戳上面的蓝字关注我吧!
戳上面的蓝字关注我吧!

软件程序分析原理 datalog编程
int count=0;Iterator<Student> iter = sudents.iterator();while(iter.hasNext()){Student s = iter.next();if(s.getAge() < 18){count++;}}
int count = sudents.stream().filter(s -> s.getAge() < 18).count();
只需要用一行lambda表达式声明即可,程序自己会将sudents转为stream流,并通过filter定义的筛选内容计算最后的count值。
声明式就是如此,相对来说代码简洁、可读性也更强。这种编程语言就是一种DSL(领域特定语言,Domain Specific Language),用于某一个特定领域的程序设计语言。而Datalog就是这样一种DSL,是Prolog的子集,其Datalog本名可以看作“Data+Logic”,接下来着重讲讲Datalog的一些理念。
Data中包含了谓词和原子两个概念
谓词(Predicate)

如上这个表为balance表,则balance就是一个谓词,在balance表中("zhangsan",1800)表示“张三有1800元”,这是一个事实,而("lisi",5200)表示“李四有5200元”,该数据不存在,因此这不是一个事实。
原子(Atoms)
通常可以将Datalog的谓词分为两大类,即EDB和IDB:
EDB(Extensional database):EDB谓词是预先定义好的,通常不可变,作为datalog的输入(即外部传入,extensional)。
IDB(Intensional database):IDB 谓词通常由rules推导出,通常是datalog的输出。
并且在Datalog的规则中可以支持递归性
Reach(from,to) <- Edge(from, to).Reach(from,to) <- Reach(from, node), Reach(node, to)
我会在这一小节着重介绍Datalog是如何做指针分析,并重点从上下文不敏感分析和上下文敏感分析两个部分讲解。
上下文不敏感分析
在做上下文不敏感指针分析的时候,之前介绍的几个概念在这里分别代表如下角色:
EDB:程序句法上可获得的指针相关信息。
IDB:指针分析的结果。
Rules:指针分析的规则。
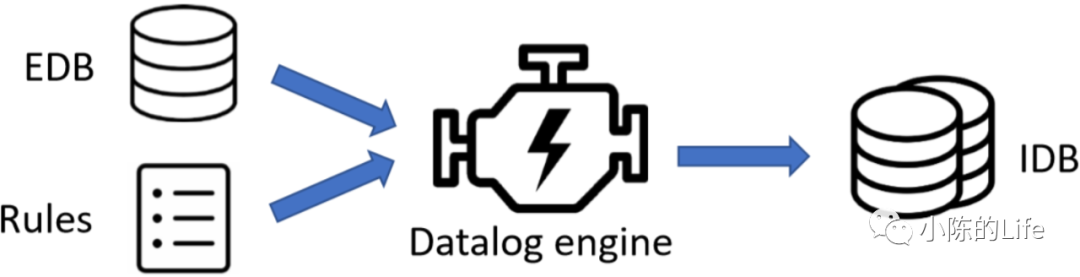
EDB定义了变量集合为V,域为F,对象为O。并经过如New/Assign/Store/Load语句的时候,会提取如上语句为EDB:
New(x: V,o: O) <- i: x = new T()
Assign(x : V, y : V) <- x=y
Store(x : V, f : F, y : V) <- x.f = y
Load(y : V, x : V, f : F) <- y = x.f
再来看看IDB会输出什么东西:
VarPointsTo(v: V, o : O) ,如VarPointsTo(x,oi)表示oi ∈ 𝑝𝑡(𝑥)。pt是point-to set缩写。
FieldPointsTo(oi : O, f: V, oj : O) ,如FieldsPointsTo(𝑜i, 𝑓, 𝑜j)表示𝑜j ∈ 𝑝𝑡(𝑜i.𝑓)。
最后综合EDB、IDB和Rules可以得出:
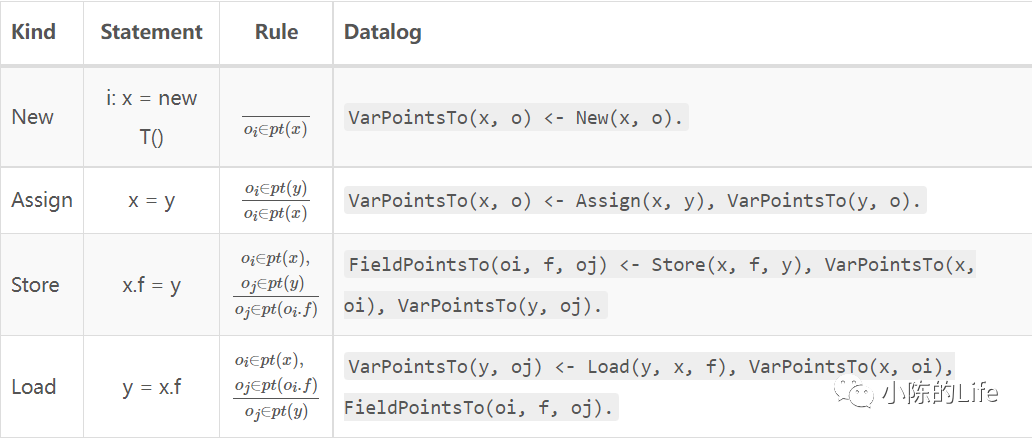
这里的Rule分母是IDB,分子是EDB。
读者如果在这里看不懂规则,可以停下来稍微多看几眼有个印象,并结合后续分析慢慢深入理解。
这里借用南大软件分析课程Reference[2]的图来讲解。
程序会先将EDB指令,变成如下表格形式


