




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
文件存储
文件存储的用户是自然人。计算机中所有的数据都是0和1,我们无法分辨和管理一连串的01组合,因此用“文件”概念对这些数据进行组织,所有用途相同的数据按照不同应用程序要求的结构方式组成不同的文件,通常用不同的文件后缀来指代不同的类型,再给文件命名方便理解记忆的名字。
当文件很多的时候,按照某种划分方式给这些文件分组,每一组文件放在同一个目录里面,同样也需要给目录命名容易理解和记忆的名字。而且目录下面除了文件还可以包含下一级目录,即子目录,所有的文件、目录形成一个树状结构。
块存储
文件系统是直接访问存储数据的硬件介质的,硬件介质不关心数据的组织方式和结构。
块存储是将数据按固定大小分块,每一块赋予一个用于寻址的编号。以机械硬盘为例,一块就是一个扇区,老式硬盘是512字节大小,新硬盘是4K字节大小。老式硬盘用柱面-磁头-扇区号组成的编号进行寻址,现代硬盘用一个逻辑块编号寻址,所以,硬盘也叫块设备至于哪些块组成一个文件,哪些块记录的是目录/子目录信息,这就是文件系统的事情了。
对象存储
对象存储其实介于块存储和文件存储之间。
文件存储的树状结构以及路径访问方式虽然方便理解、记忆和访问,但计算机需要把路径进行分解,然后逐级向下查找,最后才能查找到需要的文件,对于应用程序来说既没必要,也很浪费性能。而块存储是排它的,服务器上的某个逻辑块被一台客户端挂载后,其它客户端就无法访问上面的数据了。
为了解决文件存储和块存储中的麻烦,使用一个统一的底层存储系统来管理这些文件和底层介质的组织结构,然后给每个文件一个唯一标识,其它系统需要访问某个文件,直接提供文件的标识就可以了。
存储系统可以用更高效的数据组织方式来管理这些标识以及其对应的存储介质上的块。当然,对于不同的软件系统来说,一次访问需要获取的不一定是单个传统意义上的文件,根据不同的需要可能是某个文件的一部分,也可能是多个文件的组合,甚至是某个块设备,统称为对象,即为对象存储。
export JAVA_HOME=/home/cosbench/jdk1.8.0_102
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH


[controller]
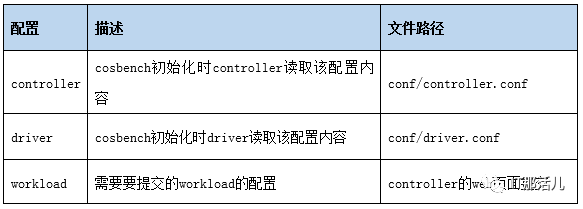
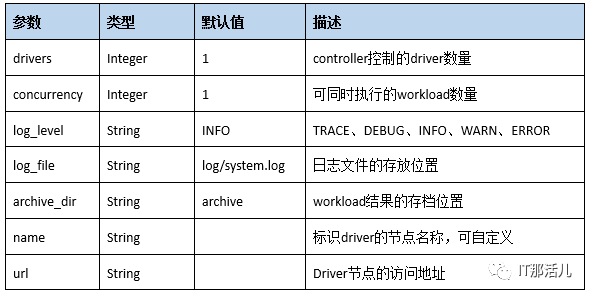
drivers = 1
concurrency=1
log_level = INFO
log_file = log/system.log
archive_dir = archive
[driver1]
name = driver1
url = http://XXX.0.0.1:18088/driver
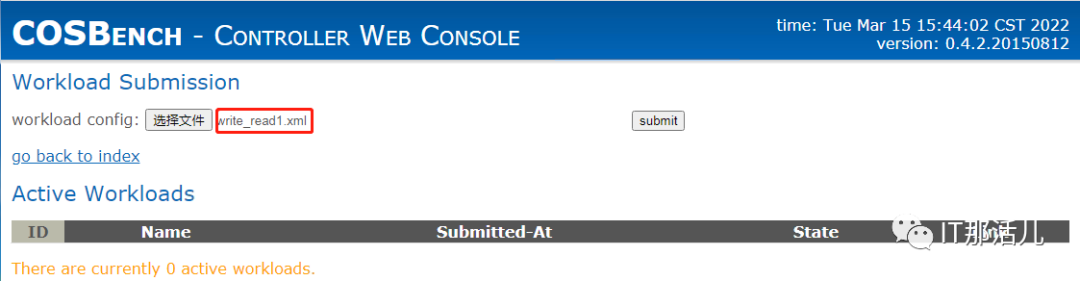
S3-config-sample.xml是Amazon S3兼容存储系统模板。
workload-config.xml提供了不同存储类型的配置模板,并添加了注释说明。
swift-config-sample.xml支持OpenStack Swift存储系统。


