no = t_hive.no where …
其中t_8a为8a mpp 数据引擎表,t_hive为Hadoop hive 引擎表。
GBaseUP构建了基于规则和成本的优化器,能够既充分利用各自引擎的特色运算,又能保证在引擎间交互的数据最小化,同时利用高效的数据交换总线,从而实现自动优化的引擎间实时关联分析。
DML操作的事务管理依赖具体引擎,如果每个引擎都支持标准的XA,则GBase UP整体支持事务,当前GBase 8t支持XA,而GBase 8aMPP和Hive虽然都支持ACID,但是都不支持XA,所以在单引擎操作时GBase 8a MPP支持多语句长事务,Hive支持单语句事务,混合引擎交互写操作时采用自动提交当前事务的模式。
跨引擎读写分离
当一个数据模型同时大量读、写操作并发执行时,读写操作互相影响,会加剧对锁的竞争,导致整体性能下降。通过在GBase UP中引入引擎级别的读写分离机制,可以极大地缓解并发读写对锁的竞争,从而提高并发性能。引擎级别读写分离的基本原理是,GBase UP作为统一的访问入口,对读写请求进行调度,事务性操作(INSERT、UPDATE和DELETE)在GBase 8t上执行,SELECT查询关键是分析型计算在GBase 8a上执行,以充分利用GBase 8t和GBase 8a各自的优点。
代码示意:
-- 创建镜像表,镜像方向为GBase8t到GBase 8a MPP
Create table t(...) engine=‘Mirror8t8a’;
-- 写操作用8t引擎
Insert into t values(…);
-- 分析型查询用8a引擎
Select avg(…) from t group by …;
查询操作指向到8a的方式有两种:自动识别,根据语句中函数的类型,如OLAP函数;手动识别,用户session级变量和hint级变量,影响到语句的执行引擎。
数据生命周期管理
数据在各生命周期有不同的处理要求,尤其是时间序列数据,其业务场景常常是初期集中于OLTP,中期用于OLAP,后期很少使用,只是偶尔用于历史数据分析,整体呈现热、温、冷三种典型的处理模型,从存储成本和计算特征考虑,不同时期的数据采用不同的引擎存储。
最常见的一种情况,最近生成的数据会被频繁使用和修改,将其存放在GBase 8t中,将近期生成但不再更新的数据放在GBase 8a中,将历史数据放在Hive中。用户通过SQL透明读写,而GBase UP按照设定的数据迁移策略后台自动透明的高效迁移。
代码示意: 创建分区表,按热、温、冷分别存储在三个数据引擎
Create table t_part (…, in_date date) partition by range(in_date)
(partition p_hive values less than (date_sub(current_date(),interval 1 month)) engine=‘Hive’,
partition p_8a values less than (date_sub(current_date(),interval 1 week)) engine=‘GBase8a’,
partition p_8t values less than MAXVALUE engine=‘GBase8t’);
统一用户管理和授权
统一平台必须支持统一的用户管理和授权,但是各引擎之间可能差异很大,如GBase 8a MPP和Hive:
Hive授权有user、group、role三个维度,权限有8项ALTER ,CREATE, DROP, INDEX, LOCK, SELECT, SHOW_DATABASE,UPDATE,但Hive并无create user或create group语句,而是有create role,drop role等语句。
GBase 8a MPP的按SQL92标准,有user的create、drop、show 、rename,set password授权范围全局、库、表、字段共四级,授权项有ALL [PRIVILEGES],ALTER,ALTER ROUTINE,CREATE,CREATE ROUTINE, CREATE TEMPORARY TABLES ,CREATE USER, CREATE VIEW, DELETE, DROP,EXECUTE, FILE, GRANT OPTION,INDEX,INSERT,PROCESS,RELOAD,SELECT,SHOW DATABASES,SHOW VIEW,UPDATE,USAGE共25项。
从用户角度,GBaseUP采用GBase 8a MPP的用户管理和授权模式,逐步融合Hive,GBase 8t的特色模式。
BLOB on Hadoop
采用HBASE和HDFS存储海量中小文件是近几年成熟起来的方案,GBase UP内部融合此方案,同时更加灵活,具体是扩展 BLOB类型,增加 URI模式,使其能够存储从微博、微信的图片到一张DVD 9的电影。即将BLOB URI作为GBase 8a MPP访问外部数据的一种方式,即在8a中存储URI字符串,实际数据在URI标识的访问位置,同时有Last Modi,Content Length、MD5等校验手段保证数据的一致性和完整性。