b = new C();c = new C();
之前介绍指针分析的IDB的时候说过VarPointsTo(x,oi)表示oi ∈ 𝑝𝑡(𝑥)。因此可以得出上图中的o1属于point(b)、o3属于point(c)。
再往后执行Rules,会解析Assign语句,看到之前的表格中的Statement中表达式是x = y,因此Example中属于x = y的表达式语句有如下:
a = b;d = c;


c.f = d;
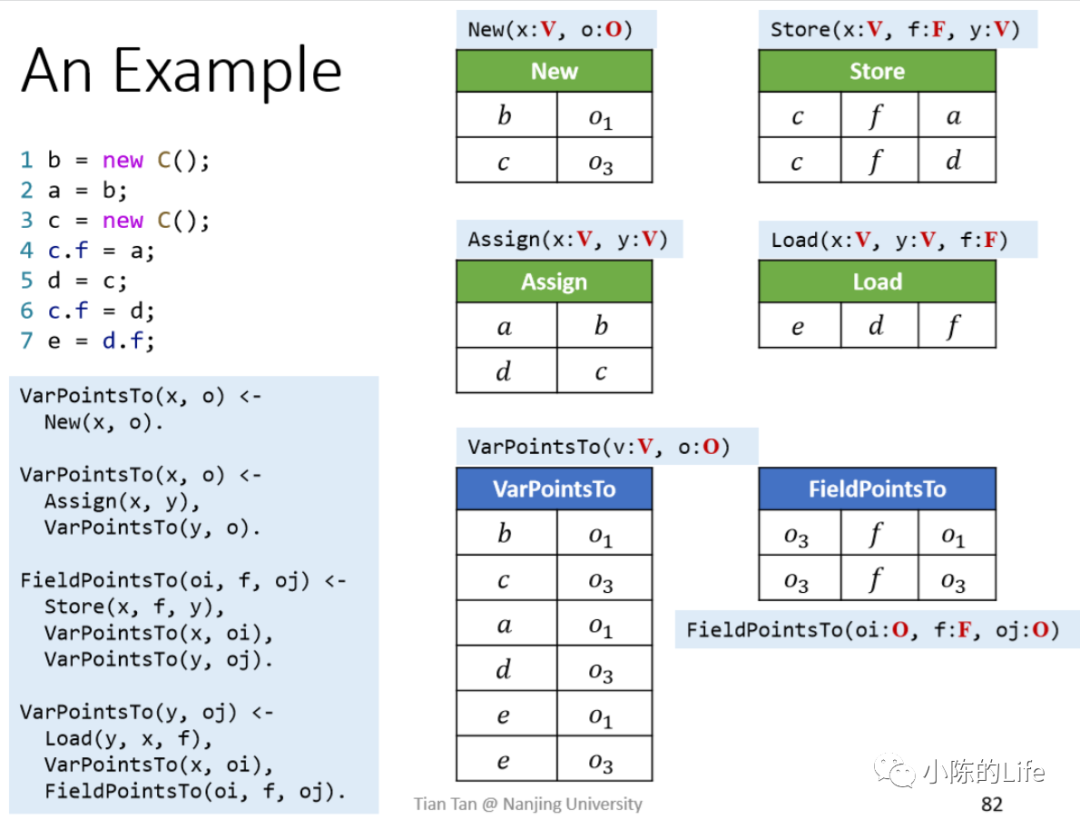
在Example中Load语句对应的代码是e = d.f;。读者在这里可以看到,虽然Example中并没有直接对d.f字段的赋值操作,但是有对应的fact可以通过VarPointsTo查询到,并把oi带入FieldPointsTo对应上该f字段对应的o1和o3。如果读者在这里疑惑,为什么我Example中第4行c.f = a;赋值了a,并在第6行又覆盖了c.f字段的变量,而这里最后IDB中VarPointsTo中的值还是加上了a变量的o1?其实这就是上下文不敏感分析的原理,不会过度关注代码的执行逻辑,因此也有该分析的痛点:大大降低了分析的精度。
上下文敏感分析
这一章节会多引进几个EDB和IDB概念,在Call指令中的EDB,定义了S代表指令,M代表方法。且共有3条Rules:
先来看第一个Rule

引进了如下3个EDB和2个IDB:
VCall(l:S,x:V,k:M):调用本身的信息,指令l,变量x,方法k。
Dispatch(o:O,k:M,m:M):根据对象o给定的方法k,找到实际调用的方法m。
ThisVar(m:M,this:V):获取m方法中的this变量。
Reachable(m:M):表示m方法可达。
CallGraph(l:S,m:M):表示l指令到m方法有一条调用边。
如此一来就添加了方法调用的调用图。
再来看看第二个Rule中,该Rule是对参数传递的规则:

