




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
1
主机规划
默认主机系统为centos系统,使用别的系统安装的集群,升级过程中部分步骤命令可能需要更改。
注意事项:
2
升级流程
2.1 升级前注意事项
在升级开始前已拥有一个运行的kubernetes v1.17.0或更高小版本集群。 只能从一个大版本升级到下一个大版本,或者在同一个大版本下升级小版本,升级不能跳过大版本。例如:可以从1.17.4升级到1.17.20或者1.18.4,但是不能升级到1.19.x。
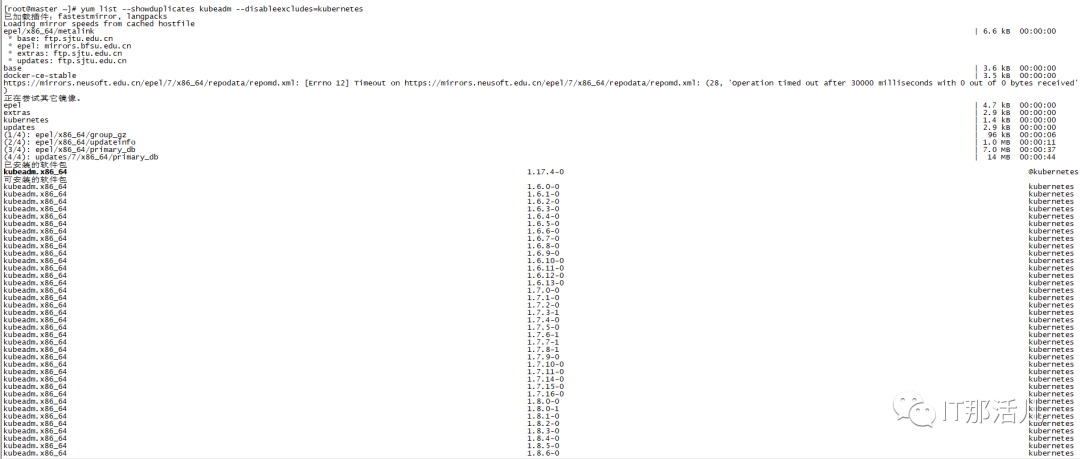
2.2 确认需要升级的版本
2.3 升级控制节点
[root@master ~]# yum install -y kubeadm-1.18.4-0 --
disableexcludes=kubernetes
Bash

[root@master ~]# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.4",
GitCommit:"c96aede7b5205121079932896c4ad89bb93260af",
GitTreeState:"clean", BuildDate:"2020-06-17T11:39:11Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"}
Bash
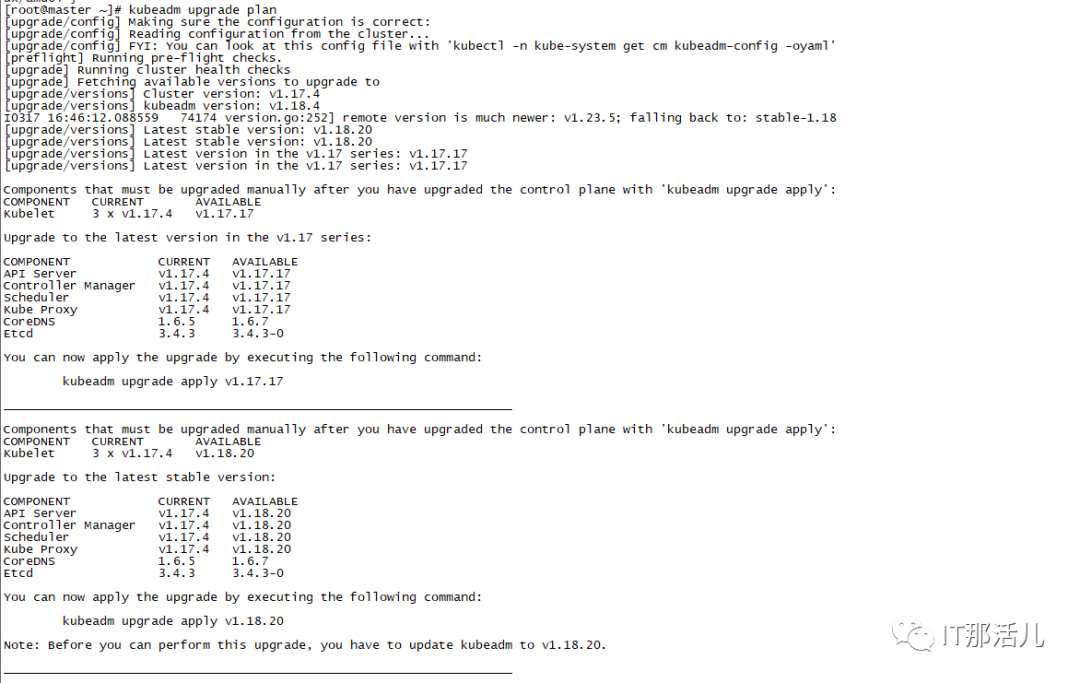
kubeadm upgrade apply v1.18.4
Bash

