




前言
在字体加密一文提到对非标准的字体的破解办法是手动构建字典或者OCR,前者对与字体不多的 ttf 或者 woff 文件使用这种方式是没有任何问题的,但是一但字体文件承载但字体过多或者是非规范字体文件过多,显然手动构建的方式是极其不方便的,后者不失为一个好办法。
破解字体加密
OCR
OCR 归根结底是是对形状对识别,将对应对形状转化成文字,字体文字对应形状来自哪里?在 中提到了是来自一组坐标组,用程序将这组坐标绘制成文字形状的图片,然后通过 OCR 识别,具体效果就看 OCR 的准确度了。
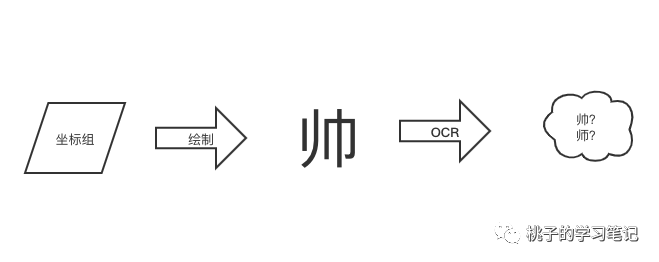
不用 OCR 还有没有其他办法呢?答案是有的。
图片相似度
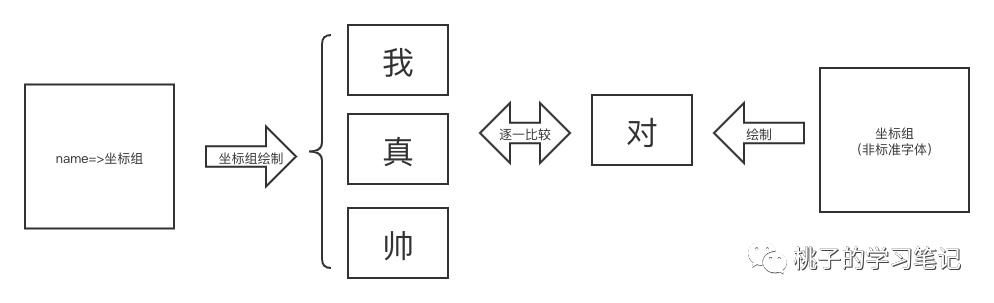
我们既然可以把坐标组绘制成图片,那么是不是可以把标准字体的所有文字坐标绘制成一幅幅图片,然后与非标准字体绘制的图片进行对比,相似度最高的一组,就说明它最有可能对应这个文字。
图片相似度的算法有很多:
余弦相似度
直方图
感知哈希算法
SSIM
有兴趣的可以点击参考链接的相关文章进一步阅读。接下来,我则会通过 SSIM 的比较,来对比字体图片的相似度。
样例
首先找一个标准字体的字和两个非标准字体的坐标,这里以 “店” 和 “1” 作为测试,找到对应的坐标,然后绘图
绘制字体图形
import numpy as np
import cv2
import matplotlib.pyplot as plt
# 标准字体
p1 = np.array(
[(1048, 1271),(1212, 1271),(1212, 1021),(1962, 1021),(1962, 877),
(1212, 877),(1212, 593),(1806, 593),(1806, -265),(1646, -265),
(1646, -135),(738, -135),(738, -265),(578, -265),(578, 593),(1048, 593),
(950, 1655),(1092, 1725),(1173, 1605),(1243, 1475),(2012, 1475),(2012, 1327),
(388, 1327),(388, 657),(368, 33),(118, -281),(72, -219),(4, -145),(220, 141),
(222, 693),(222, 1475),(1057, 1475),(1009, 1565),(1646, 449),(738, 449),(738, 5),(1646, 5)]
)
x_coords = []
y_coords = []
for x,y in p1:
x_coords.append(x)
y_coords.append(y)
# plt.scatter(x_coords, y_coords)
# plt.xlim(-1000, 2800)
# plt.ylim(-1000, 2800)
# plt.savefig('p1.png')
plt.figure()
plt.fill(x_coords,y_coords,color='black')
plt.savefig('p1.png')
plt.show()
# 大众点评字体"店"
p2 = np.array([(523, 607),(523, 274),(295, 274),(295, -99),(366, -99),
(366, -49),(788, -49),(788, -99),(859, -99),(859, 274),
(596, 274),(596, 420),(926, 420),(926, 488),(596, 488),
(596, 607),(366, 19),(366, 207),(788, 207),(788, 19),