其中EDB的内容Arg和Param对应实参和形参
Argument(l:S,i:N,ai:V):对应方法调用中的实参,l是调用点,i是代表方法调用中的第几个参数(索引),a是对应的参数变量。
Parameter(m:M,i:N,pi:V):m是调用的函数,i是调用的参数索引,p对应的参数变量。
再来看看这个规则,如果存在l到m的CallGraph调用边,就取出实参ai和形参pi,并最终都指向o。
再来看看第三条Rule:

该Rule有两个EDB:
MethodReturn(m:M,ret:V):m被调用函数的返回值是ret。
CallReturn(l:S,r:V):l调用点所接收的变量是r。
规则会先判断l到m是否存在一条调用边,并取出m函数的返回值ret,以及查询ret指向的对象o,并和l调用点的接受变量r对应上。
全程序指针分析

EDB谓词: Source(m:M):产生污点源的函数,通常是用户可控数据的输入点。 Sink(m:M):污点的汇聚点,污点在此处沉淀,并产出对应的分析报告。 Taint(l:S,t:T):关联调用点l和它产生的污点数据t的相关CallSite信息 IDB谓词: TaintFlow(t:T,m:M):表示污点数据t最终会在Sink函数m中汇聚。







Datalog总体来说分析实现简单,只需要通过规则的编写和相关污点函数的定义就能对程序进行跟踪。这种涉及理念是不是觉得有点像LGTM的QL查询,只需要通过简单的声明式语言编写分析语句即可。对很多安全人员来说实现简单,可读性很强。同时上述指针分析和污点分析的形同点在于污点分析是关注Source到Sink的传播流,而指针分析是关注对象和变量之间的传播。
想去研究代码实践的读者们可以了解一下Reference[4]的jatalog项目,同时如果对这门分析课程感兴趣的读者也可以看看南大的李樾、谭添老师开的软件分析公开课(Reference[2]),相关详细的ppt也可以在(Reference[5])中找到。
上章节介绍了Datalog的原理,以及如何进行数据流分析的。
Souffle是一款受Datalog启发的逻辑编程语言,其设计之初就是为了方便Oracle实验室的成员进行逻辑静态代码分析。Souffle支持的应用广泛,包括但不限于有Java的静态代码分析、并行编译器、二进制反汇编器、云计算的安全分析和智能合约的分析。而应用广泛且强大的Java指针分析程序Doop(Reference[1])就是以Souffle为datalog引擎。
这里我们就重点关注Souffle在ByteCodeDL中的实际应用部分。
先来学习一下Souffle的声明式表达是如何分析的
Souffle中的主要语言元素是关系声明(relation declarations)、事实(facts)、规则(rules)和指令(directives)。
认识了上面我介绍的Datalog语法,再来看看Souffle是如何定义规则的。这里我在我的Ubuntu上装好了souffle引擎。假设有如下example.dl规则:
.decl edge(x:number, y:number).input edge.decl path(x:number, y:number).output pathpath(x, y) :- edge(x, y).path(x, y) :- path(x, z), edge(z, y).
.decl声明了一个edge关系,寓意x到y的一条有向边;path是声明了一个可达路径,表示x到y有一条可达路径。
.input <filename>会在当前目录中读取filename.facts文件内容。
而.output <filename>会输出一个filename.csv文件。
规则的最后两行表示:
如果存在一条x到y的有向边(edge),则表示也存在一条x到y的可达路径(path)。
如果x到z有一条可达路径,且z到y存在一条有向边,则表示x到y也存在一条可达路径。
而input指定的edge.facts文件里面的内容是
1 22 3
之后在Ubuntu系统中通过以下命令运行souffle引擎检测:
$ ./souffle -F. -D. example.dl
参数设定:
-F 指定了facts所在的目录
-D 指定了输出目录
example.dl 指定datalog文件名
之后output输出的path.csv结果集内容是
1 22 31 3
上述定义的变量是number数值类型,关于souffle支持的类型可以去souffle的官网查看,其类型大致分为如下四种:
Symbol type: symbol
Signed number type: number
Unsigned number type: unsigned
Float number type: float
使用soot生成对应的jimple的IR文件。 将jimple文件再转换datalog的facts。 使用souffle引擎加载Rules并进行分析,并输出分析结果。
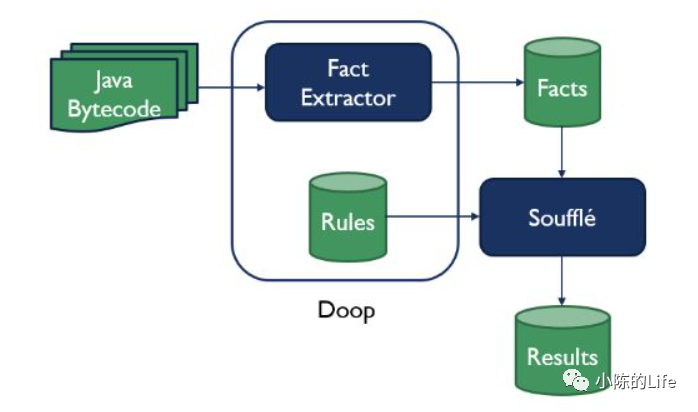
从Doot的分析流程中可以得出来,分析程序会分为上述三个步骤,我们再回过头来看看ByteCodeDL的分析。
通过Doot提供的一个Soot生成facts小工具,来生成对应的jar包中的facts。
