





黄玮(Fuyuncat)
资深Oracle DBA,个人网站www.HelloDBA.com,致力于数据库底层技术的研究,其作品获得广大同行的高度评价.
ORA-01555(快照过旧)问题让很多人感到十分头痛。最近我们的生产系统上也报出了ORA-01555错误。就结合这次案例将ORA-1555问题作个案例分析,并浅析产生原因和各种解决办法。
如果要了解1555错误产生的原因,就需要知道ORACLE的两个特性:一致性读(Consistent Get)和延迟块清除(Delayed Block Cleanout)。此外,还要知道关于回滚段的一些配置参数。
先看下Oracle中关于UNDO有哪些配置参数:
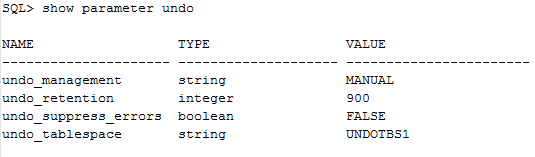
undo_management
回滚段的管理方式。值可以为MANUAL/AUTO。9i中默认是MANUAL,10g中默认是AUTO。
从9i后,回滚段就以表空间的形式管理,并且支持系统自动管理回滚段。一个回滚表空间上可以创建多个回滚段,一个数据库可以创建多个回滚表空间。但是,一个实例(Instance)只能使用一个回滚表空间。
如果undo_management设置为MANUAL,就是手动创建回滚段:
SQL> create rollback segment undo1 tablespace UNDOTBS1;
如果设置为AUTO,Oracle就自动管理回滚段的创建,而手工创建就会失败。
undo_retention
这个参数设置回滚段中的被提交或回滚的数据强制保留时间,单位是秒。请注意,这个参数和1555错误有非常大的关系。但是,需要提醒的是,并不是回滚段中的数据超过这个时间以后就会被清除掉,而是等到后面事务产生的回滚数据覆盖掉“超期”数据。所以这就是为什么我们往往看到系统的回滚表空间占有率始终是100%的原因了。
undo_suppress_errors
是否报与回滚段有关的错误。如果为FALSE,就不会产生与回滚段有关的错误。但是,请注意,并不是不会发生回滚段错误,而只是屏蔽错误信息,错误发生了就会存在滴。在10g
undo_tablespace
为每个实例制定的唯一当前使用的回滚段表空间。
一致性读(Consistent Get)可以说是产生1555错误的主要原因。但它的确是Oracle一个非常优秀的特性。既然这个特性会产生这么烦人的错误,我为什么还说它是ORACLE十分优秀的特性呢?下面就先了解一下这个特性:
并发事务和脏读
需要先了解一下这一特性的产生的背景原因。看下以下这个例子。在一个银行系统中(一般涉及到钱的问题对并发事务要求是最严格的^_^),会计正在统计当月某地区的个人存款总额,她的这个操作,在后台肯定要产生一条SQL语句,对这一地区的所有用户的存款额作SUM(),我们假设这一操作产生的语句为A,时间点是T1。由于存款用户非常多,再加上会有一些对其他表的JOIN条件,语句A的执行时间可能比较长。这时,在A的执行过程中,A已经统计了账户X的钱,但还没有统计到账户Y的钱的时候,正好有一个客户通过ATM机从账户X中转250元钱到帐户Y,他的操作也产生了一条语句B,对存款表进行更新。开始时间点是T2,结束时间是T3。因为只更新两条记录,这个过程非常短。A结束时的时间点是T4。让我们看下过程图,看看会产生什么结果:
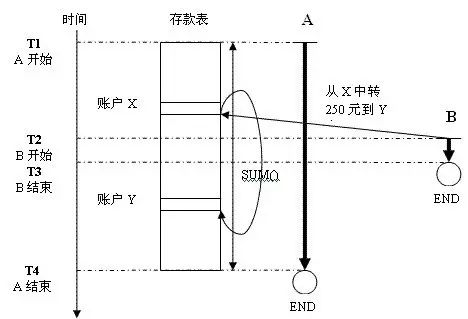
从图中,我们可以看到,T2时刻A已经统计过帐户X中的钱,但在这时B从X中转了250元到帐户Y中,在B结束的时刻T3,A还没有统计到Y,但Y已经多出了250元了,所以到T4,统计结束时,A实际上多统计出250元。这就是并发事务中的“脏读(dirty read)”问题。