[root@master ~]# kubectl drain master --ignore-daemonsets
node/master cordoned
evicting pod "coredns-9d85f5447-dfq9b"
evicting pod "coredns-9d85f5447-rvckm"
pod/coredns-9d85f5447-dfq9b evicted
pod/coredns-9d85f5447-rvckm evicted
node/master evicted
Bash
[root@master ~]# yum install -y kubelet-1.18.4-0 kubectl-1.18.4-0 --disableexcludes=kubernetes
Bash

[root@master ~]# systemctl daemon-reload
[root@master ~]# systemctl restart kubelet
Bash
[root@master ~]# kubectl uncordon master
Bash
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 36d v1.18.4
node01 Ready <none> 36d v1.17.4
node02 Ready <none> 36d v1.17.4
Bash
2.4 升级工作节点
如果有多台node节点,每台执行同样操作。 drain和取消drain都是在master上操作的。
[root@master ~]# yum install -y kubeadm-1.18.4-0 --disableexcludes=kubernetes
Bash
[root@master ~]# kubectl drain node01 --ignore-daemonsets
node/node01 cordoned
error: unable to drain node "node01", aborting command...
There are pending nodes to be drained:
node01
cannot delete Pods not managed by ReplicationController, ReplicaSet, Job, DaemonSet or StatefulSet (use --force to override): default/nginx-58777cc9fd-cwj77
cannot delete Pods with local storage (use --delete-local-data to override): kube-system/metrics-server-6b976979db-8d59w
[root@master ~]# kubectl drain node01 --ignore-daemonsets --delete-local-data --force
node/node01 already cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/kube-flannel-ds-amd64-mrxm4, kube-system/kube-proxy-8tvvm; deleting Pods not managed by ReplicationController, ReplicaSet, Job, DaemonSet or StatefulSet: default/nginx-58777cc9fd-cwj77
evicting pod default/nginx-58777cc9fd-nv7s9
evicting pod default/nginx-58777cc9fd-cwj77
evicting pod default/nginx-58777cc9fd-hnd6c
evicting pod default/redis-cluster-5
evicting pod default/redis-cluster-1
evicting pod default/redis-cluster-3
evicting pod kube-system/coredns-7ff77c879f-4hstv
evicting pod kube-system/metrics-server-6b976979db-8d59w
evicting pod kubernetes-dashboard/kubernetes-metrics-scraper-6b97c6d857-c6r6k
I0318 11:17:34.515068 7386 request.go:621] Throttling request took 1.146898968s, request: GET:https://XXX.XXX.XXX.136:6443/api/v1/namespaces/kubernetes-dashboard/pods/kubernetes-metrics-scraper-6b97c6d857-c6r6k
I0318 11:17:44.701717 7386 request.go:621] Throttling request took 1.33562914s, request: GET:https://XXX.XXX.XXX.136:6443/api/v1/namespaces/default/pods/nginx-58777cc9fd-hnd6c
pod/nginx-58777cc9fd-cwj77 evicted
pod/coredns-7ff77c879f-4hstv evicted
pod/nginx-58777cc9fd-hnd6c evicted
pod/metrics-server-6b976979db-8d59w evicted
pod/redis-cluster-5 evicted
pod/nginx-58777cc9fd-nv7s9 evicted
pod/redis-cluster-3 evicted
pod/kubernetes-metrics-scraper-6b97c6d857-c6r6k evicted
pod/redis-cluster-1 evicted
node/node01 evicted
Bash
[root@master ~]# kubeadm upgrade node
Bash

[root@node01 ~]# yum install -y kubelet-1.18.4-0 kubectl-1.18.4-0 --disableexcludes=kubernetes
[root@node01 ~]# systemctl daemon-reload
[root@node01 ~]# systemctl restart kubelet
Bash
[root@master ~]# kubectl uncordon node01
node/node01 already uncordoned
# 如下可以看到node01节点已成功升级为1.18.4版本
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 37d v1.18.4
node01 Ready <none> 37d v1.18.4
node02 Ready <none> 37d v1.17.4
Bash
2.5 故障恢复
kubeadm-backup-etcd-<date>-<time> kubeadm-backup-manifests-<date>-<time>
参考文档:

本文作者:刘 欢
本文来源:IT那活儿(上海新炬王翦团队)

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