java -jar soot-fact-generator.jar -i SIDemo.jar -l usr/lib/jvm/java-8-openjdk-amd64/jre/lib/rt.jar --generate-jimple --allow-phantom --full -d out
-i 指定待分析的jar包 -l 指定依赖库 --generate-jimple 表示生成中间语言jimple --allow-phantom 大概是允许解析依赖不存在的类 --full 表示对所有class进行解析 -d 指定输出目录
进入out目录下面,会生成很多facts文件
但是我在这里发现一个bug,工具生成jimple并不支持SpringBoot程序。而需要soot生成对应的jimple文件是需要对应依赖项的,也就是需要把SpringBoot的lib下面的所有jar包加入到soot的classpath目录中。
于是乎我修改了Doop工具的soot-fact-generator生成工具,将判断-i参数指定的jar文件中是否存在“BOOT-INF/lib(classes)”的路径,如果存在则将路径下的所有依赖解压到当前目录的lib(classes)目录下,否则不做处理。
在生成过程中,如果遇到了OutOfMemory异常,并提示Java heap space,则是给的堆空间小了,加上jvm参数-Xms200m -Xmx4096m即可(根据机器配置而定)。
如果你是跑在虚拟机上,一定要多给虚拟机几核CPU。因为程序中会通过循环遍历所有依赖的类,并生成对应的中间语言,我这里用的SpringBoot的靶场,Xmx参数可以给高一点,这样程序能更快的得出结果。之后就能在out/jimple目录下看到生成的中间语言。
至此,分析流程的三部曲已经完成前两步了,还差最后一步对生成的事实进行分析。
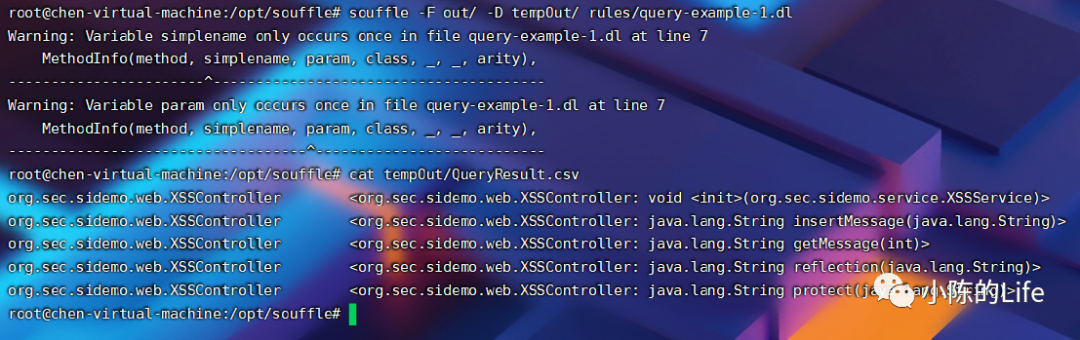
比如我这里想检索所有的方法中,有没有类名包含XSSController的方法,并输出。
于是我编写了如下的datalog规则:
#include "inputDeclaration.dl".decl QueryResult(class:Class, method:Method).output QueryResultQueryResult(class, method) :-MethodInfo(method, simplename, param, class, _, _, arity),contains("XSSController", class),arity = 1.
EDB中是从soot-fact-generator.jar工具生成的facts文件读入,并输出最后的csv结果。
至于inputDeclaration.dl,是针对souffle规则和生成好的facts定义的类和方法等属性名称。
打开inputDeclaration.dl文件,前几行就是基础变量属性定义
// 指令 可以定位出动作(比如call,load,sotre,assign)发生时的代码位置.type Insn <: symbol// 变量.type Var <: symbol// 堆 也可以理解为内存中的对象.type Heap <: symbol// 字段.type Field <: symbol// 方法.type Method <: symbol// 类.type Class <: symbol
在里面就定义了上面用到的MethodInfo的EDB输入
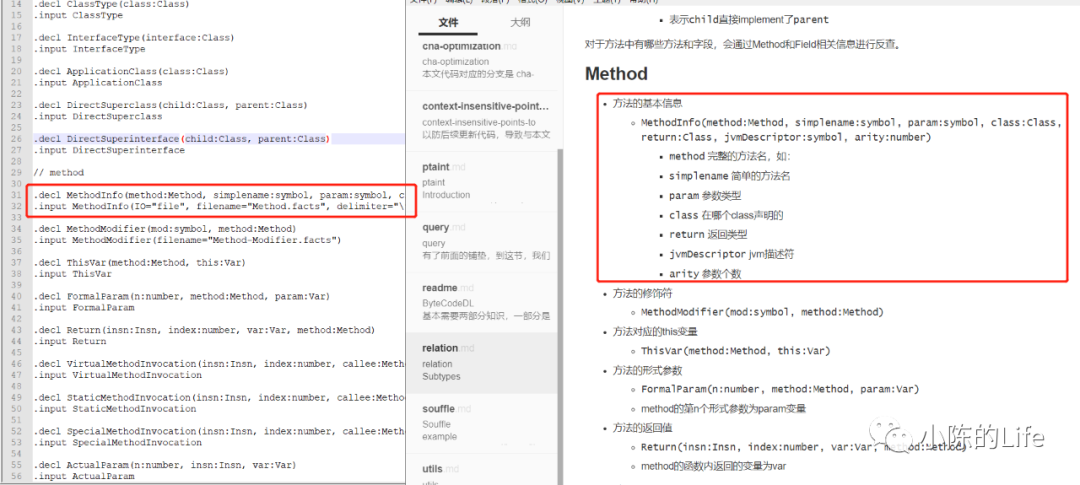
可以明确看到
.input MethodInfo(IO="file", filename="Method.facts", delimiter="\t")
程序是直接从Method.facts中读入数据,并对其进行分析。
定义污点分析规则
先来看看污点源参数是如何定义的,这里拿之前的SpringBoot的靶场SIDemo来说明案例。
先来看看对应的XSSController的Jimple中间代码:
public java.lang.String reflection(java.lang.String){org.sec.sidemo.web.XSSController this#_0;java.lang.String message#_0, $stack3;org.sec.sidemo.service.XSSService $stack2;this#_0 := @this: org.sec.sidemo.web.XSSController;message#_0 := @parameter0: java.lang.String;$stack2 = this#_0.<org.sec.sidemo.web.XSSController: org.sec.sidemo.service.XSSService xssService>;$stack3 = interfaceinvoke $stack2.<org.sec.sidemo.service.XSSService: java.lang.String reflection(java.lang.String)>(message#_0);return $stack3;}
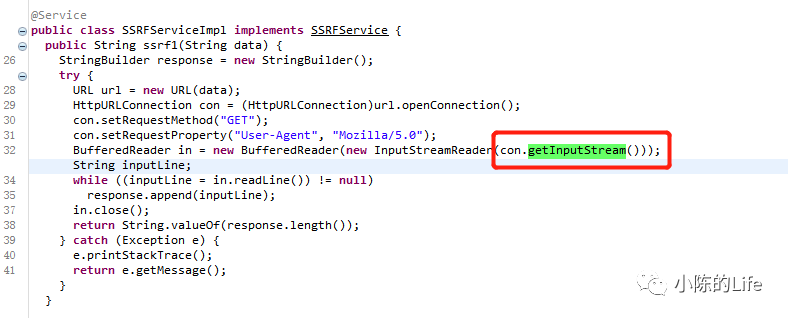
这里我贴了XSSController的reflection方法的IR代码,其源代码如下图所示