(529, 822),(454, 810),(481, 768),(504, 719),(137, 719),
(137, 430),(134, 124),(45, -47),(99, -95),(204, 103),
(208, 430),(208, 649),(945, 649),(945, 719),(577, 719),(553, 777)])
x_coords = []
y_coords = []
for x,y in p2:
x_coords.append(x)
y_coords.append(y)
plt.figure()
plt.fill(x_coords,y_coords,color='black')
plt.savefig('p2.png')
plt.show()
# 大众点评字体"1"
p3 = np.array([(297,714),(262,674),(160,612),(111,598),
(111,516),(212,546),(279,614),(279,0),(361,0),
(361,714)])
x_coords = []
y_coords = []
for x,y in p3:
x_coords.append(x)
y_coords.append(y)
plt.figure()
plt.fill(x_coords,y_coords,color='black')
plt.savefig('p3.png')
plt.show()
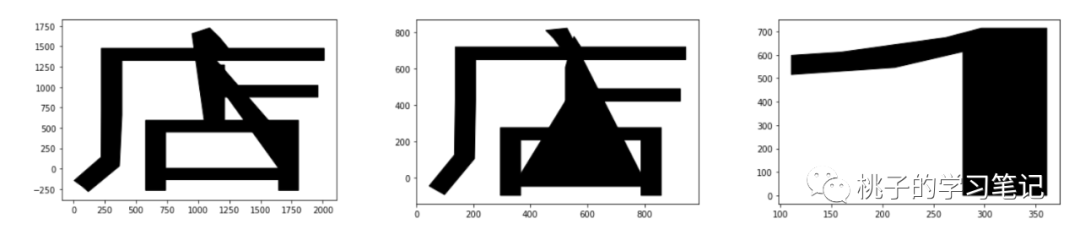
SSIM 比较图片相似度
from skimage.measure import compare_ssim
from skimage.transform import resize
import imageio
# get two images - resize both to 1024 x 1024
img_a = resize(imageio.imread('/content/p1.png'), (2**10, 2**10))
img_b = resize(imageio.imread('/content/p2.png'), (2**10, 2**10))
img_c = resize(imageio.imread('/content/p3.png'), (2**10, 2**10))
# score: {-1:1} measure of the structural similarity between the images
score, diff = compare_ssim(img_a, img_b, full=True,multichannel=True)
print("p1与p2的相似度:",score)
score, diff = compare_ssim(img_a, img_c, full=True,multichannel=True)
print("p1与p3的相似度:",score)
输出结果如下:
p1与p2的相似度: 0.8668768555285586
p1与p3的相似度: 0.7761509725926455
结尾
具体使用哪种算法需要结合实际来进行选择,不同的算法可能存在不同的优缺点,最迟我尝试的算法是用直方图,很可惜直方图过于简单,只能捕捉颜色信息的相似性,捕捉不到更多的信息。只要颜色分布相似,就会判定二者相似度较高,显然是不合理的。(点击阅读原文,查看可以查看参考链接相关文章)
参考链接
python图像识别之图片相似度计算
图片相似度计算的几种方法
python OpenCV 图片相似度 5种算法_追求卓越,做到专业-CSDN博客_opencv 图片相似度
计算两幅图像的相似度总结_菜鸟驿站-CSDN博客_compare_ssim
某眼字体反爬分析(K近邻算法解决动态字体加密)
