




原文作者:肖恩·托马斯
原文地址:PG Phriday: Nominally Bidirectional
最近亚马逊上出现了一篇专门利用pglogical 实现双向复制的博客文章。通常我们会很高兴看到用户利用 pglogical 来解决日常问题,但在这种情况下,这个话题让我们充满了恐惧感。我个人感受到了一种久经沙场的恐惧感;如果这个消息传出去,高可用之神会非常愤怒。
拜托,你所珍视的,不要这样做。做任何事,除了这个。虽然是专有的,但 BDR(双向复制)是一个扩展,专门用于将该功能安全地传递给 Postgres 。不正确地执行此操作可能会对您的业务造成积极破坏,导致数据丢失、分歧、系统中断等。我们旨在解释为什么会出现这种情况的几个原因。
锤击时间
我们都听过这句格言:对于一个有锤子的人来说,一切看起来都像钉子。pglogical 中很酷的特性之一是冲突管理功能。如果发生冲突,它允许传入行替换现有行、跳过现有数据或停止复制以进行手动干预。
此功能的纯粹目的是促进数据仓库的使用,其中多个区域节点都可以贡献给一组表以用于分析目的。结合 pglogical 可以跳过初始同步步骤的事实,总是可以在出现时添加更多区域数据源。
对于聪明的用户来说,这也意味着您可以构建双向复制方案。只需创建一个典型的逻辑副本,然后添加互惠关系,无需再次复制数据。它的简单性几乎是恶魔般的。如果故事到此结束,我们甚至会同意并提倡这个用例。
然而,老鼠和人的最佳计划往往会误入歧途。
手动干预
使用 pglogical 进行双向复制的主要问题不是构建它,而是保持它被构建。它是在流沙而不是坚固的基岩上建造的基础,所有这些都需要。想象一下一切开始都很好,我们有两个表的这种关系:
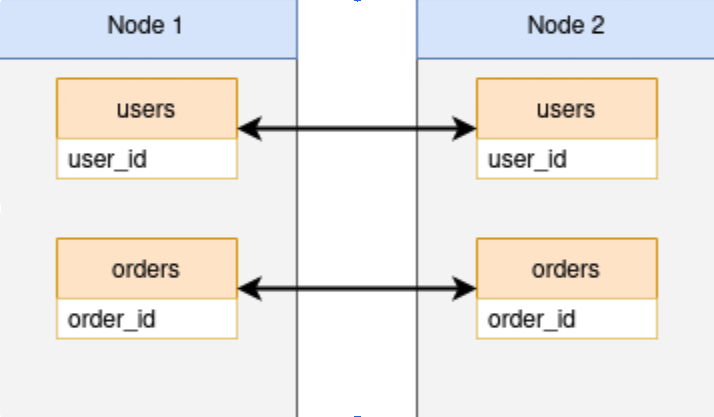
考虑在节点故障的情况下会发生什么。与本机 Postgres 逻辑复制一样,pglogical 依赖复制槽来跟踪所有订阅者节点的 LSN 位置。如果节点丢失,插槽位置也会丢失。丢失槽位置也会使逻辑订阅无效。如果节点 1 失败,我们可能认为可以通过执行以下步骤重新建立双向关系:
- 从备份中恢复节点 1。
- 删除从节点 2 到节点 1 的订阅,因为节点 1 上的复制槽已经消失。
- 重新创建从节点 2 到节点 1 的订阅,记住将synchronize_data选项设置为 false。
- 等待节点 1 赶上节点 2,因为节点 2 上的复制槽很好。
这个理论的问题在于第 4 项并不是那么直接。在使用 Postgres 逻辑复制时,实际上在接收端有两个表起着非常关键的作用:
- pg_replication_origin - 存储有关逻辑复制数据的上游源节点的信息。
- pg_replication_origin_status - 跟踪已建立的逻辑复制槽的本地和远程 LSN 位置。
复制槽的一个模糊属性是这些表指示消费节点上最后一个已知的良好位置,因此它们将快进到它请求的第一个位置。如果节点 1 在时间线中恢复得太早,则会调整这些表以匹配插槽中的第一个可用位置。这意味着我们需要将节点 1至少恢复到发生故障的 LSN,以确保步骤 1-4 的安全,否则节点 1 可能最终会丢失数据。在失败的情况下说起来容易做起来难。
鉴于这些限制,大多数 DBA 会提供一系列替代步骤来重新建立双向复制关系:从头开始重建。这意味着重新同步发布中的所有表,或者可能使用某种数据比较和验证工具来代替。然后是复制互惠订阅以使其成为双向。这必须在出现节点故障时执行。
这不仅仅是失败。复制槽当前未复制到物理流副本,因此如果节点 1 有一个名为节点 1b 的副本,则每次节点切换都需要这样做:
- 暂时禁用节点 2 上的订阅,使其与节点 1 断开连接。
- 在节点 1b 上重新创建节点 2 所需的复制槽。
- 停止节点 1 进行维护。
- 提升节点 1b。
- 在节点 2 上启用订阅。
当节点 1 重新上线时,我们需要删除节点 2 正在使用的插槽,以避免在该系统上保留过多的 WAL 文件。这必须发生在每个节点升级中,无一例外。当然可以编写脚本,但是这里有很大的失败空间,应该验证所有步骤,或者需要废弃整个过程。然后,当然,我们必须再次重建双向关系。
还要考虑这些问题是线性复合的。如果我们在集群中也有节点 3 和 4,它们也需要在节点 1 的故障转移时进行相同的处理。它们也需要在出现无法轻松解决的问题时进行相同的重建潜力。
而这只是冰山一角。
我这样做了吗?
它确实是一个罕见的数据库,将来不会创建新的表、列、索引或其他此类结构。pglogical 和本机逻辑复制最有争议的问题之一可能是它们不支持 DDL 复制。因此,每个新列、表、索引、触发器和其他模式修改都必须在所有节点上进行协调,否则可能会破坏复制。
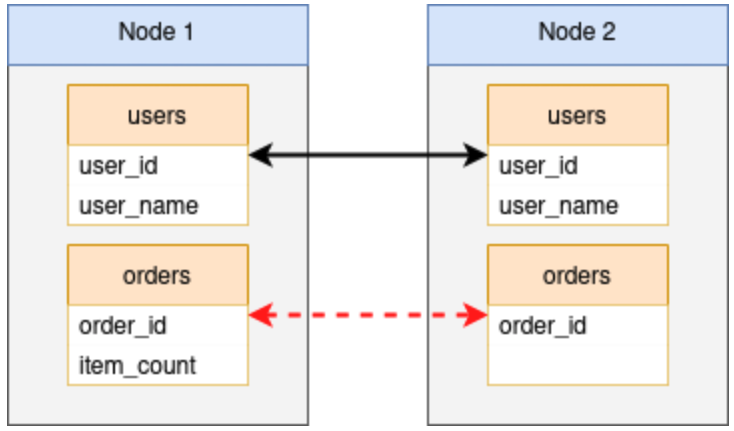
虽然 pglogical 提供了一个名为replicate_ddl_command()的函数来克服这个特殊的缺点,但它并不是万能的。必须绝对使用此功能或仅在特定情况下避免使用此功能,在可以接受短暂复制中断的逐节点迁移中。所有其他情况都会以某种方式破坏复制,这种方式只会出现在日志中,作为对丢失或其他不兼容列的有点深奥的抱怨,以及后台工作人员退出。
这里的另一个问题有点不直观:混合交易。考虑由 replicate_ddl_command()执行的这个基本事务系列:
SELECT replicate_ddl_command($BODY$ ALTER TABLE foo ADD mycol TEXT NULL; UPDATE foo SET mycol = othercol::TEXT; ALTER TABLE foo ALTER mycol SET NOT NULL; $BODY$);
此事务不仅修改基础表,还更新内容。如果另一个会话在运行时删除了othercol列,并且首先解决了这个问题,或者完全从另一个节点这样做,该怎么办?根据在每个节点上应用更改的时间,ALTER可能会运行,但UPDATE不会。replicate_ddl_command()函数通过手动将语句添加到复制队列中来工作,因此任何以这种方式中断的节点都可能需要重建订阅,具体取决于事务的复杂程度。
在逐个节点的滚动修改过程中,看似兼容的 DDL 更改可能更加隐蔽。由于 pglogical 是一个实时的逻辑复制系统,这样做可能很诱人:
ALTER TABLE foo DROP COLUMN oldcol;这将删除节点 1 上的列,然后我们可以在节点 2 上手动运行它,对吗?也许。如果节点 2 在节点 1 上的 DDL 完成之前接受了写入事务怎么办?然后它将包含缺失列的行传输到节点 1?没有意识到这一点,我们也在节点 2 上运行DROP COLUMN,它成功了。然而,节点 1 和节点 2 之间的复制被破坏,这将阻止节点 1 将来重播节点 2 的任何语句,因为复制队列中至少有一个包含oldcol的不兼容语句。
同时,节点 2 具有节点 1 上未表示的数据。在某些情况下,可以通过临时添加缺少的列或 DDL 来解决此类错误,但情况并非总是如此。通常,它必须再次通过在两个(或三个或四个)受影响节点之间重建订阅来手动解决。
冲突的真相
任何双向复制系统都必须考虑冲突。仅仅因为“冲突”一词出现在 pglogical 文档中,并不适合在双向上下文中使用。这意味着什么?
