




原文作者:肖恩·托马斯
原文地址:https://www.enterprisedb.com/blog/replication-revue
PG Phriday:复制剧
数据库复制是成功构建高可用性 Postgres 集群的基本要素。信不信由你,这不是 Postgres 社区一直拥有的东西。多年来 Postgres 复制经历了哪些阶段,为什么重要?
这不仅仅是对 Postgres 复制类型起源的探索,而是每次主要迭代中集群构建的练习。最终的目标是根据我们去过的地方来预测我们要去的地方。
一开始有WAL shipping
正如我们在介绍中暗示的那样,Postgres 并不总是能够轻松访问数据库复制。事实上,在 Postgres 9.0 之前,没有任何形式的复制。虽然在此之前基于触发器的复制确实存在,但我们将这些讨论仅限于内置功能。我们想检查 Postgres 作为一个集群本身的运行情况,而不是作为其他东西的一个组件。
那么在那些日子里,如果不通过复制,Postgres 用户如何拥有一个以上的数据库节点呢?在对后端数据文件进行更改之前,Postgres 会将对数据库的所有更改写入其预写日志 (WAL) 文件。如果发生崩溃,Postgres 崩溃恢复将应用来自 WAL 的任何未决更改。
这些 WAL 文件的一个创新用途是简单地将它们归档以供重复使用,而这正是它的工作原理。这就是我们今天仍在使用的 WAL 归档系统的原因。只需在postgresql.conf中设置这些参数,然后观看魔术:
wal_level = archive
archive_mode = on
archive_command = 'cp -n %f /path/to/archive/%f'副本系统在recovery.conf文件中需要一些额外的参数,因此它们的行为就像任何以前崩溃的 Postgres 节点一样:
restore_command = 'cp /path/to/archive/%f %p'那时,一个两节点灾难恢复集群看起来像这样:

更高级的版本可能包括传输到第 3 方存储位置、直接传输到灾难恢复 Postgres 服务器本身或其他变体。重要的部分是 Postgres 节点本身从未直接连接。两个节点都不知道另一个节点的存在,唯一的区别因素是 WAL 文件本身是如何在依赖服务器之间管理的。
这种方法的主要缺点是 WAL 文件从每个 16MB 开始,可能代表数千个正在进行和过去的事务写入。即使仅用于备份用途,正确编组这些文件也绝非易事,并且必须管理它们在多个副本之间的分布充其量是容易出错的。WAL 分发暂时停止传输文件仍然很常见,这在依赖于持续文件移动的系统中放大了数据丢失的可能性。
即使在最好的情况下,如果上游主节点发生故障,一个文件也总是会丢失,这会带来所有令人不快的相关影响。
介绍物理流复制
Postgres 9.0 带来了物理流复制(PSR)的出现。最终可以直接链接两个 Postgres 节点,以便副本直接消耗来自上游主节点的 WAL 流量。更重要的是,新引入的热备模式使得在副本上实际执行查询成为可能,这在以前是不可能的。
这仍然利用了连续崩溃恢复机制,但不是完整的 16MB WAL 段,副本可以在发生更改时应用更改。旧的 WAL 归档系统仍然有它的位置用于备份目的,但不再需要维护副本节点。除了新功能之外,还有一些读者可能熟悉的语法。
主节点需要这些设置:
wal_level = hot_standby max_wal_senders = 1
