




前言:前段时间因为项目需求,需要开发一个实时采集分析日志的任务,最后选择的计算框架是Flink。项目完成后,基本上就没再接触。但总觉得既然用过了,不了解,不清楚,日后又需要还得重新看,很亏啊 ! 所以决定抽空总结一下,一方面可以跟大家交流分享一下新的学习内容,共同进步;另一方面也能更深入的了解传说中的下一代大数据实时计算神器。
这篇文章主要按照以下思路,简单的交流一下Flink的基本概念和用途。自知资历尚浅,见闻有限,如有纰漏还望指正!
1. Flink 简介
在当前的互联网用户,设备,服务等激增的时代下,其产生的数据量已不可同日而语了。各种业务场景都会有着大量的数据产生,如何对这些数据进行有效地处理是很多企业需要考虑的问题。以往我们所熟知的Map Reduce,Storm,Spark等框架可能在某些场景下已经没法完全地满足用户的需求,或者是实现需求所付出的代价,无论是代码量或者架构的复杂程度可能都没法满足预期的需求。新场景的出现催产出新的技术,Flink即为实时流的处理提供了新的选择。Apache Flink就是近些年来在社区中比较活跃的分布式处理框架,加上阿里在中国的推广,相信它在未来的竞争中会更具优势。 Flink的产生背景不过多介绍,感兴趣的可以Google一下。Flink相对简单的编程模型加上其高吞吐、低延迟、高性能以及支持exactly-once语义的特性,让它在工业生产中较为出众。相信正如很多博客资料等写的那样"Flink将会成为企业内部主流的数据处理框架,最终成为下一代大数据处理标准。"
2. Flink 架构中的服务类型
下面是从Flink官网截取的一张架构图:
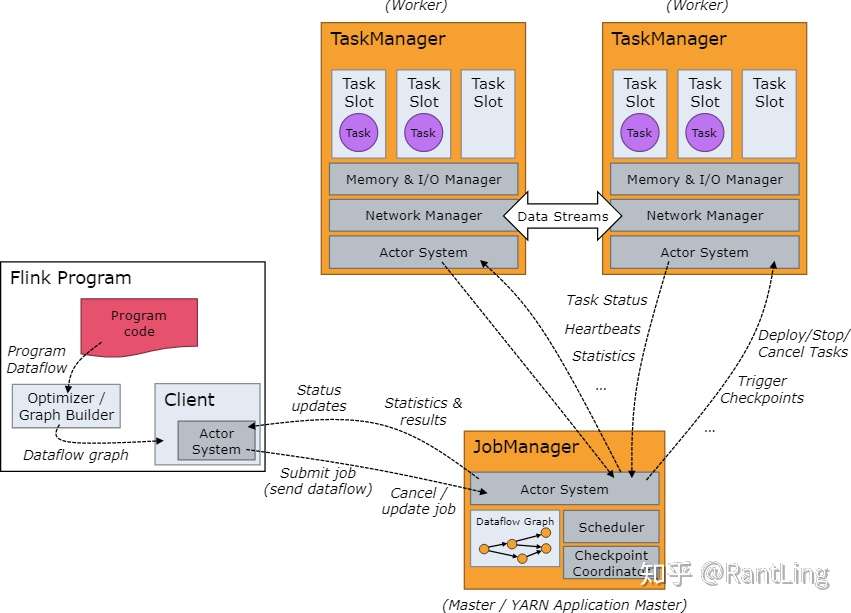
在Flink运行时涉及到的进程主要有以下两个: JobManager:主要负责调度task,协调checkpoint已经错误恢复等。当客户端将打包好的任务提交到JobManager之后,JobManager就会根据注册的TaskManager资源信息将任务分配给有资源的TaskManager,然后启动运行任务。TaskManger从JobManager获取task信息,然后使用slot资源运行task; TaskManager:执行数据流的task,一个task通过设置并行度,可能会有多个subtask。 每个TaskManager都是作为一个独立的JVM进程运行的。他主要负责在独立的线程执行的operator。其中能执行多少个operator取决于每个taskManager指定的slots数量。Task slot是Flink中最小的资源单位。假如一个taskManager有3个slot,他就会给每个slot分配1/3的内存资源,目前slot不会对cpu进行隔离。同一个taskManager中的slot会共享网络资源和心跳信息。
当然在Flink中并不是一个slot只可以执行一个task,在某些情况下,一个slot中也可能执行多个task,如下:
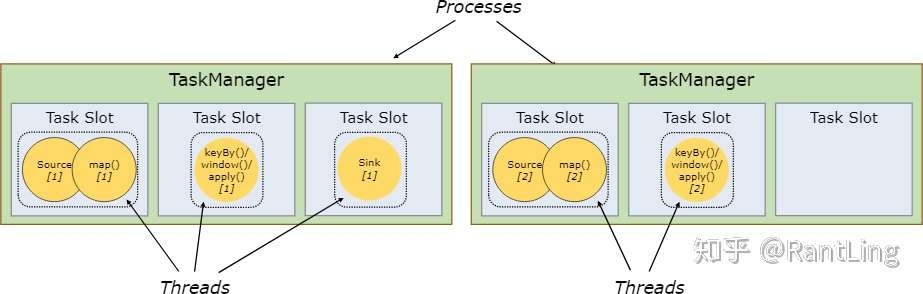
一般情况下,flink都是默认允许共用slot的,即便不是相同的task,只要都是来同一个job即可。共享slot的好处有以下两点:
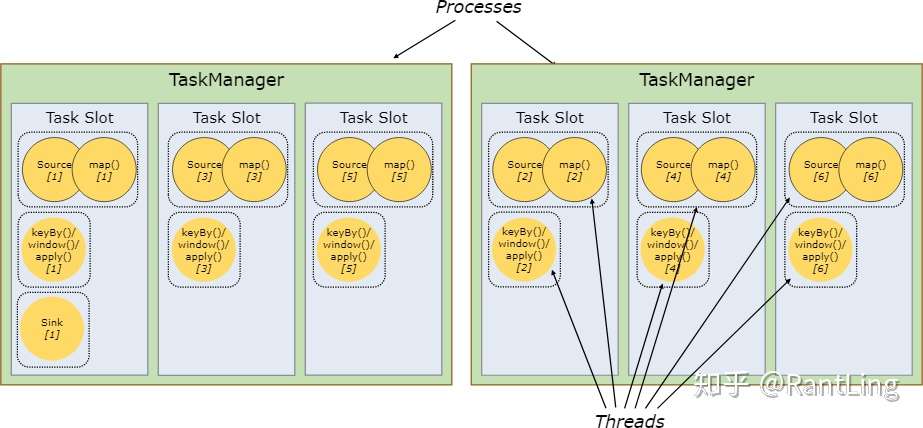
1. 当Job的最高并行度正好和flink集群的slot数量相等时,则不需要计算总的task数量。例如,最高并行度是6时,则只需要6个slot,各个subtask都可以共享这6个slot; 2. 共享slot可以优化资源管理。如下图,非资源密集型subtask source/map在不共享slot时会占用6个slot,而在共享的情况下,可以保证其他的资源密集型subtask也能使用这6个slot,保证了资源分配。
3. Flink中的数据
Flink中的数据主要分为两类:有界数据流(Bounded streams)和无界数据流(Unbounded streams)。
