




Hive 跟传统数据库的区别
传统数据库在写入数据时是强制检查对照,如果不符合模式,则拒绝加载数据。这种模式被称为是写时模式。(“写时模式”(schema on write))
而Hive则是读时模式:在查询数据时才对数据进行对照检查。(schema on read)
Hive缺点:延迟较高,暂不支持事务类操作,不适用在联机事务处理,在线事务查询。hive不支持实时数据处理,对索引的支持较弱。hive不支持行级的插入。
Hive有以下优势:
Hive的数据“读模式”,加载数据更迅速,比传统数据库“写模式” Hive的索引查询速度更快 Hive的可扩展性更好 Hive建立在集群上并利用 MapReduce进行并行计算,因此支持很大规模的数据 Hive格式很灵活,它没有定义专门的数据格式,数据格式可以由用户指定
参考链接:hive和传统数据库的区别
hive为什么不推荐使用默认Derby数据库
在安装完成Hive之后默认是以Derby数据库作为元数据库,存储Hive有那些数据库,以及每个数据库中有哪些表,但是在实际生产过程中,并不是以derby作为Hive元数据库,都是以Mysql去替换derby。
主要是基于两点原因:
1.Derby数据库不支持并发,只支持单线程操作,当有一个用户在对Hive进行操作时,其他用户则无法操作,导致整体效率性能较低。(derby 的一大缺陷在于它不允许多个客户端同时执行sql操作)
2.当在切换目录后,重新进入Hive会找不到原来已经创建的数据库和表。主要原因是比如第一次是在bin目录下进入Hive,那么在进入Hive后,会在bin目录下创建一个metaStore.db的目录,然后在此目录下会创建一个derby.log的日志文件,所有的元数据的信息都是存储在这个日志文件中。那么经过更换目录后,然后进入Hive就会存在一个问题,原有的元数据信息都是基于bin目录下创建的,所以在找数据库和表的信息时候,都是基于bin目录的,而此时就会找不到原来创建好的数据库和表。
所以会将默认的Derby数据库进行更换为Mysql。
参考链接:hive为什么不推荐使用默认Derby数据库
Hive的sort by, order by, distribute by, cluster by区别?
Hive的order by和其他语言的一样,会对查询结果执行一个全局排序。在Hive执行时会出现,对所有数据有一个reduce的过程,但这对大数据而言,这个过程非常耗时。
而Hive多增加了一个排序方式,就是在每个reduce过程执行数据排序(局部排序),这样就可以提高后面的全局排序的效率。
因此,要想对hive执行全排序,有2种方法 1、使用order by 2、使用sort by和order by混合。通过sord by对reduce后的数据进行局部排序,最后通过order by进行最后的全局排序。
sort by 的数据能保证在同一个reduce中的数据可以按指定字段排序。使用sort by可以指定执行的reduce个数(通过set mapred.reduce.tasks=n来指定),对输出的数据再执行归并排序,即可得到全部结果。
set mapred.reduce.tasks=3;
insert overwrite local directory '/Users/liuwenqiang/workspace/hive/sort' row format delimited fields
terminated by '\t'
select * from ods_temperature sort by year;
执行结果:每个reduce结果输出到文件,查看文件,可以看出每个文件的年份都是递增的。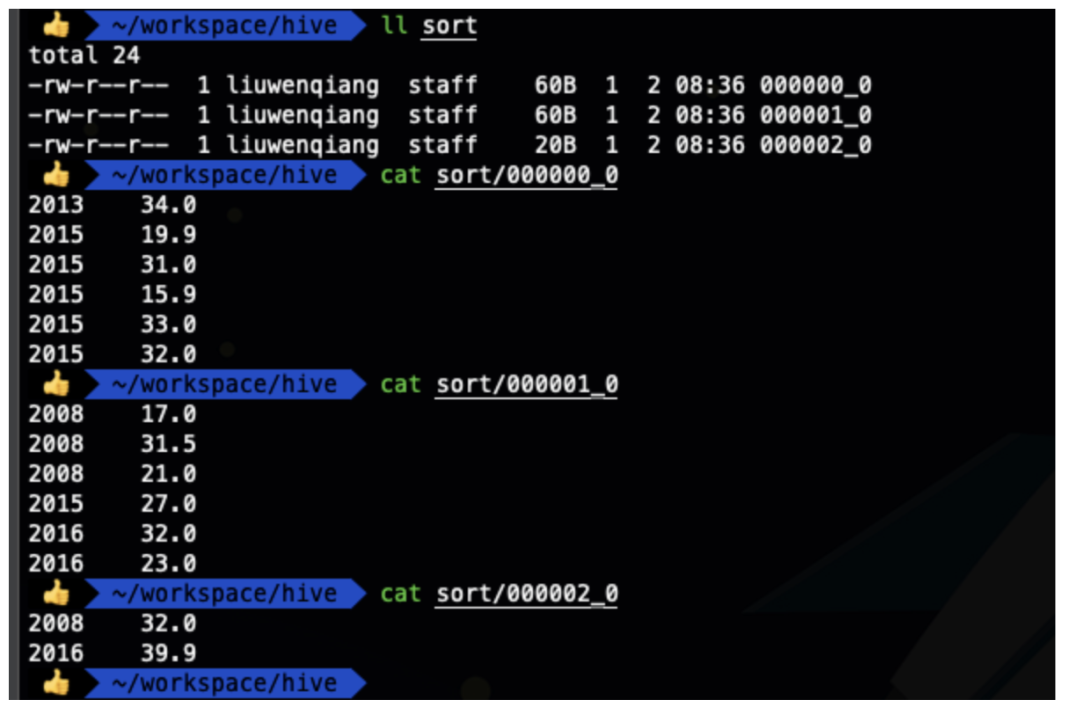
在小数据量的前提下,sort by 的处理速度比 order by慢。因为启动reduce的速度比处理数据的速度慢。
distribute by是控制在map端如何拆分数据给reduce端的。类似于MapReduce中分区partationer对数据进行分区。
hive会根据distribute by后面列,将数据分发给对应的reduce,默认方式是采用hash算法+取余数。
sort by为每个reduce产生一个排序文件,在有些情况下,你需要把某写特定的行应该分配给指定的reduce,为了进行后续的聚集操作。
distribute by刚好可以做这件事。因此,distribute by经常和sort by配合使用。
例如上面的sort by 的例子中,我们发现不同年份的数据并不在一个文件中,也就说不在同一个reducer 中,如何将相同的年份输出在同一个reduce,然后按照温度升序排序。
在没有使用distribute by,reduce输出的年份是混乱的,加上后输出的结果就是相同年份的被分配到同一个reduce中。注意:distribute by 是在sort by之前的。
cluster by :就是把distribute by 和sort by的结合起来。
当distribute by 和sort by 两者排序字段相同是,可以直接使用cluster by 来代替。例子:
select * from ods_temperature distribute by year sort by year ;
select * from ods_temperature cluster by year ;
缺点:排序只能是升序排序,不能指定排序规则为ASC或者DESC。
总结
order by 是全局排序,可能性能会比较差; sort by分区内有序,往往配合distribute by来确定该分区都有那些数据; distribute by 确定了数据分发的规则,满足相同条件的数据被分发到一个reducer; cluster by 当distribute by和sort by 字段相同时,可以使用cluster by 代替distribute by和sort by,但是cluster by默认是升序,不能指定排序方向; sort by limit 相当于每个reduce 的数据limit 之后,进行order by 然后再limit ;
参考连接:hive四种排序详解[图解4种排序