图 4-1 Cache和存储
APP 采用JDBC、CAPI与UP相连接,可以通过正常的预处理查询模式读写BLOB字段,大大简化开发的复杂度。同时借助内存、磁盘、HDFS临时目录的模式兼顾事务原子性和执行效率。
UDF扩展
用户定义函数(UDF User defined Function)扩展是由第三方开发的特定算法模型引入到数据库系统的常见方式,在UP中,将关系数据库、图数据库、KV数据库等数据库引擎的内置函数和UDF都可以作为UP的UDF函数,实现数据和算子的融合,存储各个引擎的数据可以借助其他引擎的算子进行交互计算,支持上下文无关运算和上下文相关的聚合计算,计算参数和结果可以是字段也可以是表对象。考虑到UDF的占用资源和稳定性,建立UDF沙盒容器,控制容器的资源占用,监视其稳定性,当资源可控和保证稳定性后,可以考虑将UDF移入数据库管理系统以提高运行效率。
代码示意:
Create table t1_oltp(website varchar(200), clickcount number(10)…) engine=‘GBase8t’;
Create table t2_hive(key bigint, url varchar(1000), weichat varchar(5000), …) engine=‘Hive’;
Insert into t2_hive … ;
-- 注册用户自定义函数
Create function extractwebsite returns string soname ‘hive_common.so’;
-- SQL中调用自定义函数
Insert into t1_oltp(website,clickcount) select extractwebsite(url), count(*) from t2_hive;
Hive、Spark、GBase 8t的内置专有函数和UDF扩展函数,都可以通过注册的方式引入到UP,作为UP层的UDF函数在SQL中调用。
GBase UP开发接口
GBase UP ODBC
GBase UP ODBC是访问GBase UP的ODBC驱动程序,它提供了访问 GBase UP的所有ODBC功能。GBase UP ODBC支持ODBC 3.5X 一级规范 (全部API + 2级特性)。用户可以通过ODBC数据源管理器调用GBase UP ODBC驱动访问GBase UP数据平台或者直接调用 GBase UP ODBC 驱动访问 GBase UP ,另外通过可视化编程工具如 C++ Builder、 Visual Studio 等也可以利用 GBase UP ODBC 访问。GBase UP ODBC支持所有主流的 Windows、Linux 、AIX版本。
GBase UP JDBC
GBase UP JDBC是一种兼容JDBC规范3.0、4.0 (类型4)的驱动,这意味着它是符合JDBC 3.0、4.0版本规范的一种纯Java程序,并能使用GBase协议直接和GBase数据平台通信。
GBase UP JDBC为使用JAVA程序语言的客户端应用提供访问GBase UP接口。
- GBase UP JDBC 支持JDBC规范3.0、4.0版本;
- GBase UP JDBC 使用 GBase 内部协议直接和 GBase UP 平台通信;
- GBase UP JDBC在 Sun’s JDBC 实验平台上通过率达到95%。
GBase UP ADO.NET
GBase UP ADO.NET 是一款提供.NET应用程序与GBase数据平台之间方便、高效、安全交互的接口程序,使用100%纯C#编写,并继承了Microsoft ADO.NET 类。开发人员可以使用任何一种.NET开发语言(C#、VB.NET、F#)通过GBase UP ADO.NET操作GBase数据平台。
GBase UP ADO.NET支持以下全部特性:
- 支持集群高可用功能、负载均衡功能;
- 支持GBase 数据库全部特性,如:存储过程、视图等;
- 支持协议压缩,允许对客户端和服务器之间交互的数据流进行压缩;
- 支持Windows平台下的TCP/IP套接字连接;
- 支持Linux平台下的TCP/IP套接字或Linux套接字连接;
- 无需安装GBase 数据平台的客户端,可通过GBase UP ADO.NET类库实现完整的管理功能。
GBase UP C API
GBase UP C API是GBase UP数据平台提供的C语言访问库。应用可以通过调用GBase CAPI访问 GBase UP数据平台。GBase CAPI提供了如下功能:
- 创建和断开客户端与服务器的连接;
- 直接执行SQL语句;
- 通过预处理模式操作数据库;
- 获取执行SQL的结果集;
- 获取错误信息。