可以很清楚的知道污点参数是reflection方法的第一个RequestParam注解的参数message,后经过xssService的reflection方法返回之后直接由@ResponseBody注解返回到了页面上。所以我们的首要目的就是讲该RequestParam注解的参数标记上污点。
这里我先贴出相关的souffle规则代码:
#include "inputDeclaration.dl"#include "utils.dl"#include "ptaint.dl".init ptaint = PTaint //定义P/Taint指针分析ptaint.cipt.Reachable("<org.sec.sidemo.web.XSSController: java.lang.String reflection(java.lang.String)>"). //定义入口函数ptaint.SourceMethodArg("<org.sec.sidemo.web.XSSController: java.lang.String reflection(java.lang.String)>",0). //因为后续会检测RequestParam注解是打在哪个参数上,所以这里的0不是this对象,而是reflection的参数。.decl TaintVar(heap:Heap,var:Var)TaintVar(heap,var) :-ptaint.cipt.VarPointsTo(heap, var), //heap就是污点标记,这里将污点标记到var上ptaint.TaintHeap(_, heap). //创建污点//因为这两个EDB是逗号链接,所有heap必须满足两个条件,或者说两个EDB的heap变量必须相等.output TaintVar
首先规则中定义了入口函数、Source点。在TaintVar查询语句中,有两个EDB,这两个EDB是经过ptaint中的IDB检索过来的,所以我们跟进PTaint规则中。
因为原先的规则并没有针对SpringBoot的,所以我这里添加了一条针对SpringBoot的参数定义污点的规则:
TaintHeap(insn, heap),cipt.VarPointsTo(heap, to) :-SourceMethodArg(callee,n),AnnotationParam(callee,n,"org.springframework.web.bind.annotation.RequestParam"),FormalParam(n, callee, from),AssignLocal(_, _, from, to, callee),ActualParam(_,insn,to),heap = cat("NewArgTainted::", insn).
规则中首先查询了SouceMethodArg的callee方法,也就是我们刚才定义的
ptaint.SourceMethodArg("<org.sec.sidemo.web.XSSController: java.lang.String reflection(java.lang.String)>",0).
然后依据该callee到AnnotationParam中进行查询,查询该callee的索引为n的参数是否满足有RequestParam注解。
因为所有的参数注解都会在Param-Annotation.facts中呈现,所以我在inputDeclaration.dl规则中我添加了如下规则:
.decl AnnotationParam(method:Method, n:number, descriptor:symbol).input AnnotationParam(filename="Param-Annotation.facts")
再查询定义好的SourceMethodArg中的值