在标准SQL中,为了防止并发事务中产生脏读,就需要通过加锁来控制。这样就会带来死锁、阻塞的问题,即时是粒度最小的行级锁,也无法避免这些问题。再看下上面这个例子。为了防止脏读,A在开始时就需要对表加锁,防止其他事务更新表。这样,B就会被阻塞,假如A事务要执行1个小时,B可能最长就要被阻塞1个小时。再看下图,
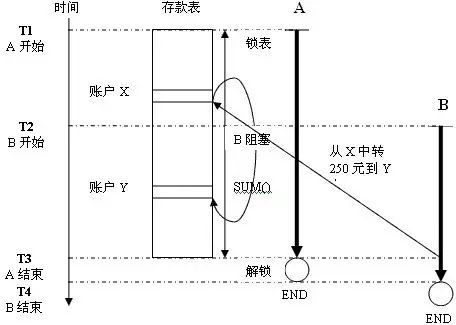
从图中,可以看到,B开始时,存款表被加锁了,所以B被A阻塞,只有等A释放锁以后,B才能更新表。所以B被阻塞了很长时间。在大量并发事务系统中,可能会使整个系统慢得不可想象。
一致性读
为了解决这一矛盾。Oracle充分利用的回归段,通过会滚段进行一致性读取,即避免了脏读,又大大减少了系统的阻塞、死锁问题。
下面就看下Oracle是如何实现一致性读的:
当Oracle更新数据块(Data Block Oracle中最小的存储单位)时,会在两个地方记录下这一更新动作。一个是重做段(Redo Segment),是用于数据库恢复(Recover)用的。一个是回滚段(UNDO Segment),而回滚段是用于事务回滚(Rollback)的(我们只关心回滚段了)。并在数据块头部标示出来是否有修改数据。一个语句在读取数据快时,如果发现这个数据块是在它读取的过程中被修改的(即开始执行读操作时并没有被修改),就不直接从数据块上读取数据,而是从相应的回滚段条目中读取数据。这就保证了最终结果应该是读操作开始时的那一时刻的快照(snapshot),而不会受到读期间其他事务的影响。这就是Oracle的一致性读,也可以叫做多版本(Multi-Versioning)。
以上面的例子为例,A在读取到Y帐户时,发现这条记录已经被修改了,于是就从回滚段读取保留的回滚数据,最终就能正确得到T1时刻的正确存款总额了。看下图:
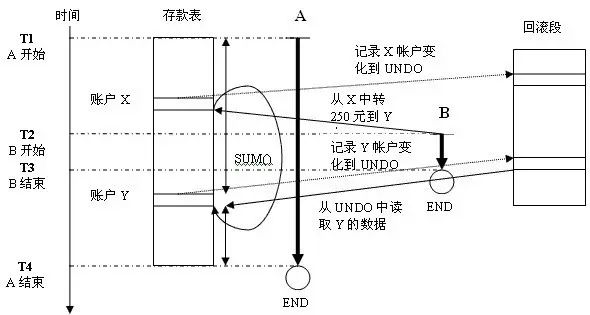
从图上看出,A即能得出正确的数据,又保证B不会被阻塞。
再介绍一下另外一个可能产生1555错误的概念——延迟块清除(Delayed Block Cleanout)。但个人认为,如果不从字面意思上翻译,应该把它叫做延迟锁清除更加让人容易理解一些。
我们知道,当Oracle更新数据块时,会在回滚段(UNDO Segment)记录下这一更新动作。并且产生一个Cleanout SCN,在回滚段中,会产生对应的Transaction ID以及相应的数据记录镜像。并在对应的数据记录上,产生锁标志。在事务提交(commit)前,会在数据块的头部记录下这个Cleanout SCN(Csc)号、Undo Block Address(Uba)和Transaction ID(Xid);并且在在对应Interested Transaction List(Itl)中设置锁标志,记录这个事务在这数据块中产生的锁的数目;同时在对应修改的数据记录上打上行级锁标志,并映射到对应的Itl去。当提交时,并不会一一清除掉所有锁标志,而是给对应的Itl打上相应标志,告诉后面访问该数据块的事务,相应的事务已经提交。这就叫做快速提交(Fast Commit)。而后面访问该数据块的的事务就先检查锁标志和对应的事务状态,如果发现前面的事务没有提交,并且要访问的数据记录被锁住了,就被阻塞;否则就清除相应的锁标志,并提交自己的锁标志,再重复以上动作。这就事延迟块清除。