这些是 pglogical 支持的冲突类型:
- error - 如果检测到冲突,复制将停止,并且需要手动操作来解决。
- apply_remote - 始终应用与本地数据冲突的更改。
- keep_local - 保留数据的本地版本并忽略来自远程节点的冲突更改。
- last_update_wins - 将保留具有最新提交时间戳的数据版本(这可以是本地版本或远程版本)。
- first_update_wins - 将保留具有最早提交时间戳的数据版本(可以是本地版本或远程版本)。
如果系统时钟同步良好并且启用了track_commit_timestamps,则此列表中最安全的通常是last_update_wins。各种订阅上的keep_local和apply_remote的巧妙组合可以按节点完成某些类型的保留偏好,因此首选节点总是会赢得争议。但这是pglogical 可以达到的冲突管理的绝对顶峰。
事实证明,这里有一个完整的博士论文价值未处理的冲突场景,而 pglogical 不适合管理其中的任何一个。让我们回顾一些更明显的,以了解缺少的内容。
合并冲突
考虑节点 1 上的这种情况:
UPDATE account SET balance = balance + 10000 WHERE account_id = 1511;这几乎同时发生在节点 2 上:
UPDATE account SET balance = balance + 25000 WHERE account_id = 1511;
此帐户的余额将增加 10,000 或 25,000,但不会同时增加。但是两家银行分行都处理了交易并接受了结果,那我们该怎么办?如果我们遵循诸如last_update_wins之类的幼稚冲突管理规则,我们就会有一个相当愤怒的客户损失至少 10,000 美元。
与 pglogical 不同,BDR 至少可以通过三种不同的方式解决这里讨论的冲突:
- 在“帐户”表上编写自定义冲突管理触发器,拦截传入数据并将其与现有内容正确合并。这可以仅在冲突期间或对于每个传入的行发生,以防某些转换必须始终由于某种原因而发生。
- 对“余额”列使用无冲突复制数据类型(CRDT),以自动合并来自不同节点的数据并将其呈现为累积总和或增量。
- 使用 Eager Replication,它在每个节点上创建一个准备好的事务和仲裁锁定,以确保大多数节点在应用 UPDATE 之前就其效果达成一致。这种特殊的解决方案基本上直接解决了所有冲突类型,但由于共识流量,也相对较慢,被认为是最后的手段。不过,此选项对 pglogical 不可用。
列级冲突
合并冲突有一个类似但不同的变体,其中修改后的数据根本不重叠。考虑一下:
UPDATE account SET balance = balance + 10000 WHERE account_id = 1511;
这几乎同时发生在节点 2 上:
UPDATE account SET locked = true WHERE account_id = 1511;
现在我们的客户要么损失了 10,000 美元,要么他们的账户被锁定。
“可是等等!” 你可能会说,“Postgres 不是在每个节点上运行每个查询吗?”
