




查询优化中的一个小问题
大部分数据库会缓存执行计划以备重复使用; 然而当参数发生变化时, 缓存的执行计划未必再适用.
一个简单的索引选择例子:
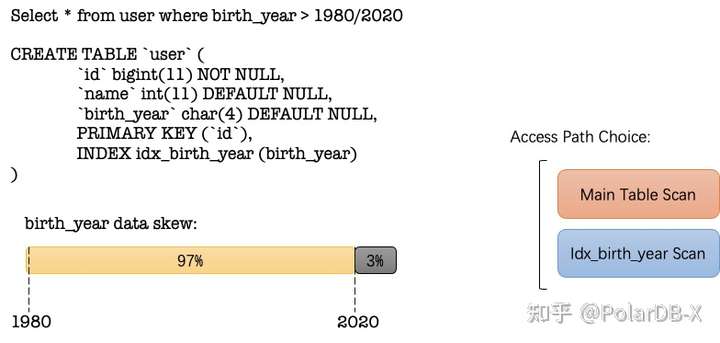
user 表中拥有 birth_year 索引,但当 birth_year 条件发生变化时,需要选择不同的 access path 才能保持较优的性能: 1980->main table scan; 2020-> idx_birth_year scan
在理想的情况下是, 数据库需要针对不同的参数请求,提供不同的扫描路径.在简单的场景下,可以每次都优化一下,但在复杂场景下,重入优化器的开销也会变重.例如涉及到多表 join 的 reorder, agg/join/sort 算法的选择等等.
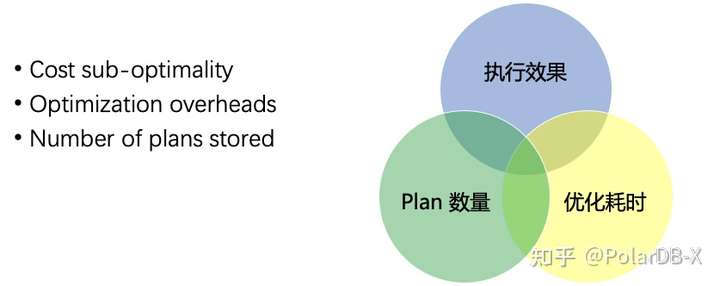
简单讲,就是不只局限于单次请求,而是放眼整个 workload,数据库通过缓存一定数量的执行计划,以及最低限度的优化耗时,达成更好的整体执行效率.
通常的做法
- OPTIMIZE-ALWAYS: 每次请求都会优化, 这样不会缓存任何执行计划,但整体优化耗时会随请求量线性上升,执行效果最好.
- OPTIMIZE-ONCE:缓存第一次生成的执行计划并不断复用, 只会缓存一个执行计划,后续请求不再有优化耗时,但执行效果会随参数变动而打折扣.
- PQO(Parametric Query Optimize) : 以上两种做法的折中, 缓存一定数量的执行计划,根据每次请求的参数选择更优的执行计划.
参数空间优化
本文主要简单介绍一下 PQO, 最终的执行效果主要看执行计划的边界模型是否清晰以及执行计划的选择算法, 之中还需要优化器的 cost 估算配合.
参数空间优化的思路也非常简单,既然重新构建执行计划的开销非常巨大,那么缓存一些执行计划,找到一个根据参数快速选择 cost 最低的执行计划的方法即可.
基于不同的参数,统计信息模块可以估算出涉及的数据量,从而评估出执行计划的 Cost.这里的关键点是各个表扫描出的数据量,所以也许并不需要计算每个执行计划整体的 Cost, 而是基于每个表扫出的数据量构建一个维度, 为每个执行计划划定一个区域,这样选择执行计划只需要计算各维度的数据量,就能评估出接近最佳的执行计划.
因次, 参数空间优化的第一步就是构建一个执行计划集群的边界模型.
执行计划边界优化模型
执行计划边界模型是依据优化器的优化逻辑画出的, 受统计信息或表达式估算不准确等影响, 初始的图边界可能会互相交错且杂乱. 这时候需要一些消除算法用于减少执行计划的数量,产生更清晰的边界.如下图(b)
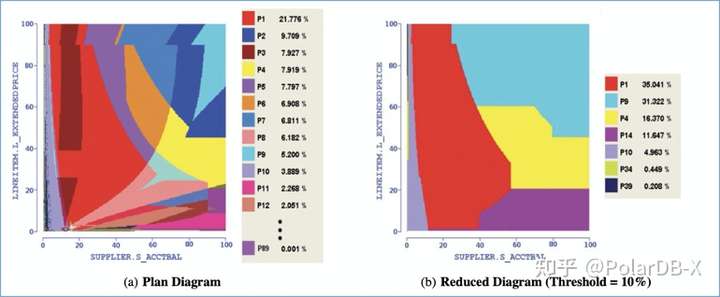
实际上, 优化逻辑越清晰的优化器,越容易生成边界清晰的边界模型.各个执行计划区域交错越少越好. 边界模型的产生有两种方式,预编译或运行时计算:
- 预编译:提前划定好执行计划边界, 优点是省去了运行时构建执行计划边界模型的开销,缺点是需要提前加载好 workload,并且容易构造出用户完全不会涉及的区域.
- 运行时:根据运行时用户的具体参数及时构建出执行计划模型,优点在于只会针对具体访问的请求构建一部分区别模型,缺点在于一般需要的执行反馈,会有一定的试错成本.
这里介绍一下一项基于运行时不断动态构建执行计划区域的技术: SCR。
SCR
SCR 是 SQL Server 用于解决 PQO 问题的方案之一.它主要基于 selectivity 来估算执行计划的 Cost, 以及提供了一种在线的方式构建执行计划边界模型.
执行计划的选择
当一个新的请求参数出现时,如何针对性的选择出最优的执行计划呢.这里有两种做法,通过参数值划定;通过 selectivity 划定. 基于具体参数值划定, 在表达式比较复杂,数据分布有倾斜的情况下,会有很大的不稳定性.基于各个表 selectivity 多维表,从优化器的角度看更为合理.
selectivity:scan 出数据量的比值, 0~1
在论文 Leveraging Re-costing for Online Optimization of Parameterized Queries with Guarantees 中, 运行时构建了优化模型,并提出了一个 cost 领域估算模型.这个估算模型主要为了解决运行时状态, 单一执行计划的辐射范围是多少,即在什么样的范围内,可以复用该执行计划.

