




Flink 项目是大数据计算领域冉冉升起的一颗新星。大数据计算引擎的发展经历了几个过程,从第 1 代的 MapReduce,到第 2 代基于有向无环图的 Tez,第 3 代基于内存计算的 Spark,再到第 4 代的 Flink。
如果你希望了解各种流式计算框架的区别,请转到:大数据流式计算框架汇总和对比
因为 Flink 可以基于 Hadoop 进行开发和使用,所以 Flink 并不会取代 Hadoop,而是和 Hadoop 紧密结合。
Flink 主要包括 DataStream API、DataSet API、Table API、SQL、Graph API 和 FlinkML 等。现在 Flink 也有自己的生态圈,涉及离线数据处理、实时数据处理、SQL 操作、图计算和机器学习库等。
Flink 是什么?
很多人是在 2015 年才听到 Flink 这个词的,其实早在 2008 年,Flink 的前身就已经是柏林理工大学的一个研究性项目,在 2014 年这个项目被 Apache 孵化器所接受后,Flink 迅速成为 ASF(Apache Software Foundation)的顶级项目之一。截至目前,Flink 的版本经过了多次更新。
Flink 是一个开源的流处理框架,它具有以下特点:
- 分布式:Flink 程序可以运行在多台机器上。
- 高性能:处理性能比较高。
- 高可用:由于 Flink 程序本身是稳定的,因此它支持高可用性(High Availability,HA)。
- 准确:Flink 可以保证数据处理的准确性。
Flink 主要由 Java 代码实现,它同时支持实时流处理和批处理。对于 Flink 而言,作为一个流处理框架,批数据只是流数据的一个极限特例而已。
此外,Flink 还支持迭代计算、内存管理和程序优化,这是它的原生特性。
由图1可知,Flink 的功能特性如下:
- 流式优先:Flink 可以连续处理流式数据。
- 容错:Flink 提供有状态的计算,可以记录数据的处理状态,当数据处理失败的时候,能够无缝地从失败中恢复,并保持 Exactly-once。
- 可伸缩:Flink 中的一个集群支持上千个节点。
- 性能:Flink 支持高吞吐、低延迟。

图1:Flink的功能特性
在这里解释一下,高吞吐表示单位时间内可以处理的数据量很大,低延迟表示数据产生以后可以在很短的时间内对其进行处理,也就是 Flink 可以支持快速地处理海量数据。
Flink流处理(Streaming)与批处理(Batch)
在大数据处理领域,批处理与流处理一般被认为是两种截然不同的任务,一个大数据框架一般会被设计为只能处理其中一种任务。比如,Storm 只支持流处理任务,而 MapReduce、Spark 只支持批处理任务。
Spark Streaming 是 Apache Spark 之上支持流处理任务的子系统,这看似是一个特例,其实不然——Spark Streaming 采用了一种 Micro-Batch 架构,即把输入的数据流切分成细粒度的 Batch,并为每一个 Batch 数据提交一个批处理的 Spark 任务,所以 Spark Streaming 本质上还是基于 Spark 批处理系统对流式数据进行处理,和 Storm 等完全流式的数据处理方式完全不同。
通过灵活的执行引擎,Flink 能够同时支持批处理任务与流处理任务。在执行引擎层级,流处理系统与批处理系统最大的不同在于节点间的数据传输方式。
如图2所示,对于一个流处理系统,其节点间数据传输的标准模型是,在处理完成一条数据后,将其序列化到缓存中,并立刻通过网络传输到下一个节点,由下一个节点继续处理。
而对于一个批处理系统,其节点间数据传输的标准模型是,在处理完成一条数据后,将其序列化到缓存中,当缓存写满时,就持久化到本地硬盘上;在所有数据都被处理完成后,才开始将其通过网络传输到下一个节点。
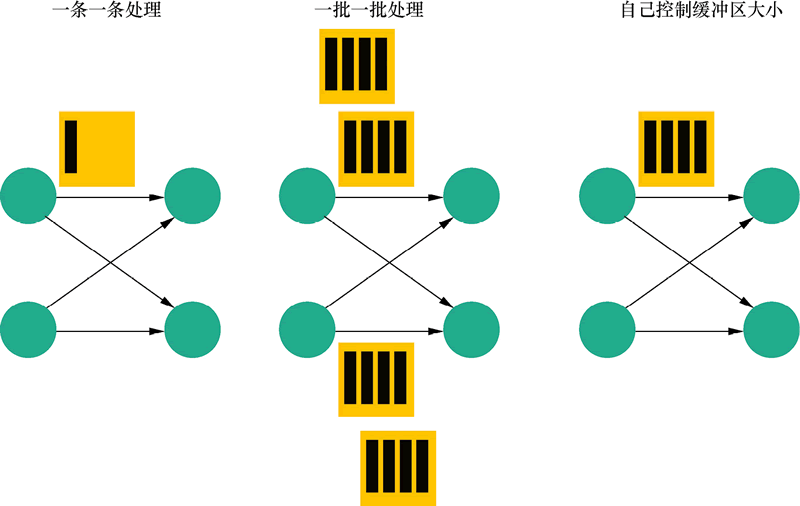
图2:Flink的3种数据传输模型
这两种数据传输模式是两个极端,对应的是流处理系统对低延迟和批处理系统对高吞吐的要求。Flink 的执行引擎采用了一种十分灵活的方式,同时支持了这两种数据传输模型。
Flink 以固定的缓存块为单位进行网络数据传输,用户可以通过设置缓存块超时值指定缓存块的传输时机。
- 如果缓存块的超时值为 0,则 Flink 的数据传输方式类似于前面所提到的流处理系统的标准模型,此时系统可以获得最低的处理延迟;
- 如果缓存块的超时值为无限大,则 Flink 的数据传输方式类似于前面所提到的批处理系统的标准模型,此时系统可以获得最高的吞吐量。
缓存块的超时值也可以设置为 0 到无限大之间的任意值,缓存块的超时阈值越小,Flink 流处理执行引擎的数据处理延迟就越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量。
Flink典型应用场景
Flink 主要应用于流式数据分析场景,目前涉及如下领域:
| 应用领域 | 说明 |
|---|---|
| 实时 ETL | 集成流计算现有的诸多数据通道和 SQL 灵活的加工能力,对流式数据进行实时清洗、归并和结构化处理;同时,对离线数仓进行有效的补充和优化,并为数据实时传输提供可计算通道。 |
| 实时报表 | 实时化采集、加工流式数据存储;实时监控和展现业务、客户各类指标,让数据化运营实时化。 |
| 监控预警 | 对系统和用户行为进行实时检测和分析,以便及时发现危险行为。 |
| 在线系统 | 实时计算各类数据指标,并利用实时结果及时调整在线系统的相关策略,在各类内容投放、无线智能推送领域有大量的应用。 |
Flink在如下类型的公司中有具体的应用:
- 优化电商网站的实时搜索结果:阿里巴巴的基础设施团队使用 Flink 实时更新产品细节和库存信息(Blink)。
- 针对数据分析团队提供实时流处理服务:通过 Flink 数据分析平台提供实时数据分析服务,及时发现问题。
- 网络/传感器检测和错误检测:Bouygues 电信公司是法国著名的电信供应商,使用 Flink 监控其有线和无线网络,实现快速故障响应。
- 商业智能分析 ETL:Zalando 使用 Flink 转换数据以便于将其加载到数据仓库,简化复杂的转换操作,并确保分析终端用户可以更快地访问数据(实时ETL)。