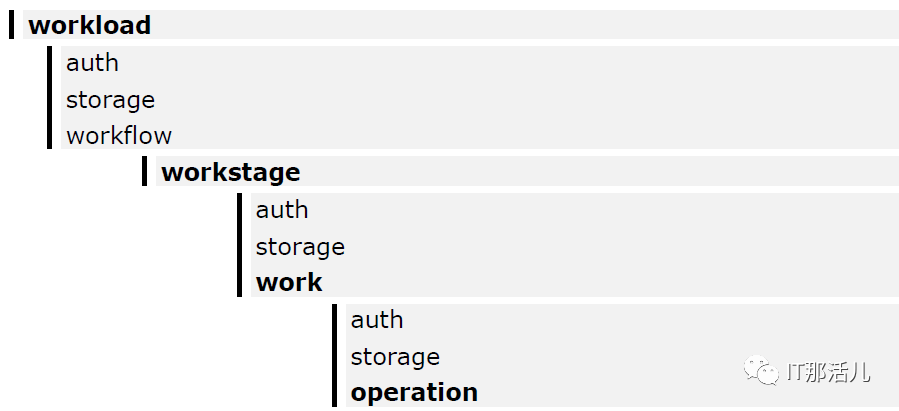
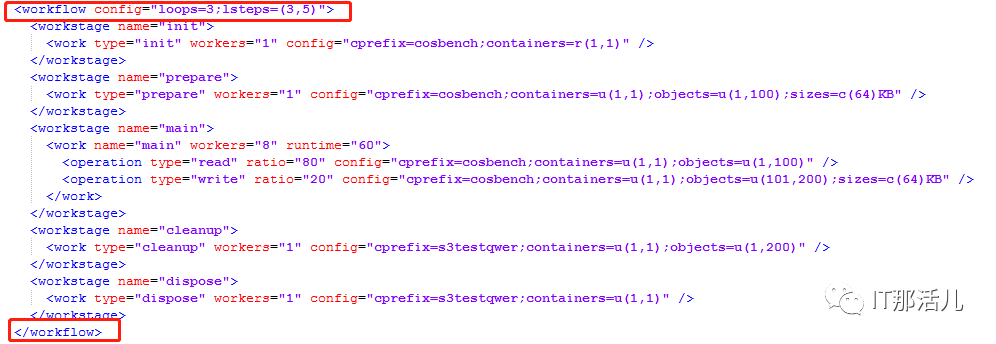
Workload ——> workstage ——> work ——> operation。
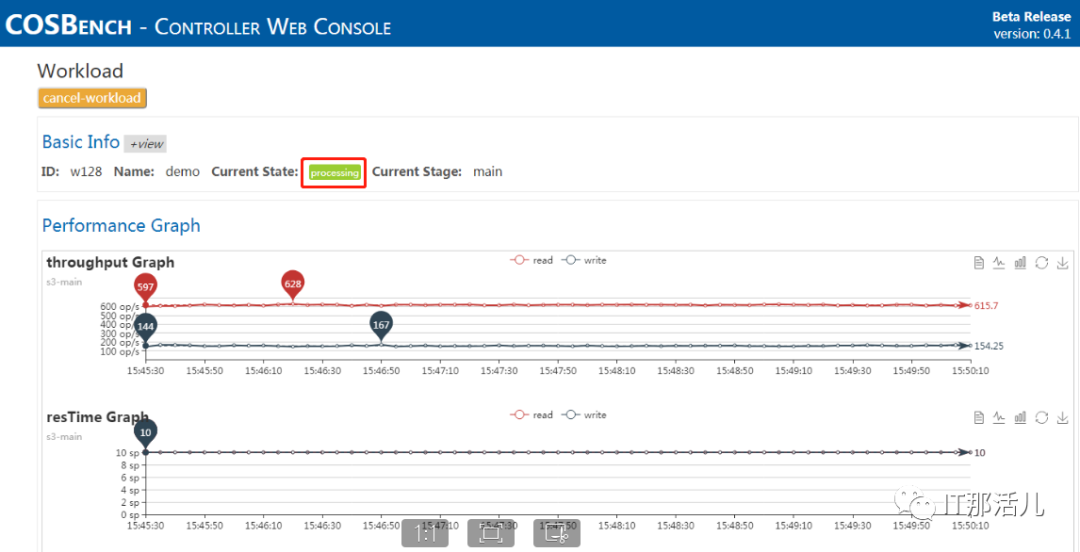
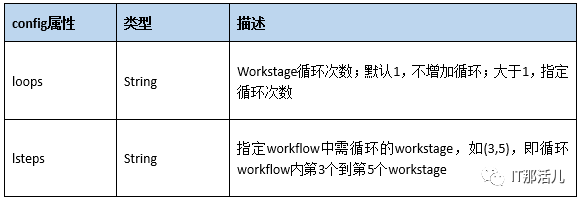
workload可以定义一个或多个workstage。
多个workstage按顺序执行,同一个workstage中的work是并发执行的,每个work中的workers属性即为负载并发数。
认证定义(auth)和存储定义(storage)可以在多个级别定义,而较低级别的定义会覆盖较高级别的定义。例如,operation用work中的auth和storage的定义,而不是workload级别的定义。


