





(本文阅读预计时间:20分钟)
文章转载自公众号:数据库架构之美
译者注
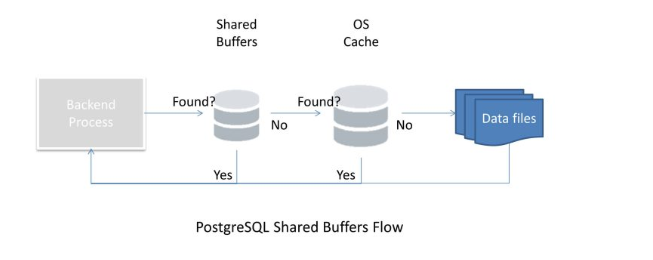
与MySQL设置innodb_buffer_pool_size = 80%左右的系统内存相比,也就是将操作系统大部分内存分配给Innodb的buffer pool的缓存管理机制不同,Postgresql采用数据库采用实例buffer和操作系统buffer双缓存(effective_cache_size)的工作模式,这一点两者还是有着比较本质上的差异的。
缓存作为数据库的一个核心组件,shared_buffers决定了数据库实例层面的可用内存,而文件系统缓存的大小是effective_cache_size决定的,effective_cache_size不仅是缓存经常访问的数据,它同时帮助优化器确定实际存在多少缓存,指导优化器生成最佳执行计划。
以下几篇文章都比较好地解释了Shared Buffers和操作系统层面文件缓存(os cache)之间的关系,可作为参考
https://www.cybertec-postgresql.com/en/effective_cache_size-what-it-means-in-postgresql/
https://wiki.postgresql.org/wiki/Tuning_Your_PostgreSQL_Server
https://severalnines.com/database-blog/architecture-and-tuning-memory-postgresql-databases
https://distributedsystemsauthority.com/optimizing-postgresql-shared-buffers/
https://www.enterprisedb.com/edb-docs/d/edb-postgres-advanced-server/user-guides/user-guide/10/EDB_Postgres_Advanced_Server_Guide.1.24.html
https://stackoverflow.com/questions/42478488/resize-shared-buffer-size-in-postgresql-hosted-in-aws-rds
https://devcenter.heroku.com/articles/understanding-postgres-data-caching
查阅到的资料上只是说了一些理论基础,比如shared buffers或者和effective_cache_size设置的过大或者过小理论上存在的问题,但是最终还是没整明白,Postgresql为什么shared buffers(建议值是25%系统内存)和effective_cache_size(建议值是50%系统内存)分配机制的背后原理,也希望有高人指点。
以下为译文。
这篇文章详细回答了以下问题:
在PostgreSQL中,你需要给共享缓冲区多少内存?为什么?
额外的福利! !
为什么我的RDS postgreSQL共享缓冲区使用系统内存的25%,而Aurora Postgresql的共享缓冲区是75%?答案就在这里。
理解PostgreSQL中的OS Cache vs Shared Buffers
在我们开始之前,首先回答一个问题:BGWriter在PostgreSQL中的作用是什么?
