




前言
首先看一个在某点评网站上一个店名的截图:

图片来源:http://www.dianping.com/shop/H5uBkrsNCLlCe7mf
然后我尝试将店名复制到文本框
炙·(楷)
是不是复制错了,这是第一反应,查看一下源码

确定了,并没有复制错,这是为什么呢?这就是反爬虫的一种手段—「字体加密」。
字体加密
原理如下图:
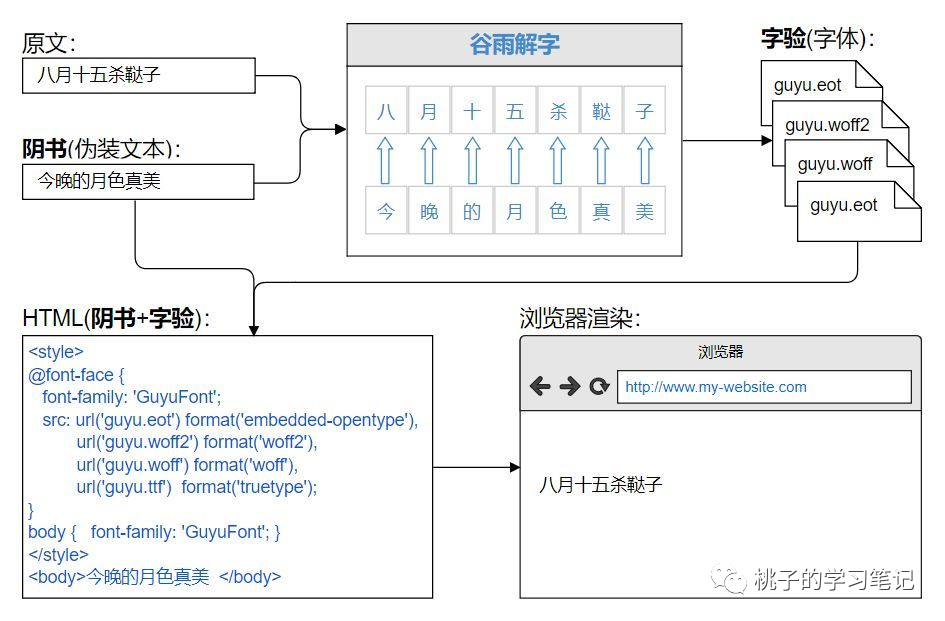
图片来源:https://guyujiezi.com
字体加密之后产生的直接影响就是,用户看到的是「原文」,但是网站的实际内容是「阴书」,在这种情况下通过爬虫爬取的原始内容很明显不是我们真正想要的。
那么如何解决这个问题呢?既然叫做加密,自然有着与之对应的解密方式。
字体解密
通过上面的原理图,不难推断出解密的方法:
找出使用的加密字体,通常都是 ttf 的文件 通过 ttf 文件处理,找出阴书在 ttf 中对应的文字
编码
明白基本的解密原理之后,就是程序化的过程,首先找到对应的字体,审查对应的文字:
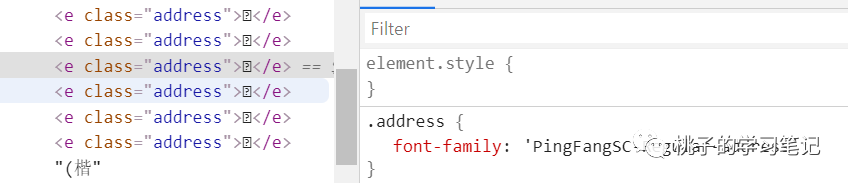
找到使用的字体

然后点击右侧的对应的 css 文件链接

下载字体到项目根目录下,我们通过一些在写预览本地字体的网站,简单看一下

通过图片不难看出阴书与原文的对应关系,接下来通过程序去完成这一过程,通过 fonttools
处理 ttf,然后获取字体和文字对应的 xml 文件
pip install fonttools
>>> from fontTools.ttLib import TTFont
>>> font = TTFont('f8354b89.woff')
>>> font.saveXML('f8354b89.xml')
下面简单地说明一下这个 xml 文件,这个文件节点有很多,但是重点有两部分:
<GlyphOrder>
<!-- The 'id' attribute is only for humans; it is ignored when parsed. -->
<GlyphID id="0" name="glyph00000"/>
<GlyphID id="1" name="x"/>
<GlyphID id="2" name="unie31f"/>
<GlyphID id="3" name="unie4dd"/>
...
</GlyphOrder>
GlyphOrder 节点下为该字体文件中所包含的文字
<TTGlyph name="unie01f" xMin="0" yMin="-98" xMax="961" yMax="818">
<contour>
<pt x="260" y="417" on="1"/>
<pt x="296" y="365" on="0"/>
<pt x="349" y="278" on="1"/>
...
</contour>
<contour>
<pt x="364" y="301" on="1"/>
<pt x="391" y="265" on="1"/>
<pt x="555" y="328" on="0"/>
...
</contour>
...
</TTGlyph>
TTGlyph 节点下,name为所绘制的文字,contour节点为字型信息,还有一些坐标(on的值 1表示直线,0表示弧形),这些坐标意味着什么呢?看一下 1 对应的 name:

接下来让我们提取 「1」 在这个字体中对应的 name 的坐标
<TTGlyph name="unie31f" xMin="0" yMin="0" xMax="361" yMax="714">
<contour>
<pt x="297" y="714" on="1"/>
<pt x="262" y="674" on="0"/>
<pt x="160" y="612" on="0"/>
<pt x="111" y="598" on="1"/>
<pt x="111" y="516" on="1"/>
<pt x="212" y="546" on="0"/>
<pt x="279" y="614" on="1"/>
<pt x="279" y="0" on="1"/>
<pt x="361" y="0" on="1"/>
<pt x="361" y="714" on="1"/>
</contour>
<instructions/>
</TTGlyph>
坐标分别为:
(297,714),(262,674),(160,612),(111,598),
(111,516),(212,546),(279,614),(279,0),(361,0),
(361,714)
接下来我们将这些坐标连线,用程序将它图形化:
import matplotlib.pyplot as plt
coordinates = ((297,714),(262,674),(160,612),(111,598),
(111,516),(212,546),(279,614),(279,0),(361,0),
(361,714))
x_coords = []
y_coords = []
for x,y in coordinates:
x_coords.append(x)
y_coords.append(y)
plt.scatter(x_coords, y_coords)
plt.xlim(-600, 1600)
plt.ylim(-600, 1600)
plt.show()
结果如下图:
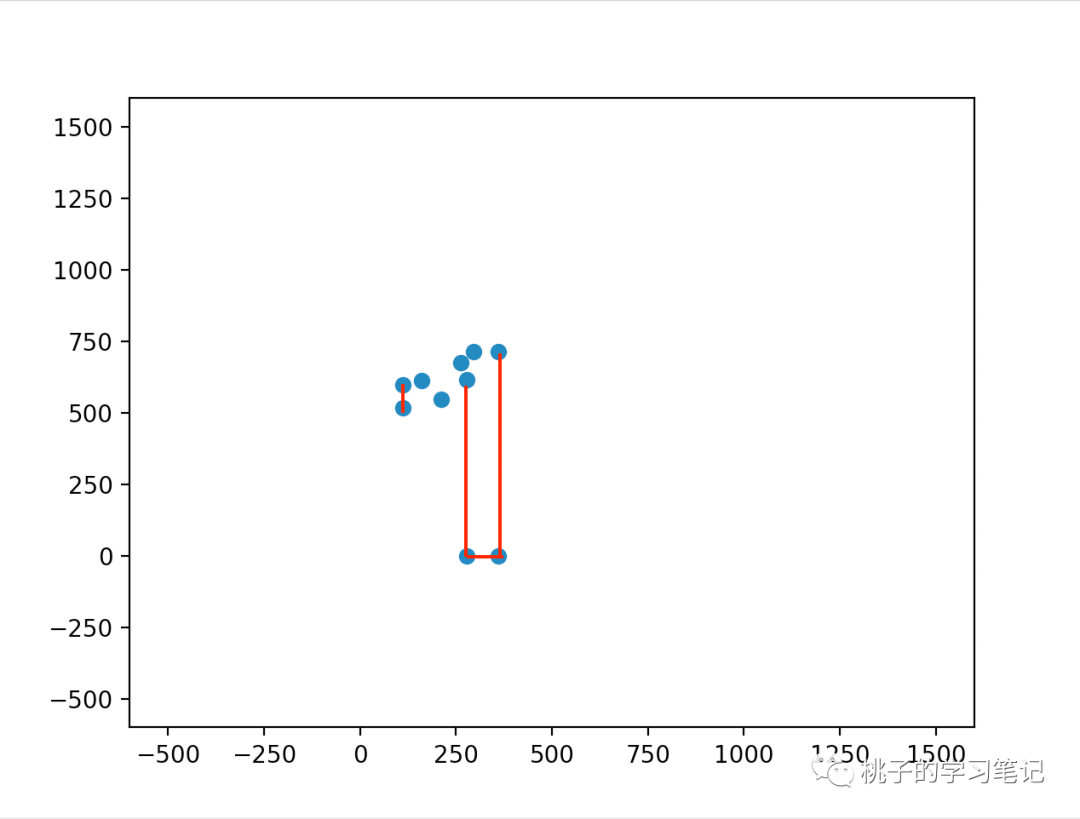
其中红色的部分,是将对应的直线连接起来了,弧线就省略了
回归正题,现在我们只需要找到对应的字和 name 的关系就可以通过 name 逆推字了。通常找出对应关系分为两种情况:
1.标准字体的name即为所绘文字的unicode16进制编码
2.非标准的则看网站的开发人员的心情了
对于情况 1 来说,这种最简单,只需要将 unicode16进制的字符转成中文即可:
# 转16进制
>>> hex(ord('十'))
'0x5341'
转回文字
>>> u'\u5341'
'十'
对于情况 2 来说,则需要手动构建字典了,或者可以将坐标绘出,然后通过 OCR 的方式,字典构建完成之后就是简单的对应关系了,剩下的代码就省略了。
参考链接
字体是如何渲染的?影响字体渲染的因素
Python crawler: Practice of font encryption and decryption - Python人
字体加密破解技术分享-01
