




今天在做例行巡检时在awr中看到一条异常sql,如下:
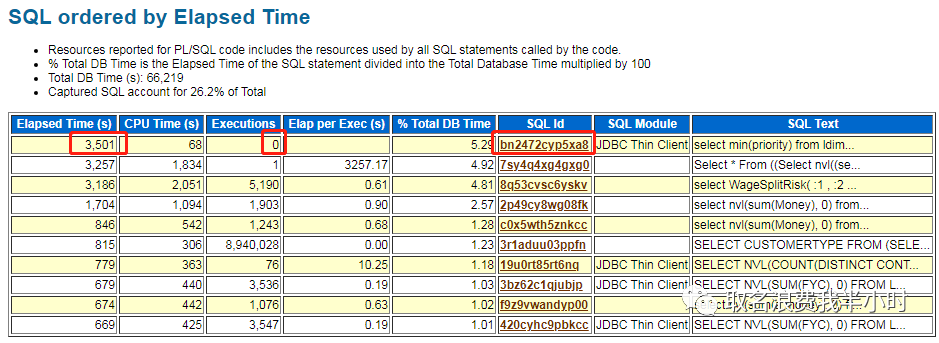
这条sql跑了3501秒还没有跑完,并且sql语句看起来并不是特别复杂,于是就来分析一下,看看有没有优化空间。
sql文本如下:
select min(priority) from xxxperson t where '1606270446000' = '1606270446000' and exists (select 1 from xxxpnt m where m.idtype = t.idtype and m.idno = t.idno and m.contno = '880037131628' and t.validstate = '1') or exists (select 1 from xxxsured n where n.idtype = t.idtype and n.idno = t.idno and n.contno = '880037131628' and t.validstate = '1'); |
来看看执行计划:
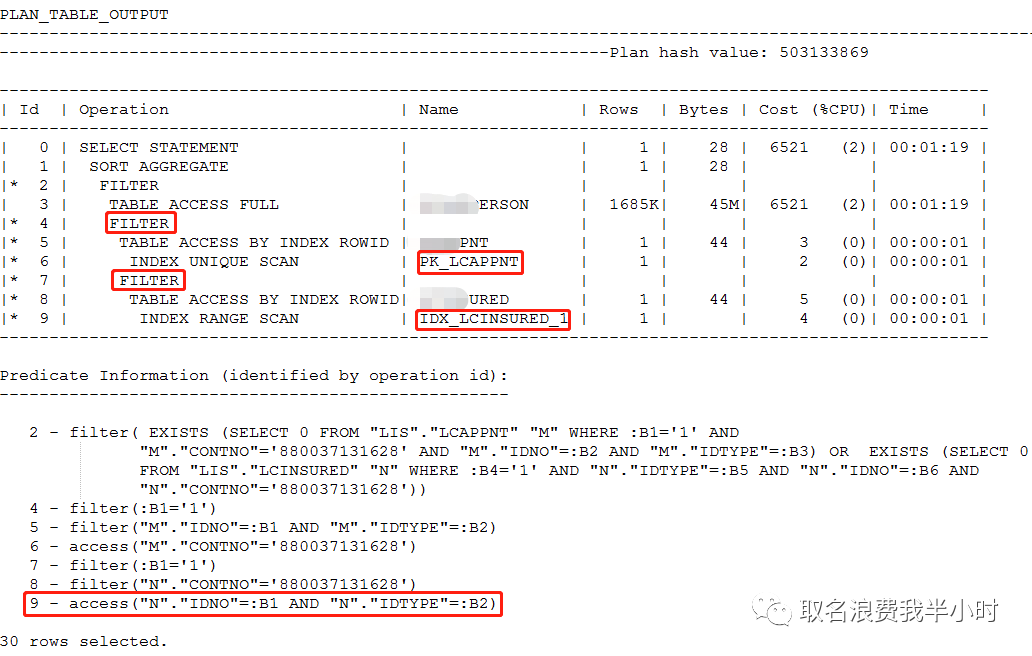
只能说sql写的不咋地,这种exists的写法,很明显会导致走filter类型的执行计划,即t表有多少条记录,m表和n表就会被执行多少次。为了更好的对比优化前后的性能差异,接下来我们先来看看这条sql真实的执行情况(等待的过程是漫长的):
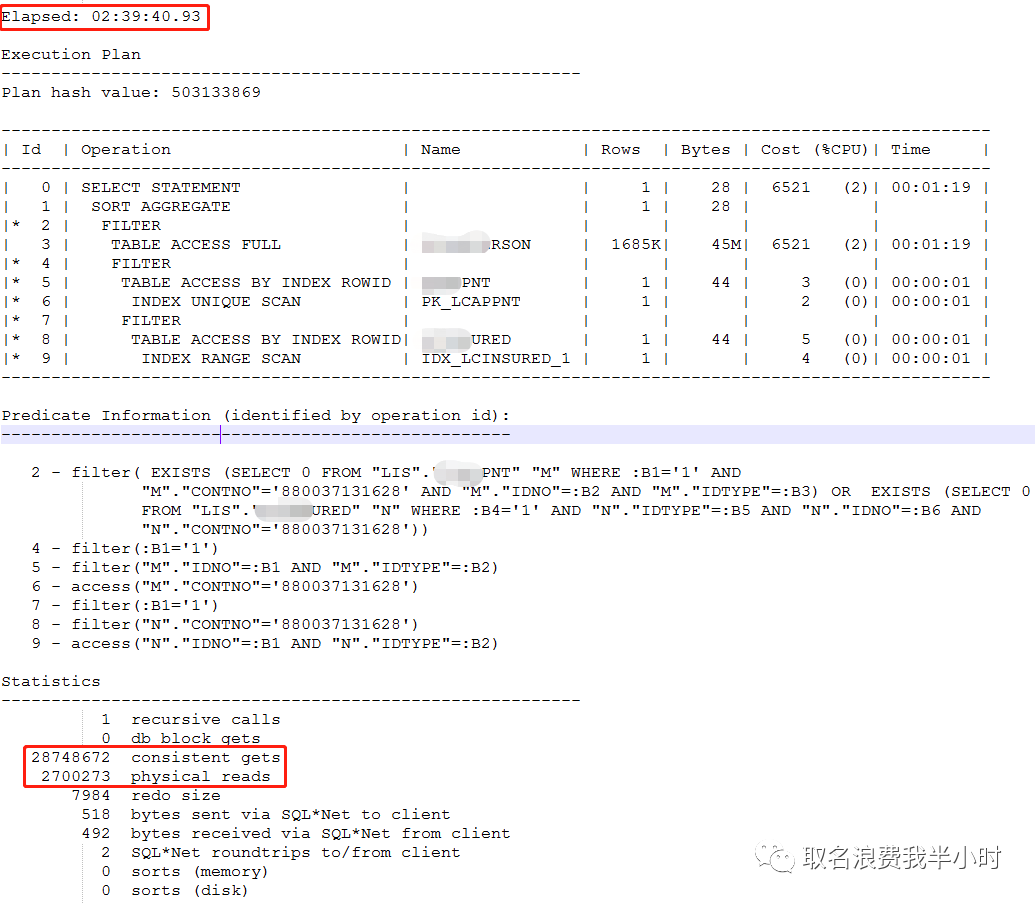
没错很夸张,该sql执行总耗时2小时39分钟40秒,逻辑读2874多万,物理读270多万。
filter真的就这么一无是处吗?当然不是,不过这里就不纠结这个了。结合sql文本和执行计划,凭直觉contno列的选择度应该不会差,可以发现执行计划第6步走了contno列的索引,但第9步没有走上contno列的索引,而是走了idno列的索引,再来看看n表各列的选择度以及索引情况:
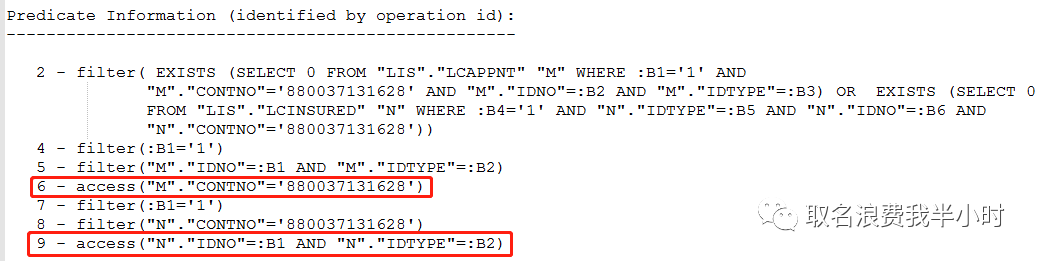
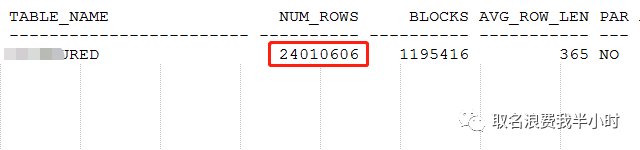
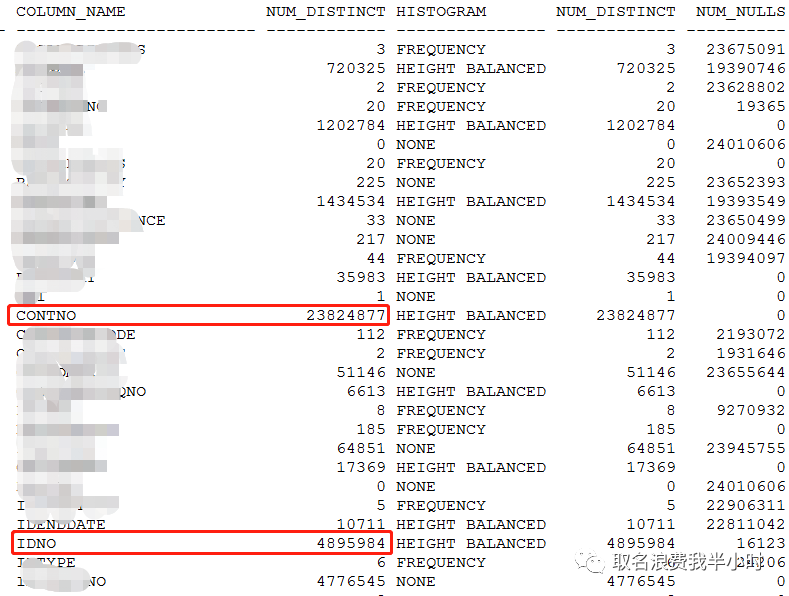