如果你的答案是“它把脏缓冲区写到磁盘”,那就错了。
它实际上将脏缓冲区写入OS缓存,然后进行单独的系统调用,将页面从OS缓存刷新到磁盘。
是不是不太明白吗?可以这么去理解它:
由于它轻量级的特性,PostgreSQL必须高度依赖操作系统缓存,它依赖于操作系统来了解文件系统、磁盘布局以及如何读写数据文件。
下图让您大致了解了数据如何在磁盘和share buffers之间传递。
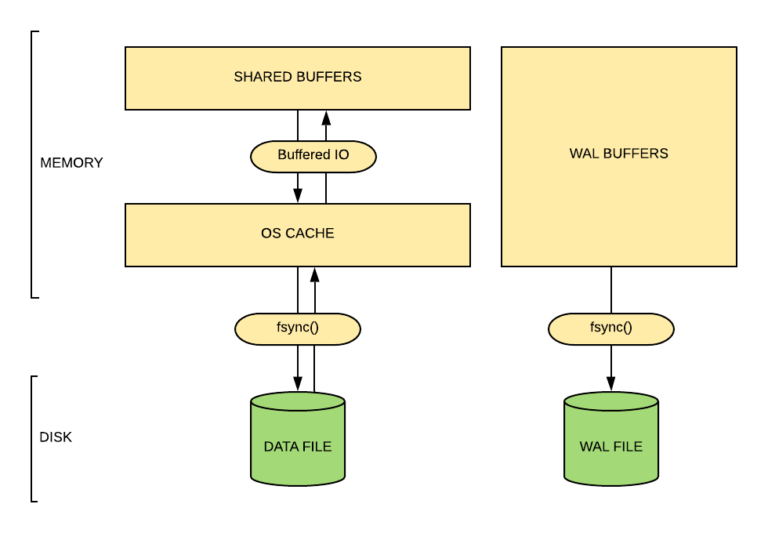
是否可以设置操作系统的fsync()方法刷新脏页到磁盘?
是的,参数在postgresql.conf文件中,bgwriter_flush_after(整数)—默认512 KB。当backend writer写入的数据超过这个数量时,尝试强制操作系统向底层存储发出这些写入操作。
这样做将限制内核页面缓存中的脏数据量,减少在检查点结束时发出fsync或操作系统在后台大量回写数据时暂停的可能性。它被用作块,即BLCKSZ字节,通常为8 KB。
不仅是bgwriter,在PostgreSQL甚至checkpoint进程和用户后端进程也可以将脏缓冲区从共享缓冲区到操作系统缓存。
即使在这里,我们也可以分别使用checkpoint_flush_after和backend_flush_after命令来影响操作系统的fsync()(尽管关于检查指针和后端进程的讨论超出了本文的范围)。
另外请参考:
checkpoint过程综合指南
https://postgreshelp.com/postgresql-checkpoint/
如果给操作系统缓存(OS Cache)分配的值太少了呢?
如上所述,一旦页面被标记为dirty,它就会被刷新到OS缓存中,然后写入磁盘。
在这里,OS可以更自由地根据传入的流量进行I/O。如果操作系统缓存的大小更小,那么它就不能重新排序写操作和优化I/O。这对于编写繁重的工作负载尤其重要。所以操作系统缓存大小也很重要。
译者注
这里提到的,如果给操作系统分片的缓存值太小,意味着将大部分内存分配给shared buffers,除了上面提到的原因,笔者查阅了很多资料,关于Postgresql实例的OS cache和shared buffers分配比例以及原因都没有一个明确的解释。
比如建议的给shared buffers分配25%的总内存,给effective_cache_size设置50%总内存的具体原理,为什么是这个比例,而不是5:5开或者是7:3开的比例?
在这里有类似问题的解释:
https://www.postgresql-archive.org/Increased-shared-buffer-setting-lower-hit-ratio-td5826899.html
如果给共享缓冲区缓存(shared buffers)的值太少怎么办?
很简单,虽然使用OS缓存进行缓存,但实际的数据库操作是在共享缓冲区中执行的。因此,在共享缓冲区中提供足够的空间是个好主意。
译者注
以下翻译来自:
https://distributedsystemsauthority.com/optimizing-postgresql-shared-buffers/
如何查看共享缓冲区的内容?