可以查询到对应的值,表示该Rule成立,继续往后看。后续带入到了FormalParam中查询对应的from值

正好对应了前面的jimple中间语言reflection的第一个参数parameter0,之后又使用了AssignLocal查询该parameter0转到了本地变量的哪一个值上。

查询的结果是<org.sec.sidemo.web.XSSController: java.lang.String reflection(java.lang.String)>/message#_0,正好对应jimple的parameter0转移。
之后通过ActualParam找到它对应的Insn的值,并用cat函数链接两个字符串传递给heap,从而得出最终的IDB。

读取最后生成的TaintVar结果集

就可以看到insn和var的值都输出到结果中,成功把污点标记到message#_0本地变量上。
既然污点源已经分析出来了,后续就要分析污点是如何传播的,且该Xss的Sink点的返回值是否包含污点标记(因为是ResponseBody注解修饰的方法,因此需要判断返回值是否有污点标记)。
污点是message参数,同时Controller中经过this.xssService.reflection(message)方法传递了污点,并把污点传递到了返回值上。
ptaint.ArgToRetTransfer("<org.sec.sidemo.service.XSSService: java.lang.String reflection(java.lang.String)>", 0)..decl TransferTaint(heap:Heap, var:Var)TransferTaint(heap, var) :-ptaint.ArgToRetTransfer(callee, n),VirtualMethodInvocation(insn, _, callee, _, _),ActualParam(n, insn, arg),ptaint.cipt.VarPointsTo(heap, arg), //判断调用XSSService的实参是否是污点标记的对象AssignReturnValue(insn, var).
如上,首先定义一个参数到返回值的转移规则,之后在TransferTaint的EDB里面判断了对应的方法调用,并判断对应的实参是否有污点标记。如果有,则用AssignReturnValue找到对应的返回值由什么参数接受,并输出IDB关联起heap和新的接受值var。

关联起来之后,只需要判断对应的Sink点的返回值是否和heap污点指向的参数值var相等即可判断是否存在XSS漏洞
ptaint.SinkMethod("<org.sec.sidemo.web.XSSController: java.lang.String reflection(java.lang.String)>", 0).IsSink(TaintFlow) :-TransferTaint(heap,var),ptaint.SinkMethod(method,_),Return(_, _, var, method), //判断是否是Sink点的返回TaintFlow = cat("TaintFlow:",cat(method,cat(">>>>>",heap))).
最终输出TaintFlow结果。
类型继承关系分析(CHA)原理刨析
在Java中相关的调用图分析有大致四种分析技术:
Class hierarchy analysis(CHA)
Rapid type analysis(RTA)
Variable type analysis(VTA)
Pointer analysis(k-CFA)
而其中Class Hierarchy Analysis(CHA)就是类型继承关系分析,其目的就是通过类之间的调用关系来分析程序的走向,相比较指针分析的方式,CHA的精度更低,但耗时更短。而且后续还需要投入大量的人力成本去排除可能存在的误报情况。本章节就简单的介绍CHA的分析原理和BytecodeDL是如何对靶场进行分析定位的。
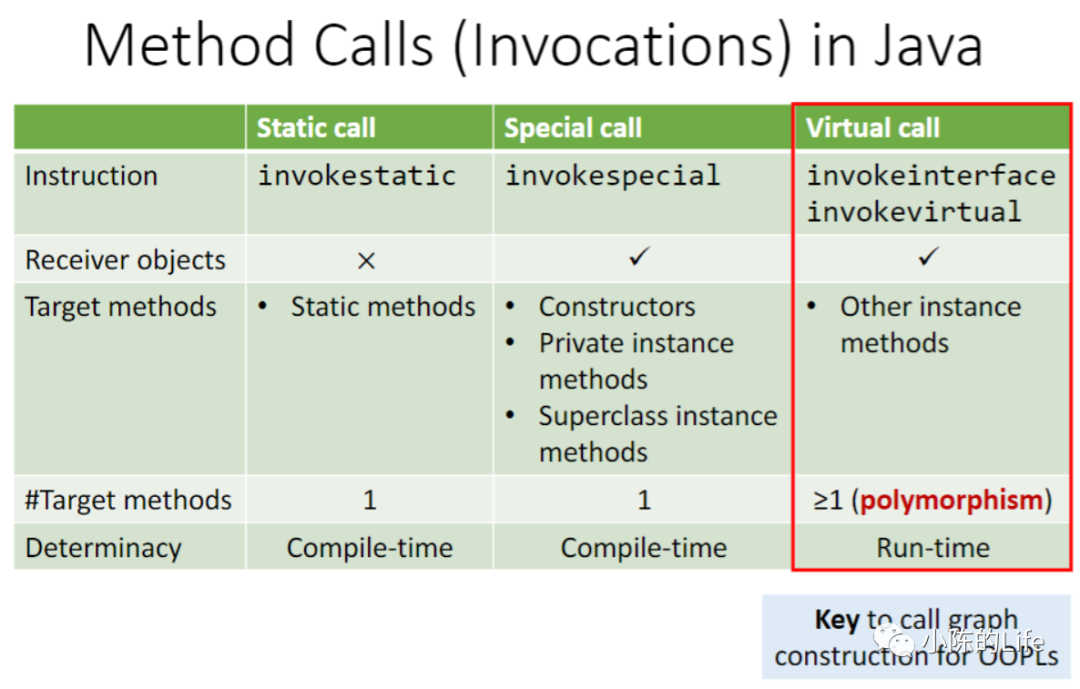
在Java中,其方法调用可以分为四种调用:
invokestatic
invokespecial
invokeinterface
invokevirtual
invokestatic和invokespecial在编译解析的时候就能确定对应的调用方法是什么,而invokeinterface和invokevirtual无法在编译解析的时候无法知道是调用的何种方法,因此就需要
就好比重写方法的时候