当时的备用系统在其recovery.conf文件中需要这两个值,其中恢复系统的来源变得更加明显:
standby_mode = 'on' primary_conninfo = 'host=primary-node …'
最后,为了充分利用这一点,备用系统还需要在其postgresql.conf中再添加一个:
hot_standby = 'on'
PSR 还大大简化了所有描述的高可用性堆栈,给我们留下了这种更合理的关系:
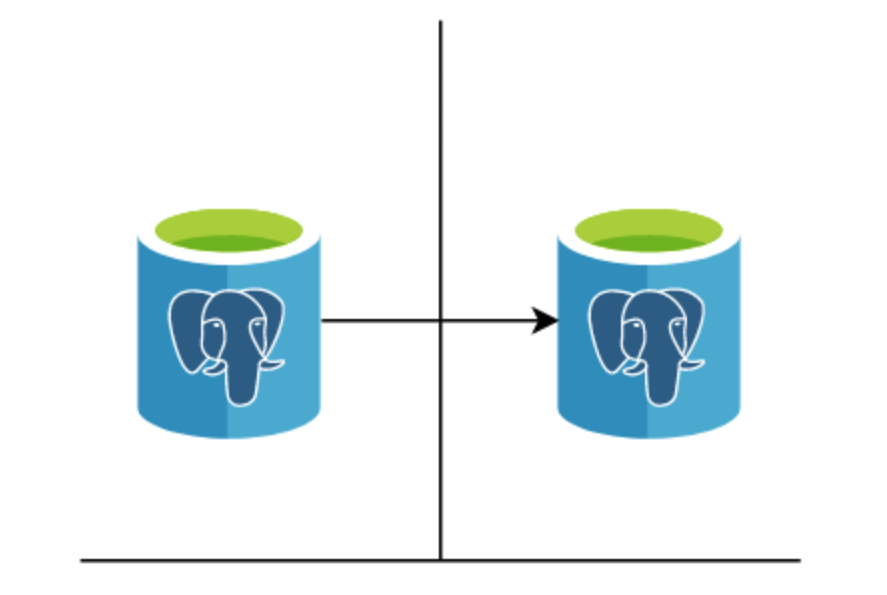
在接下来的几年中,这个特定的功能集经历了多次增强,具有许多重要的里程碑。
9.1 版
- 同步复制!这允许管理员为指定副本之间的已提交事务指定持久性保证。
- Primary 节点上的pg_stat_replication视图,反映副本系统的下游状态。以前必须使用pg_stat_activity,其中副本与其他不相关的客户端会话活动混合在一起。
9.2 版
- 级联复制,允许副本从其他副本流式传输。
9.4 版
- 复制槽(pg_replication_slots),即使在离线时也可以跟踪副本节点,并允许节点赶上停机时间。
9.6 版
- N-Safe 同步复制,因此多个副本可以充当同步备用系统。这是 Postgres 最接近于直接支持仲裁的事情。
在许多方面,9.1 是 Postgres 的第一个版本,可以松散地称为“集群”,因为副本都被跟踪,并且能够与主节点同步。后续版本让我们越来越接近真正的集群操作,最终以 9.6 结束,其中多个节点可以验证同步写入。这并不是就集群内容达成一致的投票法定人数,但这是我们目前最接近的事情。
这是节点跟踪,无论是在pg_stat_replication和pg_replication_slots中,但在集群级别上确实很有趣。为了真正拥有一个节点集群,每个节点的成员和角色都必须有一些持久的记录。让我们记住这一点,以备后用。
这完全合乎逻辑,我亲爱的华生
如前一节所述,Postgres 在 9.4 版本中引入了复制槽。这个版本也是 Postgres 添加逻辑解码的时候,这绝非巧合。逻辑解码使得在单个数据库中复制表的子集而不是整个 Postgres 实例成为可能,但它也需要更密切的跟踪。
逻辑解码并不是严格意义上的“复制”,而是将 WAL 内容提取到其数据表示等价物。如果我们在任意事务号中将“(5, 5)”元组插入名为“foo”的表中,这就是通过复制通道传输的实际信息。
这是pg_replication_slots目录表的真正原因;它允许 WAL 解码从它停止的地方继续处理。这对于流复制也很方便,这几乎是偶然的。这也只是构建可操作的逻辑复制关系所必需的整个画面的一半。
订阅节点必须跟踪它已经处理了来自特定源服务器的特定事务,并且必须针对它使用的每个上游通道执行此操作。Postgres 9.5 通过pg_replication_origin和pg_replication_origin_status目录表带来了这种精确的功能。但请注意,Postgres 直到版本 10 才具有本地逻辑复制支持。我们可以看到它在 9.5 之前的发展方向,但它需要更多的发布迭代才能达到预期的结果。
无论如何,上游和下游跟踪的组合最终看起来像这样:

WAL 解码器和逻辑应用工作者都在本地目录表中跟踪他们的进度,允许每个节点跟踪另一个节点的长期存在和状态。在某种程度上,无论如何。提供者只真正知道复制槽是否正在被消耗,而订阅者只知道他们已经从具有特定名称的源应用了一定数量的数据。
