




经历上次transaction id 回收报警的问题后,除了上次总结后,发现对于transaction id 的回收的问题还是处于一个急需再学习的过程,所以有了下面这篇翻译的文字。
翻译————————
Postgresql 使用事务ID (txids,xids)去完成多版本控制的功能设计,相关的postgresql文档中有明确的对于 txids 的功能注解:
PostgreSQL 的 MVCC 事务的实现是依赖于比较事务ID XID 的数字来完成的,这里插入的行版本信息XID要大于当前的行事务XID ,并且当前的XID 信息在未来是不应该被可见的。
基于transaction ID 被限制在 32位的基础上,一个PG的数据库在运行一段时间,将遇到事务ID 的回卷的问题,XID计数器环绕到零,突然之间,过去的事务出现在未来,简而言之,出现了灾难性的数据丢失问题。
为了克服事务ID回卷的问题,PG 使用VACUUM 来冻结已经已经提交的事务的ID,并且并且在未来可能会释放并重新使用这些 transaction id.
Vacuum 被放到后台运行自动运行并且这里我们称之为 autovacuum 自动真空,当然也可以通过手动的 vacuum来完成类似的功能。
Autovacuum 被设计为一个低优先级的定期的任务,实际的工作效果和工作的速度和数据库本身的活动有关。在有些情况下,autovacuum 可能不能够回收事务的ID,或者不及时的回收这些ID,并且这种vacuum 工作我们也对其有一个称呼 , aggressive vacuum 或者 antiwraparound vacuum.
如果TXID 的利用率超过了回收的速度,尽管 autovacuum 做了最大的努力去工作,达到一定的程度后,数据库将停止接受数据库的操作命令,避免因为事务回卷导致的数据丢失的问题发生。
下面将介绍的是通过vacuum的功能来解决这个问题,那么基于的数据库版本是PG12, 所以下面的命令和执行必须基于PG12的版本。
Autovacuum versus manual vacuum for TXID freezing (针对事务ID 的冻结,自动真空与手动真空的不同)
以下的信息主要标明 vacuum 的操作步骤,这些信息展示在 pg_stat_progress_vacuum 视图中:
1、扫描:VACUUM 将扫描页面,如果需要的话他将对需要的页面进行重新整理,并可能进行txid的冻结工作。
2、对index的真空:真空将移除死行版本的INDEX 对应的信息
3、vacuuming heap: 删除对应的死行信息
4、尝试回收空间:vacuum 将尝试回收在文件尾部的空的页面,并将其释放给操作系统。
针对冻结过期的事务的ID的问题,扫描堆表和真空堆表的过程是必须的,但是真空索引和截断heap并不包含在操作内。因此在回收 transaction id 的过程中,跳过上面的提到的步骤是有益的。
对于大表并且附带多个索引的问题,这里会牵扯到对索引的处理中花费更多的时间在索引的处理中的部分,如果能跳过这个阶段,则VACUUM 的时间将会大大缩短。
在自动真空中是无法选择跳过那个阶段的,但是可以终止正在进行的AUTOVACUUM ,转而通过手动的方式对即将要发生 aggressive autovacuum的操作进行替换和阻止。
注意:在PG 14 中有一个新的参数 vacuum_failsafe_age 参数,他提供了与autovacuum 等效的功能,虽然PG14的用户还可以通过手动的方式来完成vacuum的工作,但是对于长期的工作来说,这个新的功能是一个更好的选择。
PostgreSQL: Documentation: 14: 20.11. Client Connection Defaults

手动VACUUM 引导
这里会对数据库做如下的工作
1、检测事务ID 的利用率,并且是针对每个数据库
2、在手动操作中,对可以取消的autovacuum操作进行标注
3、针对每个表运行VACUUM 并监控他的过程 (注:这点不大同意这个作者的说法,有必要对每个表进行操作吗,不应该先分析后在有针对性的选择 vacuum 操作吗)
4、针对已经进行VACUUMED 的表,进行索引重建 (注:这点我觉得也有问题,可以分析索引的碎片率在对部分索引进行重建)
5、在此验证操作后,事务ID 的使用的水平线是否降低
注意:尽管vacuum 操作不会引起DOWN机时间,但会增加额外的数据库负载,基于安全的考虑,建议可以CLONE 一个TEST 的数据库,并在上面进行测试工作,在确认安全后,在生产系统上进行相关的工作。
检测事务ID的利用率
通过下面的语句来展示每个数据库的相关信息
SELECT
datname,
age(datfrozenxid) AS frozen_xid_age,
ROUND(
100 *(
age(datfrozenxid)/ 2146483647.0 :: float
)
) consumed_txid_pct,
current_setting('autovacuum_freeze_max_age'):: int - age(datfrozenxid) AS remaining_aggressive_vacuum
FROM
pg_database
WHERE
datname NOT IN (
'cloudsqladmin', 'template0', 'template1'
);
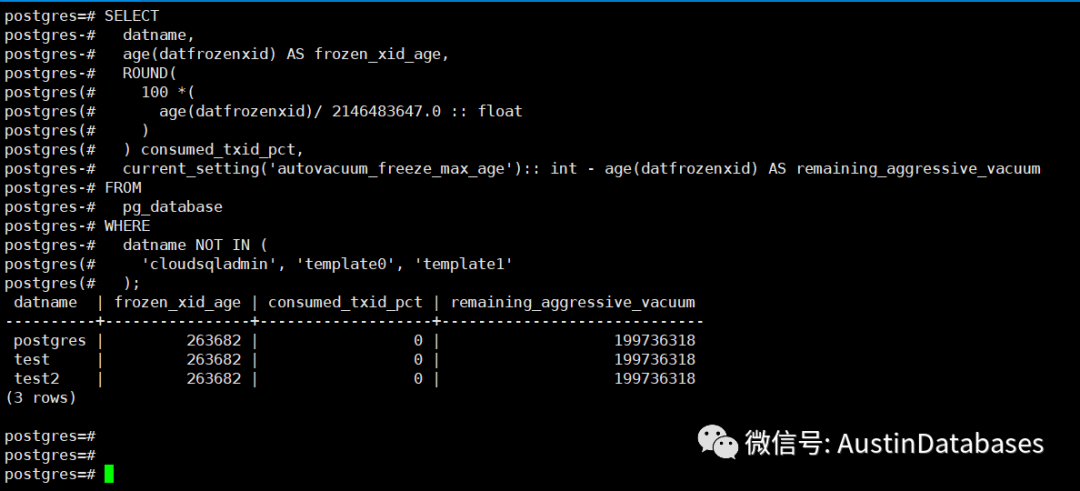
如果 consumed_txid_pct 的值超过 80% ,则说明需要对这个数据库进行必要的 vacumming 去回收 事务ID , 当然这样的表很可能已经在 AUTOVACUUM 的工作中
下面的一些后续的操作和分析的步骤
选择那些表正在进行 vacuum操作
SELECT p.pid,
p.datname,
p.query,
p.backend_type,
a.phase,
a.heap_blks_scanned / a.heap_blks_total::float * 100 AS "% scanned",