考虑上图两个维度的情况,q0 为运行时的具体请求点, C 则为运行后的 Cost,为一个常量. 那么基于两个不同的 selectivity 维度分别设定两个函数 f1, f2 用于估算 Cost 在单一维度上的增长曲线.那么基于每个维度上的这个函数,就可以得到整体的上下限值.
假设 f 函数默认为线性增长函数,即每个 selectivity 维度上 Cost 的增长都是线性的, 不同维度的斜率不同.

λ 是一个配置, 对于查询 c , 如果Cost(Pe, c) / Cost(Pe, e) < λ, 则认为 c 可以复用这个执行计划.
最后, 基于某一次执行 qe 及其执行计划 Pe, 在多次查询的情况下可以逐渐构建出两个区域.区域的计算方法见具体论文. selectivity based λ-optimal 区域为通过计算获得的可重入执行计划的区域. 而 recost 区域则为在真实的查询中,不断 feedback 真实 cost 用于扩大 selectivity 的区域. 最终达到的效果就是在真实的 workload 中, 基于配置 λ 不断扩大该执行计划的可复用区域.
执行计划管理模型
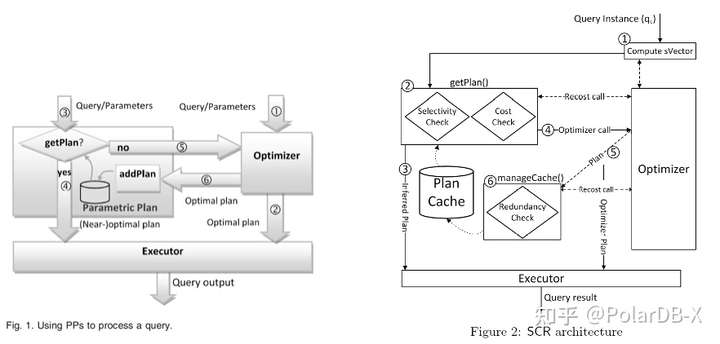
上图左侧为 SQL Server 2005, 右侧 SQL Server 2016, 2016 最大的变化则是引入了以上章节中提到的在线的执行计划区域构建模型. 具体作法上的区别除了通过 selectivity 找出最近区域的执行计划外, 还会通过执行反馈 cost 不断放大执行计划的复用区域.
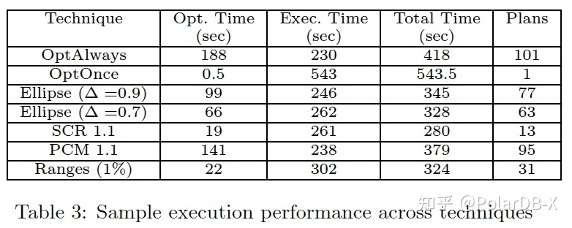
上表为各项在线技术的横向测评结果,可以看出在论文描述的场景 SCR 在各项指标中最为均衡.整体执行时间最佳.
总结
如果只是针对简单的在线交易场景,可能每次重新构建执行计划的开销也不大.但在 TP/AP 混合负载场景,我们需要考虑 PQO 技术用于管理执行计划选择,从而获得整体更优的执行效率.
但这个领域是针对整个 workload,目前没有非常明确的测试标准用于评估整体的执行效果.各种边界模型, 选择算法层出不穷, 落地的成本也很高. 如果某个数据库在考虑引入此项技术时,一定要想清楚自己需要解决的是什么场景的问题,如果只是非常极端的个例,也许让业务变更下 SQL 是更加经济,快捷的选择.
参考
- 执行计划管理
- Progressive Parametric Query Optimization
- Adaptive Query Processing
- AniPQO: Almost Non-Intrusive Parametric Query Optimization for Nonlinear Cost Functions
文章来源:阿里云数据库