尽管如此,正是这种增强的跟踪框架使它与关于高可用性的讨论相关。逻辑复制让我们走到了这一步,但还有可能走得更远。
把它放在一起
那么,我们该何去何从?在许多方面,似乎所有必要的部分都在那里,或者足够接近后续步骤自然出现。当前版本的 Postgres 中当前物理和逻辑跟踪结构的主要缺点是没有凝聚力的整体。
如果我们检查pg_stat_replication,我们只能立即看到当前从该节点流式传输的副本。我们可以进一步跟踪以前连接的节点,前提是它们使用了复制槽,但只有它们最后一个已知的 WAL 解码和应用位置,并且没有服务器名称或别名,甚至没有订阅者的application_name字段。
即使在 Postgres 10 官方添加了本地逻辑复制之后,发布者节点也不会跟踪订阅者。只有订阅者节点知道他们通过pg_subscription目录订阅了哪些发布者。要了解集群的内聚状态,我们必须从每个节点获取此信息,并根据每个关系的每个方向上的节点和连接状态将其拼接在一起,利用大量松散耦合的系统目录。
只有这样才能知道复制槽 A 属于服务器 B,服务器 B 目前因维护而断开连接,但很快就会恢复。事实上,这是查看级联关系的唯一方法。很明显,Postgres 复制作为崩溃恢复机制的起源仍然占主导地位。表示、反映或操作完整的 Postgres 集群需要非常复杂的工具,因此用户很少尝试。
我们下一步需要做什么?
- 某种中央注册表,每个节点都在其中记录自己。
- 所有订阅关系的目录,包括复制类型。
- 上述的连通性、状态、位置和相关元数据。
这将允许任何节点查看它有多少订阅者,它正在消耗多少来源,是否有任何节点可能依赖于它的数据,等等。这也将大大简化监控,因为可以通过在单个节点上而不是集群中的每个节点上的一个或两个查询来生成有向图和相关的滞后热图。最终,一个扩展甚至 Postgres 本身可以公开库或 API 以“一目了然”地查看集群。
从查看集群到操作集群只需很短的时间。要使高可用性系统正常运行,它必须始终了解整个节点群的完整状态。当涉及包括部分逻辑订阅在内的微妙关系时尤其如此。请记住,Postgres 仍然无法通过故障转移事件来维护复制槽,因此 HA 系统必须改为这样做。有时这意味着如果下游消费者不是Postgres 节点,则手动重新创建插槽并将它们推进到正确的位置。逻辑插槽毕竟是用于 WAL 解码的,因此可能涉及 wal2json 或自定义使用者。
这些跟踪结构也有助于双向复制。事实上,这是EDB 的双向 Postgres 扩展BDR维护双向复制的方式之一。在这样的集群中,必须了解集群中每个节点关系的全貌,包括下游状态。除了简单的节点意图和类型之外,它还确定哪些节点是可恢复的,应该删除哪些节点以保持其余节点的健康,以及全局和粒度级别的内聚集群健康等等。
这可能需要也可能不需要共识模型来安全地在集群中传播这样的聚合目录,但缺少的部分是 Postgres 需要集群感知。在那之前,Postgres 在这一点上提供了所有必要的工具;剩下的就是将它们结合起来。不幸的是,现在,这留给读者作为练习。
 在过去的 20 年里,Shaun 担任过各种角色,包括 DBA、数据库架构师、开发人员、顾问、会议发言人、作者等等。这些天来,他将精力集中在 Postgres 高可用性上,因为他的大部分会议演讲、网络研讨会和用户组演示......
在过去的 20 年里,Shaun 担任过各种角色,包括 DBA、数据库架构师、开发人员、顾问、会议发言人、作者等等。这些天来,他将精力集中在 Postgres 高可用性上,因为他的大部分会议演讲、网络研讨会和用户组演示......
