排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
故障定位需要什么样的能力
故障定位需要什么样的能力
白鳝的洞穴
2022-06-13
860
运维自动化系统中最难做的部分就是故障定位,目前大多数做智能化运维的企业都使用异常检测算法来定位故障。实际上异常检测算法能够发现异常现象,很难真正的实现对故障的定位。纯数学的算法往往只能发现某些数据是异常的,而这个“异常发现”也是要依靠参数的,比如我们设定95%的数据是正常的,5%是异常的。而实际上故障发生不会像数学那样精准,同一类故障在故障持续的时间内的数据特征都会有所不同,而同一类故障在两次发生时,其在数据上的差异也可能很大。
虽然对于智能系统来说,做故障定位目前还只是处于探索阶段,不过运维人员做故障定位是拥有丰富的传统的了。我这些年参加的各类运维项目有数千个了,我自己总结了一下,人类进行故障分析时的一些分析过程,这些过程如果要使用算法来实现,也大多数是可行的。
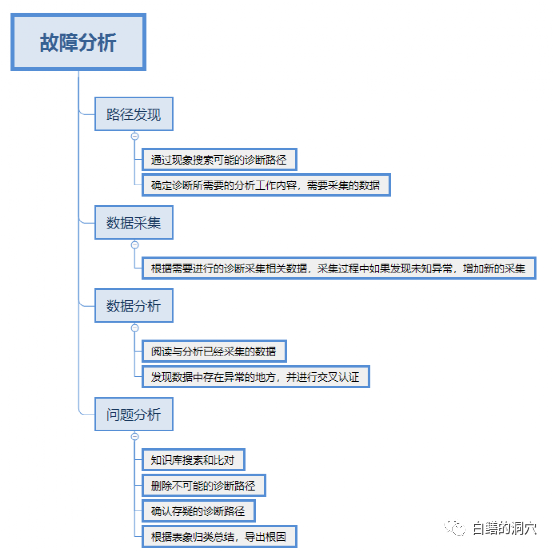
根据故障的表象判断可能的诊断路径是一个运维专家所必须具备的能力,这些能力往往是通过大量的运维案例不断的积累下来的。这也是专家有别于普通运维人员的地方。初级的专家往往能够对已知的故障有敏锐的发现能力,可以根据自己遇到过的故障现象快速找到问题的根因。更为资深的专家能够从一些普适性的故障现象中通过系统的内在原理猜测出某个现象背后可能的原因,因此这些资深专家能够更快速的发现未知故障可能的原因。计算机系统是按照某种需要而经过精密设计的系统,不是混沌系统,因此如果完全依靠数学算法去做异常检测来发现问题,实际上是不够科学的。某个现象关联的因素,每个指标意味着的现象,每个等待事件产生的因素,实际上并不是混沌和无序的,是有一定的关系的,如果我们能够把这些因素都找出来,或者能够根据当前的一些特殊系统特征发现出来,那么对于后续的问题定位十分有益。
这部分工作如果需要用自动化系统来做,那么构建这些关系的运维知识图谱是十分有效的。如果能够把专家脑子里的经验、以往经历过的运维案例都做出完善的梳理与分析,那么就可以构建起足以支撑今后运维分析的运维知识图谱了。十分可惜的是,一方面我们的专家没有梳理运维知识图谱的经验,一方面某个单一企业保留下来的足以构建运维知识图谱的案例数据过少,因此对于一个单一的企业来说,要构建这个运维知识图谱,确实困难不小。
准确的数据采集实际上也是需要依靠运维知识的,如果你无法理解某个指标的含义,那么有可能你会连数据采集都做不好。可能有些朋友不大服气,不就是一个数据采集吗,这有什么难的。如果我们要做故障分析,其中需要使用到CPU资源的使用情况,我们该如何采集数据呢?找某段时间里CPU的使用率的最高值还是平均值?如果出现CPU使用率100%就一定有问题吗?实际上并不是这么简单的,CPU突然出现的尖峰实际上大多数是无害的,不一定会对我们的系统产生不利的影响。只有长期CPU使用率都处于极高位,此时CPU才有可能存在资源不足的瓶颈,影响系统的性能。此时我们还需要观察LOAD这个指标,只有存在长期的LOAD远大于CPU线程数的时候,CPU的瓶颈才特别严重。而实际上,我们系统出现故障的时候,往往CPU使用率并不一定高,那么我们怎么判断CPU是否和故障有关呢?这就需要用到异常检测了,在大多数情况下,我们需要发现CPU存在的异常,而不是CPU使用率过高。
数据分析是人工分析工作中最重要也是最无聊的工作,此时不仅仅需要经验和能力,认真扎实的态度往往是最为重要的。哪怕水平再高的专家,如果不能踏踏实实的分析数据,那么也可能会漏掉十分重要的数据,从而走上错误的路径。这部分工作最耗时,最无聊,也最重要。实际上也是最容易用自动化的手段来实现的,目前在数据处理方面的算法十分丰富,通过自动化分析的方法来辅助故障定位,实际上技术十分成熟,实践效果也不错。
问题分析实际上是通过异常发现、知识发现、故障收敛等方式最终将问题与根因进行对应的过程。哪怕最为资深的运维专家也不可能在脑子里保留所有的运维知识,因此根据故障表象与分析发现的数据去搜索知识库,找到可能存在的根因是定位问题中十分重要的过程之一。Oracle的Metalink是一个十分优秀的知识库,我经常通过关键字搜索找到相关的DOC,然后打开阅读,与我发现的现象进行对应,如果大部分内容都一致,则问题可能的根因就很可能找到了。再根据文档中对问题表象的更为详细的描述,对问题现象进行再确认,往往就能够找出最适合的根因了。这种故障定位大多数是准确的,当然也可能存在出现偏差的情况。这部分故障定位收敛的过程也需要有知识做支撑,如果我们要做成自动化系统,那么这部分的知识也需要通过知识图谱来进行归纳和描述。这部分工作比工作开始时的知识图谱建设更为复杂,目前大多数情况下,也还仅仅能够做到辅助定位,通过自动化的手段告诉运维人员,可能的原因是什么,仅有少部分情况,可以直接确定问题的根因。
说到根因,以前有个朋友和我说,你们费那个劲干嘛,99%的数据库问题都是SQL引起的,搞好SQL优化不就行了。这句话也有一定的道理,不跑SQL系统都是好好的,跑了SQL就有问题了,SQL一定是根因。不过实际上我们面临的运维环境十分复杂,如果系统中的SQL总是能够被认真的优化,那么运维就轻松多了,而实际上DBA与写SQL的研发人员,很多时候还是要相互体谅的,能够通过运维解决的问题,还是先通过运维来解决吧。
算法
大数据
文章转载自
白鳝的洞穴
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