a.heap_blks_vacuumed / a.heap_blks_total::float * 100 AS "% vacuumed",
pg_size_pretty(pg_table_size(a.relid)) AS "table size",
pg_size_pretty(pg_indexes_size(a.relid)) AS "indexes size",
pg_get_userbyid(c.relowner) AS owner
FROM pg_stat_activity p
JOIN pg_stat_progress_vacuum a ON a.pid = p.pid
JOIN pg_class c ON c.oid = a.relid
WHERE p.query LIKE 'autovacuum%';
-[ RECORD 1 ]+-------------------------------------------
pid | 278394
datname | test_db
query | autovacuum: VACUUM public.sample2
backend_type | autovacuum worker
phase | scanning heap
% scanned | 80.52268841262791
% vacuumed | 0
table size | XX
indexes size | XX
owner | test_user
-[ RECORD 2 ]+-------------------------------------------
pid | 286964
datname | test_db
query | autovacuum: VACUUM public.pgbench_accounts
backend_type | autovacuum worker
phase | vacuuming indexes
% scanned | 100
% vacuumed | 0
table size | XX
indexes size | XX
owner | test_user
-[ RECORD 3 ]+-------------------------------------------
pid | 271948
datname | test_db
query | autovacuum: VACUUM ANALYZE public.sample1
backend_type | autovacuum worker
phase | scanning heap
% scanned | 22.971656445210044
% vacuumed | 0
table size | XX
indexes size | XX
owner | test_user
下面这段的翻译简化:
这段大致得意思为,在输出中发现如果长时间工作的阶段在 vacuuming indexes 则可以准备停止,并在合适的时间进行vacuum的操作,针对这个表,如果有多个大表的情况下,我们要关注在最大的表,尤其针对大表的autovacuum 的时间长度的问题。
同时给出了如何对autovacuum 正在的操作,进行停止的部分。这部分进行了省略。
主动进行vacuuming 表的操作
即使针对表进行例行的vacuum后,对于数据库的事务ID 监控并持续保证他们在较低的使用率上也是十分重要的,举例,默认postgres 针对在 aggressive vaccum 的工作中,当事务ID 的利用率达到10% ,则会触发 aggressive vacuum 的操作,这里autovacuum_freeze_max_age 设置有关。
如果您发现默认的自动真空行为不足以满足您的工作负载(例如,它通常无法足够快地回收事务id),您应该考虑调优自动真空参数。寻找最佳配置可能需要一些尝试和错误,但一个调整良好的自动真空可以减少甚至消除主动手动真空的需要。请注意,更激进的自动真空可能会影响常规工作负载的性能,因此最好以较小的增量更改和验证相关设置。
SELECT
datname,
age(datfrozenxid) AS frozen_xid_age,
ROUND(
100 *(
age(datfrozenxid)/ 2146483647.0 :: float
)
) consumed_txid_pct,
current_setting('autovacuum_freeze_max_age'):: int - age(datfrozenxid) AS remaining_aggressive_vacuum
FROM
pg_database
WHERE
datname NOT IN (
'cloudsqladmin', 'template0', 'template1'
);
如果这个值仍然很高,那么它可能是由前面过程中没有涉及到的某些表驱动的。您可以在表级别获取TXID信息,以识别仍然需要清理的表。
例如,该查询将显示按事务ID使用率排序的前10个表:
SELECT c.relname AS table_name,
age(c.relfrozenxid) AS frozen_xid_age,
ROUND(100 * (age(c.relfrozenxid) / 2146483647)) AS consumed_txid_pct,
pg_size_pretty(pg_total_relation_size(c.oid)) AS table_size
FROM pg_class c
JOIN pg_namespace n ON c.relnamespace = n.oid
WHERE c.relkind IN ('r', 't', 'm')
AND n.nspname NOT IN ('pg_toast')
ORDER BY 2 DESC
LIMIT 10;
翻译完毕————————
翻译原文连接:
https://cloud.google.com/blog/products/databases/how-to-accelerate-transaction-id-freezing-in-cloud-sql-for-postgresql