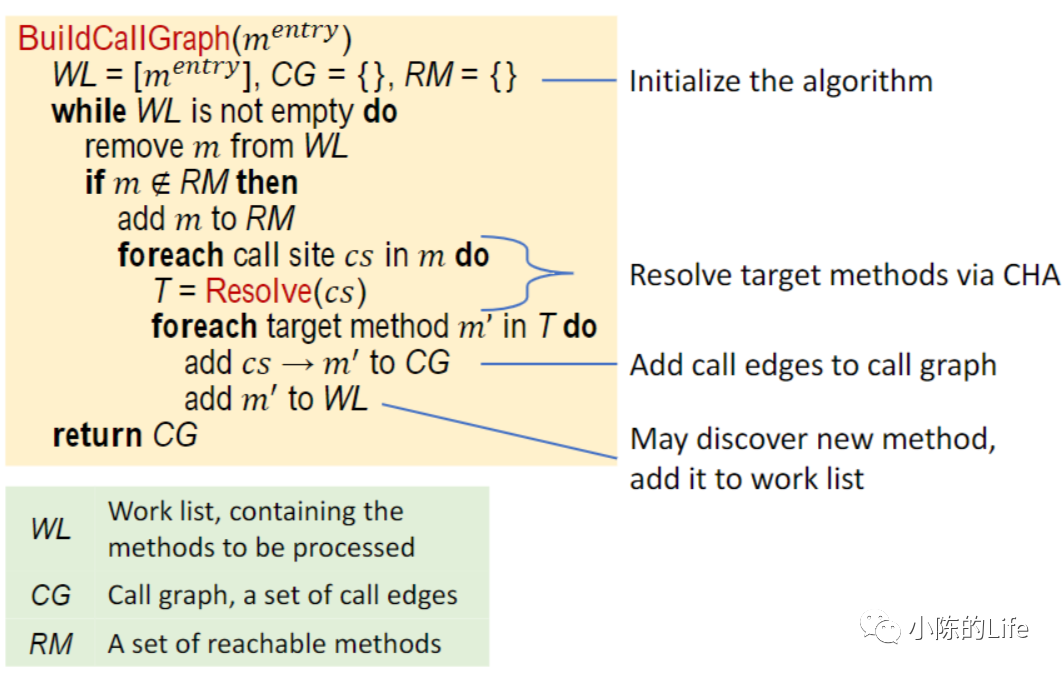
Reachable(callee, n+1),CallGraph(insn, caller, callee) :-Reachable(caller, n),n < MAXSTEP,VirtualMethodInvocation(insn, _, method, receiver, caller),MethodInfo(method, simplename, _, _, _, descriptor, _),VarType(receiver, class),SubEqClass(subeqclass, class),!ClassModifier("abstract", subeqclass),Dispatch(simplename, descriptor, subeqclass, callee).
#define MAXSTEP 5#define CHAO 2#include "inputDeclaration.dl"#include "utils.dl"#include "cha.dl"SinkDesc("getInputStream", "java.net.HttpURLConnection").EntryMethod(method),Reachable(method, 0) :-MethodInfo(method, simplename, _, class, _, _, arity),MethodModifier("public", method),simplename = "ssrf1",class = "org.sec.sidemo.web.SSRFController",descriptor = "(Ljava/lang/String;)Ljava/lang/String;"..output SinkMethod
neo4j-admin import --relationships=Call=/bytecodedl/neo4j/CallEdgeHeader.csv,/bytecodedl/output/CallEdge.csv --nodes=/bytecodedl/neo4j/CallNodeHeader.csv,/bytecodedl/output/CallNode.csv --nodes=/bytecodedl/neo4j/SinkMethodHeader.csv,/bytecodedl/output/SinkMethod.csv --database=$dbname --delimiter="\t" --skip-duplicate-nodes=true
MATCH n = (e:entry)-[*]->(s:sink) RETURN n
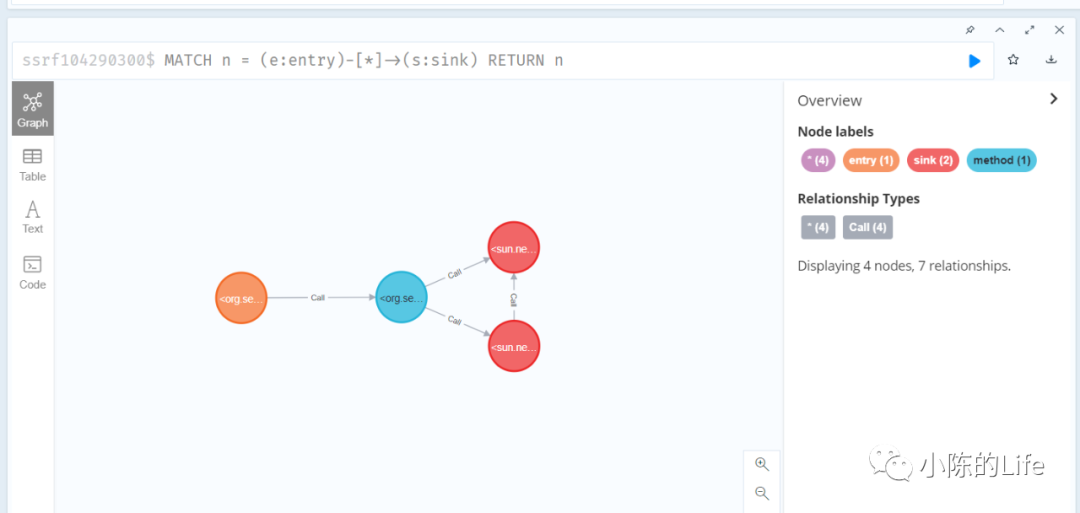
这一段时间的学习和接触发现白盒设计其实是非常聪明的,通过将程序转换成对应的facts,并用相关的datalog查询语句关联起对应的CallGraph和定义相应需要查询的规则数据库。之后通过neo4j类似的图形数据库来查询相应的漏洞。