而如果前面的事务在提交之前buffer cache中的脏数据已经被DBwn进程写回,那么Itl中的事务标志就不会被更新,并且数据块的Itl列表也不会记录下事务的Commit SCN。后面的事务或查询语句访问该数据块时,为了检测是否需要进行一致性读(如果数据块的Itl中记录的提交事务的Commit SCN大于当前访问该数据块的SCN,则需要进行一致性读),就需要通过Undo Block Address和Transaction ID到回滚段的事务信息表中去检查前面事务的状态和它的Commit SCN,确定是否做一致性读,最后将前面事务在该数据块上的标志做一次Cleanout。
下面就举一个例子:
创建测试表:
SQL> create table t_multiver (a number, b number);
Table created.
插入测试数据,这时,实际上已经产生了一个对数据块修改的事务:
SQL> insert into t_multiver values (1,1);
1 row created.
SQL> insert into t_multiver values (2,2);
1 row created.
SQL> insert into t_multiver values (3,3);
1 row created.
SQL>
SQL> commit;
Commit complete
修改记录,并且在commit之前将脏数据写回:
SQL> conn demo/demo
Connected.
SQL> update t_multiver set b=115 where a=1;
1 row updated.
SQL> alter system flush buffer_cache;
System altered.
SQL> commit;
Commit complete.
Dump出数据块:
SQL> alter system dump datafile 5 block 50959;
System altered.
看看Dump出来的内容:
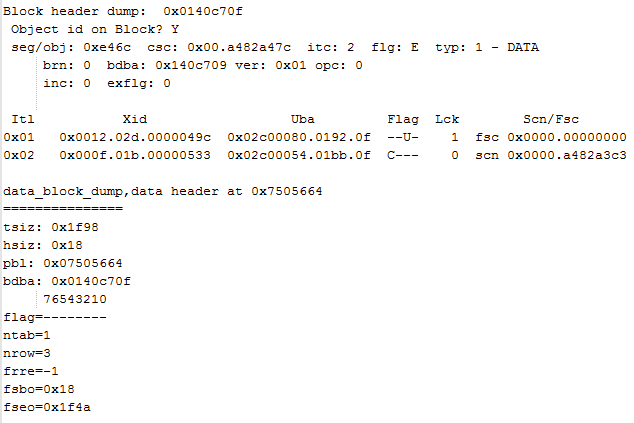
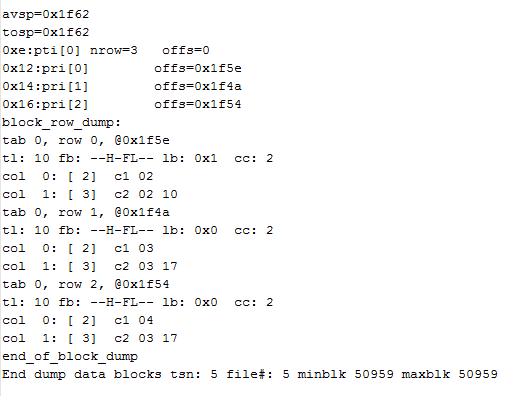
其余的内容在我们讨论的这个问题中不需要太关心,主要注意Interested Transaction Slot (ITS) 部分。
CSC:即Cleanout SCN,它是在我们的insert操作事务中产生的。
Flag:事务标志位。由于我们在提交之前将buffer cache手动flush了,所以标志位为空。请注意到,我们这在commit之前DBwn已经写回了脏数据,标志为空。各个标志的含义分别是:
C--- = transaction has been committed and locks cleaned out
-B-- = this undo record contains the undo for this ITL entry
--U- = transaction committed (maybe long ago); SCN is an upper bound
---T = transaction was still active at block cleanout SCN
可以看到,目前事务标志是----,这是为什么呢?请注意,上面过程在commit之前进行了buffer cache flush,也就是说,oracle进程在改写数据块时,该事务还未提交,也未回滚,所以标志为空。而假如将buffer cache flush放在commit之后,该标致就为--U-,即事务已经提交,但是相应的锁并没有清除(有兴趣可以自己做试验)。所以,看到后面的Lck位(行级锁数目)为1(因为我们修改了1条记录)。
再看每条记录中的行级锁对应Itl条目lb:都是0x1。即Itl中的第一条。
这时,我们重新访问该数据块:
SQL> alter system flush buffer_cache;
System altered.