很明显的可以看出,执行计划第9步应该选择IDX_CONTNO这个索引,效率会更高,那么接下来就来验证一下(在第二个exists部分加上强制索引的hint):
select *+ gather_plan_statistics*/min(priority) from xxxperson t where '1606270446000' = '1606270446000' and exists (select 1 from xxxpnt m where m.idtype = t.idtype and m.idno = t.idno and m.contno = '880037131628' and t.validstate = '1') or exists (select *+ index (n IDX_CONTNO)+*/ 1 from xxxured n where n.idtype = t.idtype and n.idno = t.idno and n.contno = '880037131628' and t.validstate = '1'); select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); |
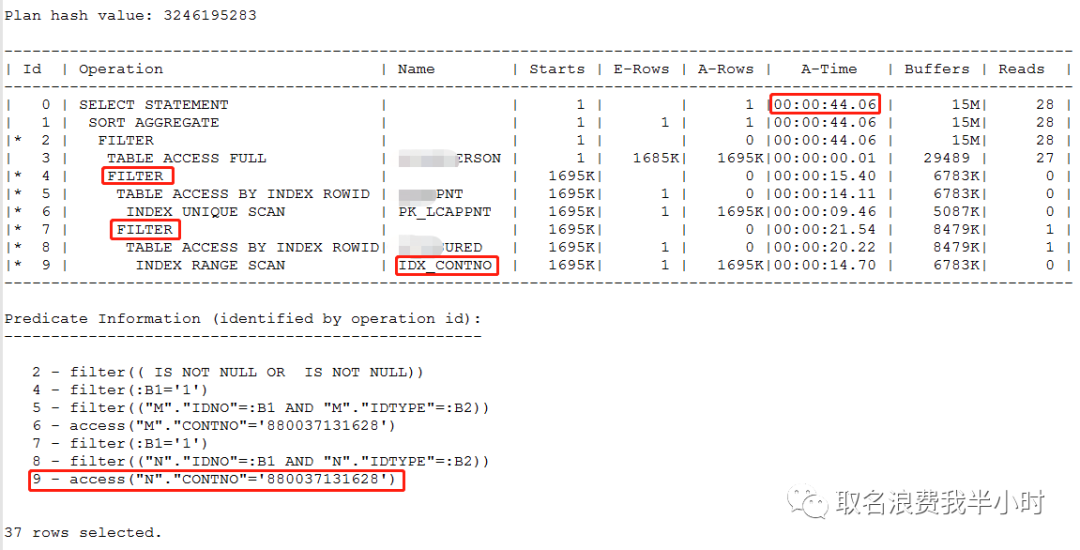
从真实的执行计划可以看出,还是走的filter类型的执行计划,执行计划第9步走上了IDX_CONTNO索引,并且44秒就执行完成。而且正如最前面的分析,m表和n表都被启动了169万次(t表的记录数)。
到目前为止这条sql执行时间从2小时39分40秒优化到44秒执行完成,这样就可以了吗?答案是否定的。虽然现在执行时间只需44秒,但我们来看看资源消耗:
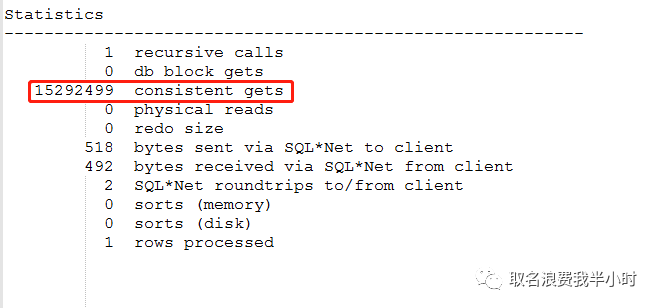
可以看到仍然需要1500多万的逻辑读,继续优化:
我们在回到开头讨论的exists,接下来我们将exists进行改写,改写后的sql如下:
select min(priority) from xxxperson t,xxxpnt m ,xxxured n where ('1606270446000' = '1606270446000') and m.idtype = t.idtype and m.idno = t.idno and m.contno = '880037131628' and t.validstate = '1' or (n.idtype = t.idtype and n.idno = t.idno and n.contno = '880037131628' and t.validstate = '1' ); |
最后再来看看改写之后的sql真实的执行计划:
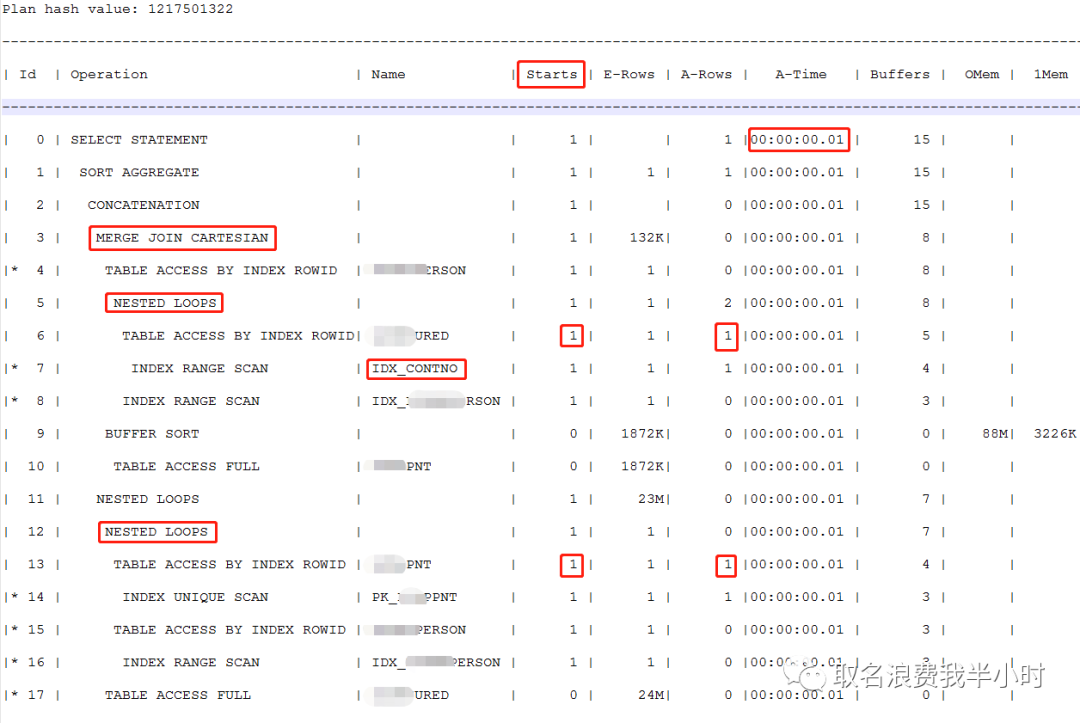
你没看错,只需要10毫秒,从真实的执行计划可以看出,改写之后,n表和m表只被启动了一次,且评估行数和真实行数是一致的为1行,因此作为驱动表走nested loop,再加上有选择度很高的索引,效率会非常高。
最后我们来看看改写之后的资源消耗情况:
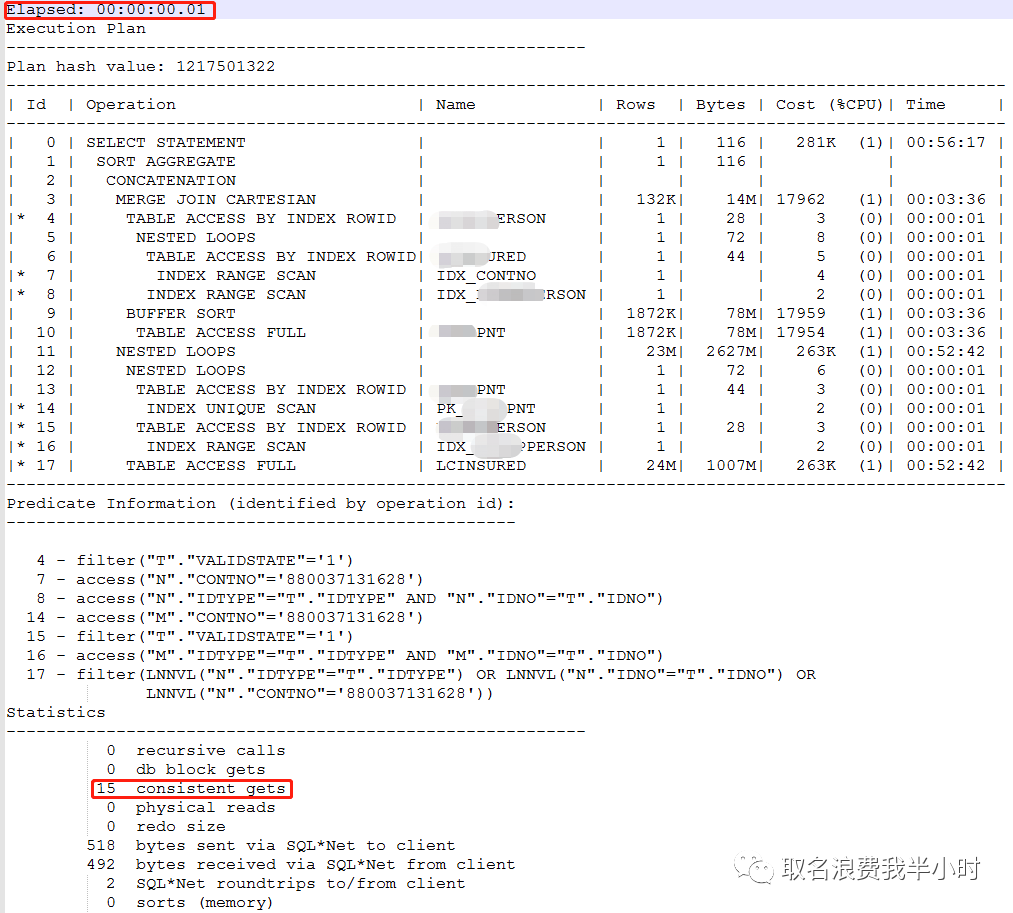
最终该sql的执行时间从最初的2小时39分钟40秒降低到现在的10毫秒,消耗的逻辑读从2874万降低到15,物理读从270万降低到0。虽然案例很简单,但是效果很明显 。
。