PG缓冲缓存扩展帮助我们实时查看共享缓冲区中的数据。从shared_buffers收集信息并将其放在pg_buffercache中以供查看。
create extents pg_buffercache;
安装扩展之后,执行下面的查询来检查共享缓冲区的内容。
SELECT c.relname, pg_size_pretty(count(*) * 8192) as buffered, round(100.0 * count(*) ( SELECT setting FROM pg_settings WHERE name='shared_buffers')::integer,1) AS buffers_percent, round(100.0 * count(*) * 8192 pg_relation_size(c.oid),1) AS percent_of_relation FROM pg_class c INNER JOIN pg_buffercache b ON b.relfilenode = c.relfilenode INNER JOIN pg_database d ON (b.reldatabase = d.oid AND d.datname = current_database()) WHERE pg_relation_size(c.oid) > 0GROUP BY c.oid, c.relname ORDER BY 3 DESCLIMIT 10;
输出的结果类似如下:
postgres=# SELECT c.relnamepostgres-# , pg_size_pretty(count(*) * 8192) as bufferedpostgres-# , round(100.0 * count(*) ( SELECT setting FROM pg_settings WHERE name='shared_buffers')::integer,1) AS buffers_percentpostgres-# , round(100.0 * count(*) * 8192 pg_relation_size(c.oid),1) AS percent_of_relationpostgres-# FROM pg_class cpostgres-# INNER JOIN pg_buffercache b ON b.relfilenode = c.relfilenodepostgres-# INNER JOIN pg_database d ON (b.reldatabase = d.oid AND d.datname = current_database())postgres-# WHERE pg_relation_size(c.oid) > 0postgres-# GROUP BY c.oid, c.relnamepostgres-# ORDER BY 3 DESCpostgres-# LIMIT 10;relname | buffered | buffers_percent | percent_of_relation---------------------------+------------+-----------------+---------------------pg_operator | 80 kB | 0.1 | 71.4pg_depend_reference_index | 96 kB | 0.1 | 27.9pg_am | 8192 bytes | 0.0 | 100.0pg_amproc | 24 kB | 0.0 | 100.0pg_cast | 8192 bytes | 0.0 | 50.0pg_depend | 64 kB | 0.0 | 14.0pg_index | 32 kB | 0.0 | 100.0pg_description | 40 kB | 0.0 | 14.3pg_language | 8192 bytes | 0.0 | 100.0pg_amop | 40 kB | 0.0 | 83.3(10 rows)
如何能看到数据实际上是在操作系统级别缓存的?
要检查在操作系统级别缓存的数据,我们需要安装pgfincore包。
这是一个外部模块,提供关于操作系统如何缓存页面的信息。它的级别很低,但却非常强大。
下载pgfincore并执行以下步骤:
As root user:
export PATH=/usr/local/pgsql/bin:$PATH Set the path to point pg_config.tar -xvf pgfincore-v1.1.1.tar.gzcd pgfincore-1.1.1 make cleanmake make installNow connect to PG and run below commandpostgres=# CREATE EXTENSION pgfincore;
现在执行下面的命令来检查操作系统级别的缓冲区。
select c.relname,pg_size_pretty(count(*) * 8192) as pg_buffered,round(100.0 * count(*)(select settingfrom pg_settingswhere name='shared_buffers')::integer,1) as pgbuffer_percent, round(100.0*count(*)*8192 pg_table_size(c.oid),1) as percent_of_relation,( select round( sum(pages_mem) * 4 1024,0 ) from pgfincore(c.relname::text) )as os_cache_MB ,round(100 * (select sum(pages_mem)*4096from pgfincore(c.relname::text) )/ pg_table_size(c.oid),1)as os_cache_percent_of_relation,pg_size_pretty(pg_table_size(c.oid)) as rel_sizefrom pg_class cinner join pg_buffercache b on b.relfilenode=c.relfilenodeinner join pg_database d on (b.reldatabase=d.oid and d.datname=current_database() and c.relnamespace=(select oid from pg_namespace where nspname='public'))group by c.oid,c.relnameorder by 3 desc limit 30;
输出的结果类似如下:
relname |pg_buffered|pgbuffer_per|per_of_relation|os_cache_mb|os_cache_per_of_relation|rel_size---------+-----------+------------+---------------+-----------+------------------------+--------emp | 4091 MB | 99.9 | 49.3 | 7643 | 92.1 | 8301 MB
额外的收获! !





PostgreSQL与Oracle:成本、易用性和功能上的差异



点击此处阅读原文
↓↓↓
