





(本文阅读预计时间:5分钟)
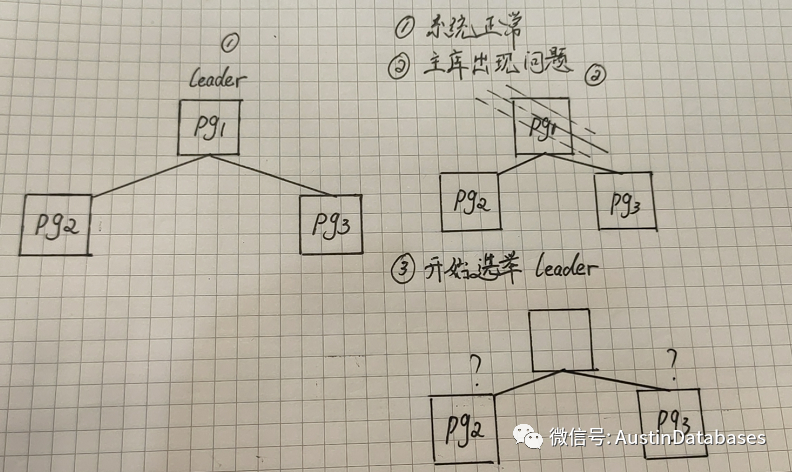
Patroni系列已经写到第五期了,首先先说为什么要有watchdog,如图,如果我们的系统在运行是出现问题,节点PG1失效了,无论是网络的问题,还是主机本身的问题,此时都是要进行重新选举,问题就产生在3开始选举leader。
上期说配置文件的时候
loop_wait: the number of seconds the loop will sleep. Default value: 10 ttl: the TTL to acquire the leader lock (in seconds). Think of it as the length of time before initiation of the automatic failover process. Default value: 30 retry_timeout: timeout for DCS and PostgreSQL operation retries (in seconds). DCS or network issues shorter than this will not cause Patroni to demote the leader. Default value: 10
还得祭出这三条:
loop_wait ttl retry_timeout
已默认值来说一个节点的切换10+30+10是最大的时间,但实际上会有另一个问题。在选举中,此时所有节点包含失效的节点都会出现一个问题:此时没有节点是leader,数据写入的需求是怎么处理的问题。

未了避免脑裂,Patroni需要确认postgresql不能在leader键值在DCS过期后继续接受事务的commit,在patroni无法进行leader lock后,则patroni将开始试图停止postgresql的方式来保证此期间不会有脑裂的问题。
watchdog的主要产生的原因是,如果patroni无法在此刻关闭postgresql怎么办?因为patroni也不是"孙悟空",也是人肉一枚,如果由于各种原因导致patroni本身无法工作,watchdog将尝试重新启动系统。如果工作后,无论怎样patroni还是无法正常工作,则watchdog模式如果设置成required,则这个所在的问题节点是不能成为leader的。当整体选举leader成功后,patroni将会让watchdog进入休眠的状态。
但在设计watchdog时会有一个问题,因为设计时差的问题,导致watchdog本身无法获得patroni发送的信息。最终在这个工作周期无法激活watchdog。这个时间的设定较safety margin官方给出的建议并不明确。只提到了watchdog timeout调整到ttl的一半时间,确保watchdog能受到信息,从对loop_wait和retry_timeout入手。

默认使用patroni的数据库机器需要执行
modprobe softdog
chown postgres/dev/watchdog
这里大部分使用的是Linux本身的watchdog
关于watchdog有三个设置
watchdog:
mode:Allowed values:off,automatic,required
mode的值有三个
1.off不运行watchdog。
2.automatic根据设置的情况,默认使用watchdog,但如果配置出现问题、watchdog出现问题则不使用watchdog。
3.required必须使用watchdog否则无法选择leader。
device:/dev/watchdog
4.watchdog设备本身
safety_margin:





PostgreSQL与Oracle:成本、易用性和功能上的差异