对于ByteCodeDL来说,使用了Doop的Soot Facts生成工具,程序无法支持解析SpringBoot的程序,刚开始的时候和作者一样爬了不少的坑。看源码、改程序,但因为没有相关全面的文档,只能一点点通过自己的理解来更改相应的程序,但是觉得可以进一步发展以下功能:
更改Doop的Soot-Facts-Generate工具,增强对SpringBoot的支持。
因为目前ByteCode项目暂时只有对基础语法的支持,后续可以考虑增加定义Spring的Controller方法为入口函数,并增加相关漏洞Sink点的规则。
可以编写一个程序接口,专门添加入口函数和Sink的规则,后端再通过上传Jar包的功能自动化生成和导入图形数据库中。
ByteCodeDL暂时只有作者提供的CHA查询规则,后续是否可以根据指针分析的规则添加相应的datalog查询。
其实ByteCodeDL和主流的CodeQL白盒工具原理相似,CodeQL有对数据流分析的支持,而ByteCodeDL处于刚开源的阶段,相关分析规则还不够完善。但好处在于ByteCodeDL提供了相关导入图形数据库查询的方式,方便安全人员甚至是开发人员查询相关漏洞,同时还有完整的图形显示,利于定位相关漏洞形成。
也很荣幸能够和作者认识,在学习ByteCodeDL的时候解答了我不少问题。
[1].https://bitbucket.org/yanniss/doop/
[2].https://www.bilibili.com/video/BV1wa411k7Uv
[3].https://anemone.top/pl-%E9%9D%99%E6%80%81%E7%A8%8B%E5%BA%8F%E5%88%86%E6%9E%90%E8%AF%BE%E7%A8%8B%E7%AC%94%E8%AE%B0%EF%BC%88Datalog%EF%BC%89/
[4].https://github.com/wernsey/jatalog
[5].https://pascal-group.bitbucket.io/lectures/Datalog.pdf
[6].https://yanniss.github.io/ptaint-oopsla17-prelim.pdf
[7].https://jckling.github.io/2021/12/17/Security/%E6%8C%87%E9%92%88%E5%88%86%E6%9E%90%E5%B7%A5%E5%85%B7%20Doop%20%E4%BD%BF%E7%94%A8%E6%8C%87%E5%8D%97/
[8].https://souffle-lang.github.io/docs.html
[9].https://www.cnblogs.com/xuesu/p/14321627.html
[10].https://blog.csdn.net/WDWAGAAFGAGDADSA/article/details/122906141
[11].https://www.jianshu.com/p/5cbc5bb5c4da