SQL> conn demo/demo
Connected.
SQL> select * from t_multiver;
A B
---------- ----------
1 115
2 222
3 222
SQL> alter system dump datafile 5 block 50959;
System altered.
再将数据块内容dump出来:
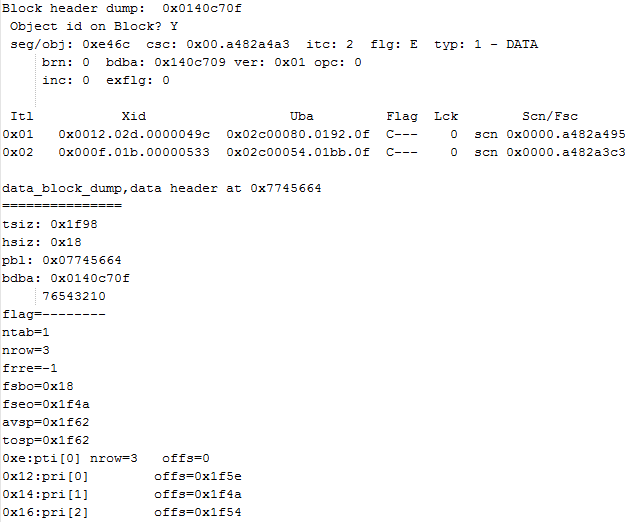
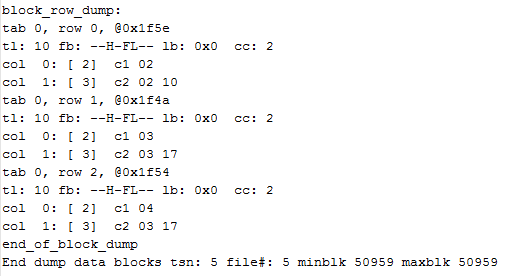
这时,可以看到,前一事务的Itl条目中,Flag标志为已经被修改为C,即提交完毕,Commit SCN也被获得。锁也已经被清除,其锁Lck的数量也清0。相应的,各条记录的行锁对应Itl位也被清0。
图解一下这个过程:
数据块初始状态:
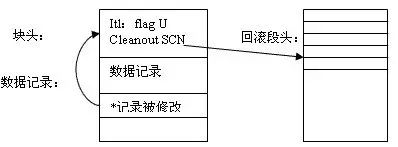
第一个修改该数据块的事务提交后:
第二个访问该数据块的事务(清除了相应锁信息)

当然,如果事务进行的删除操作,或者事务回滚,又会有一些不同的情况。
后面的分享中将会继续解答ora-01555错误发生的场景和解决方案
如何加入"云和恩墨大讲堂"微信群
搜索 盖国强(Eygle)微信号:eyygle,或者扫描下面二维码,备注:云和恩墨大讲堂,即可入群。每周与千人共享免费技术分享,与讲师在线讨论。

分区剪裁特性剖析
利用DMU修改数据库字符集
UPDATE GLOBAL_NAME为空之后的恢复
关注本微信(OraNews)回复关键字获取
2016DTCC, 2016数据库大会PPT;
DBALife,"DBA的一天"精品海报大图;
12cArch,“Oracle 12c体系结构”精品海报;
DBA01,《Oracle DBA手记》第一本下载;
YunHe,“云和恩墨大讲堂”案例文档下载;