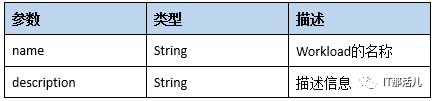
<workload name="obs-sample" description="10-100-64kb-test">
<storage type="none|mock|swift|ampli|s3|obs|…" config="<key>=<value>;<key>=<value>"/>

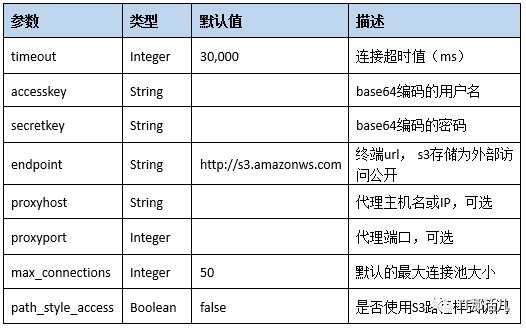
<storage type="s3" config="accesskey=<accesskey>;secretkey=<scretkey>;
endpoint=<endpoint>;proxyhost=<proxyhost>;proxyport=<proxyport>"/>
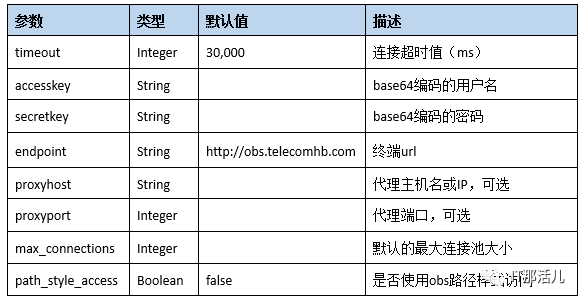
<storage type="obs" config="accesskey=C1820CD98DB79C95E979;secretkey=KI0pKjBYN1d
mWdeV11Y6ctb9sc0AAAF9jbecldNO;endpoint=http://obs.telecomhb.com" />
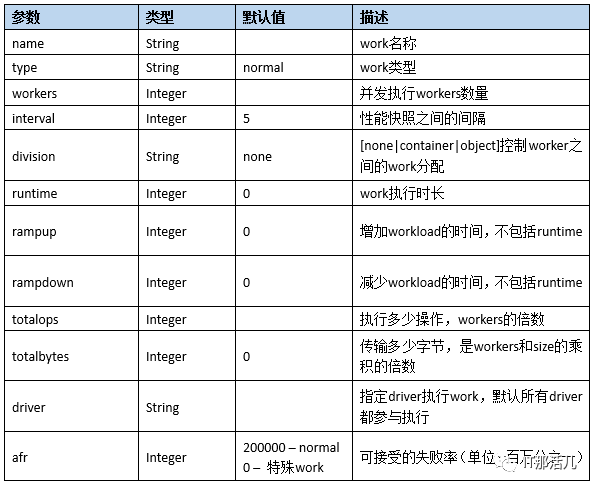
Worker:关键属性,控制负载。
Runtime:控制work的运行时长,work中只能设置一个。

normal work的参数说明:

init work参数说明:
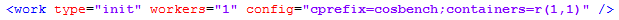
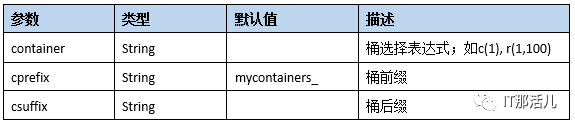
prepare work参数说明:
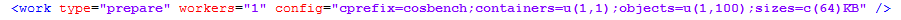
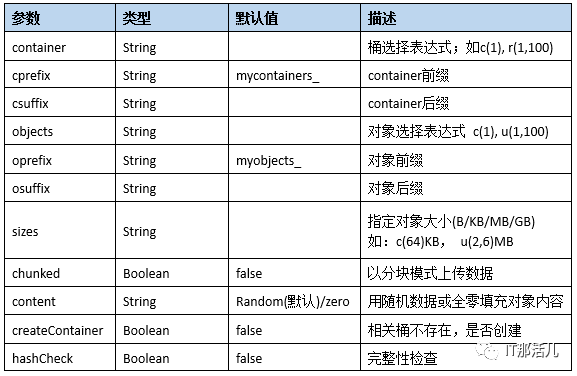
cleanup work参数说明:
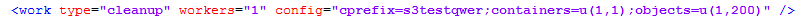
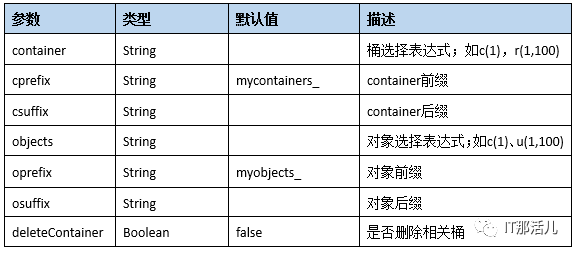
dispose work参数说明:
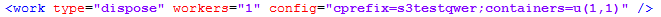
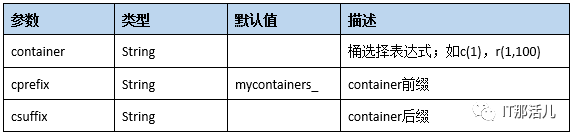
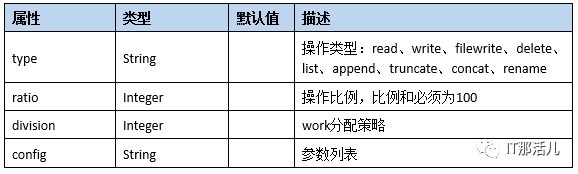
operation格式及属性:
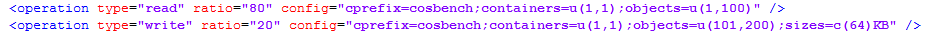
Read操作 -- 100%读,10workers,60秒。
<work name="100r10c60s" workers="10" runtime="60">
<operation type="read" ratio="100" config="..."/>
Write操作 -- 100%写,10workers,60秒。
<work name="100w10c60s" workers="10" runtime="60">
<operation type="write" ratio="100" config="..."/>
Read/write混合操作 -- 80%读,20%写,100workers,300秒。
<work name="80r20w100c300s" workers="100" runtime="300">
<operation type="read" ratio="80" config="..."/>
<operation type="write" ratio="20" config="..."/>
</work>
.meta -- 初始运行id;
run-history -- workload运行情况,包括时间和主要阶段;
workload -- 历史workload运行的总体性能数据;
Sub-directories -- 以w <runid>-为前缀,存储每个workload的运行数据。




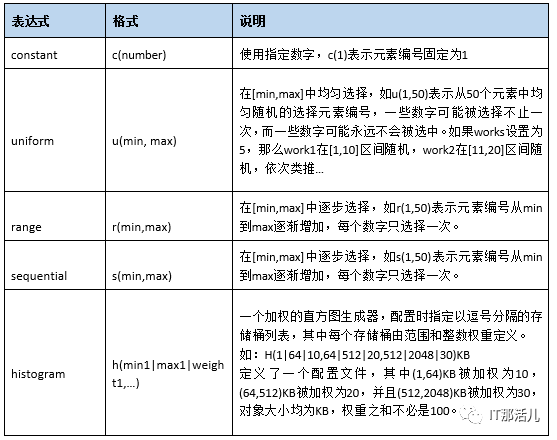
<operation type=”read” ratio=”80” config=”containers=u(1,2);objects=u(1,50)”/>
<operation type=”write” ratio=”20” config=”containers=u(3,4);objects=u(51,100);sizes=c(64)KB”/>

本文作者:方 威
本文来源:IT那活儿(上海新炬王翦团队)