这是一个可以理解的错误,但答案肯定是“不”。Postgres 在逻辑数据流中实际传输的是整个数据元组。所以节点 1 发送(1511, 150000, false),而节点 2 传输(1511, 140000, true),两者永远不会相遇。这是因为行内容在写入 WAL 中的磁盘之前并未真正“完成”,因为触发器、列默认值或其他影响可能会修改内容。传输的是 WAL 的内容,而不是原始 SQL 语句。
再一次,完全依赖 pglogical 进行双向复制已经丢失了我们集群中的数据。另一方面,BDR 直接支持列级冲突解决,因此修改不同列集的更新被视为更像是垂直分区的。因此,两个节点最终都存储了一个 ( 1511, 150000, true ) 元组,即使它们都没有直接收到。
插入冲突
这个更明显,但仍然是一个有效的问题。在节点 1 上,我们收到:
INSERT INTO customers (id, name) VALUES (100, 'Bob Smith');
在节点 2 上:
INSERT INTO customers (id, name) VALUES (100, 'Jane Doe');
现在我们失去了一个完整的客户,因为主键产生了冲突,我们只能保留这些行中的一个。如果帐户创建过程在数据输入进入时的几分钟内在多个相关表中创建条目,这可能会变得更加混乱。因此,每个节点可能会根据提交包含用于 Jane 或 Bob 的混合数据时间戳。
这不仅是数据完整性的灾难,我们还可能将敏感信息泄露给 Bob 或 Jane,具体取决于他们上次加载帐户视图的时间。这可能违反了GDPR,并且可能违反了其他几项信托法规,并可能导致诉讼。
这可以通过实施应用程序驱动的 ID 并具有非常明确的跟踪底层节点以防止串扰的概念来回避。也可以将基础序列增量修改为偏移量,以便节点 1 生成 1、11、21 等值,而节点 2 使用 2、12、22。但任何时候替换或添加节点时集群,这意味着总是修改所述序列,并且永远不会忘记一个,包括随着时间的推移添加的任何新序列。还有更多有问题的容易失败的解决方法。
BDR 本质上集成了两种不同的序列类型,两者都保证集群中任何节点之间不会发生冲突。一旦序列被标记为这些类型之一,BDR 通过从共识层获取的批次或通过算法生成与集群使用兼容的值来管理值。
适合工作的工具
冲突不仅仅是对虚假假设情景的事后考虑。它们是合法且关键的细节,在理想情况下必须集成到整个应用程序堆栈中。但至少,复制引擎本身必须处理或至少有助于缓解双向系统存在的基本问题。
虽然是一个非常强大的逻辑复制实用程序,但 pglogical 的设计目的并不是为了处理多个方向的复制。事实上,某些情况可能实际上会放大数据丢失情况。另一方面,BDR 是专门为解决复杂的冲突情况而编写的,而这正是 EDB Postgres Distributed 解决的问题。这就是功能和意图的区别。
我们也不能低估我们只是在本文中触及表面。与 pglogical 不同,EDB Postgres Distributed 在其他可写节点存在的假设下运行。添加一个节点会自动将其集成到其他节点中。删除它也是如此。没有我们必须在每个节点上执行的临时零碎的一系列扭曲,以确保订阅向各个方向发展。如果我们有一个 7 节点可写集群并添加一个节点,我们只是有一个 8 节点可写集群。
使用 pglogical 来模拟双向操作并不能从这种便利中受益,因此非常脆弱。在这样的星座中的任何节点上的一个错误都可能导致不得不重建整个事物。不适当的冲突管理支持最终会导致数据分歧,有时以难以察觉的方式,直到为时已晚。
EDB Postgres Distributed 并不适合所有人,我们完全理解这一点。它不是免费产品,因此尝试使用可用资源实现相同结果可能很诱人。但正如古代地图制作者对未知领域所说的那样:这里有龙。使用 pglogical 构建一个 ad-hoc 双向集群可能会在一段时间后奏效,但它会以不可预知的方式完成,并且并非没有某种迫在眉睫的灾难的暗示。
 在过去的 20 年里,Shaun 担任过各种角色,包括 DBA、数据库架构师、开发人员、顾问、会议发言人、作者等等。这些天来,他将精力集中在 Postgres 高可用性上,因为他的大部分会议演讲、网络研讨会和用户组演示......
在过去的 20 年里,Shaun 担任过各种角色,包括 DBA、数据库架构师、开发人员、顾问、会议发言人、作者等等。这些天来,他将精力集中在 Postgres 高可用性上,因为他的大部分会议演讲、网络研讨会和用户组演示......
