




什么是可观测性
可观测性(Observability)与 可控制性(Controllability)一起,是由匈牙利数学家 Rudolf E. Kálmán 针对线性动态控制系统提出的一组对偶属性,原本的含义是“可以由其外部输出推断其内部状态的程度”。
控制理论中的可观察性(observability)是指系统可以由其外部输出推断其其内部状态的程度。系统的可观察性和可控制性是数学上对偶的概念。可观察性最早是匈牙利裔工程师鲁道夫·卡尔曼针对线性动态系统提出的概念。若以信号流图来看,若所有的内部状态都可以输出到输出信号,此系统即有可观察性。
学术界一般会将可观测性分解为三个更具体方向进行研究,分别是:事件日志、链路追踪和聚合度量。在 2017 年的分布式追踪峰会(2017 Distributed Tracing Summit)后,Peter Bourgon 撰写了总结文章《Metrics, Tracing, and Logging》系统地阐述了这三者的定义、特征,以及它们之间的关系与差异,受到了业界的广泛认可。
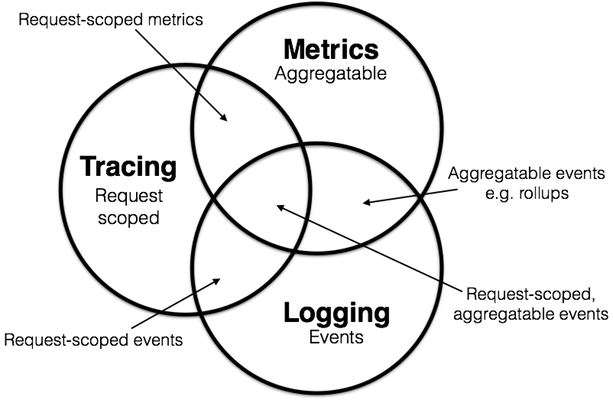
图 1 日志、追踪、度量的目标与结合
按照 Peter Bourgon 给出的定义来看,尽管分布式系统中追踪和度量必要性和复杂程度确实比单体系统时要更高,但是在单体时代,你肯定也已经接触过以上全部三项的工作:
-
日志(Logging):日志的职责是记录离散事件,通过这些记录事后分析出程序的行为,譬如曾经调用过什么方法,曾经操作过哪些数据,等等。打印日志被认为是程序中最简单的工作之一,调试问题时常有人会说“当初这里记得打点日志就好了”,可见这就是一项举手之劳的任务。输出日志的确很容易,但收集和分析日志却可能会很复杂,面对成千上万的集群节点,面对迅速滚动的事件信息,面对数以 TB 计算的文本,传输与归集都并不简单。对大多数程序员来说,分析日志也许就是最常遇见也最有实践可行性的“大数据系统”了。
-
追踪(Tracing):单体系统时代追踪的范畴基本只局限于栈追踪(Stack Tracing),调试程序时,在 IDE 打个断点,看到的 Call Stack 视图上的内容便是追踪;编写代码时,处理异常调用了 Exception::printStackTrace()方法,它输出的堆栈信息也是追踪。微服务时代,追踪就不只局限于调用栈了,一个外部请求需要内部若干服务的联动响应,这时候完整的调用轨迹将跨越多个服务,同时包括服务间的网络传输信息与各个服务内部的调用堆栈信息,因此,分布式系统中的追踪在国内常被称为“全链路追踪”(后文就直接称“链路追踪”了),许多资料中也称它为“分布式追踪”(Distributed Tracing)。追踪的主要目的是排查故障,如分析调用链的哪一部分、哪个方法出现错误或阻塞,输入输出是否符合预期,等等。
-
度量(Metrics):度量是指对系统中某一类信息的统计聚合。譬如,证券市场的每一只股票都会定期公布财务报表,通过财报上的营收、净利、毛利、资产、负债等等一系列数据来体现过去一个财务周期中公司的经营状况,这便是一种信息聚合。Java 天生自带有一种基本的度量,就是由虚拟机直接提供的 JMX(Java Management eXtensions)度量,诸如内存大小、各分代的用量、峰值的线程数、垃圾收集的吞吐量、频率,等等都可以从 JMX 中获得。度量的主要目的是监控(Monitoring)和预警(Alert),如某些度量指标达到风险阈值时触发事件,以便自动处理或者提醒管理员介入。
什么是数据库的可观测性
什么是数据库的可观测性?为什么说,可观测性决定了数据库的成熟性。
Database observability tracks the database performance and resources to create and maintain a high performing and available application infrastructure.
数据库可观察性跟踪数据库性能和资源,以创建和维护高性能和可用的应用程序基础架构。
为了进行监控,数据库系统从数据库管理器、其数据库和任何连接的应用程序中收集信息。
有了这些数据和指标,团队可以获得他们需要的所有信息,以识别和解决影响应用程序性能的任何数据库问题,然后能够设置高性能数据库。
