




原文地址:Progress bar for Postgres queries – let’s dive deeper
原文作者:尼古拉·萨莫赫瓦洛夫(Nikolay Samokhvalov,Postgres.ai 首席执行官兼创始人)
最近,我读了一篇由Brian Davis撰写的题为“Query Progress Bar”的精彩博文。它描述了一种观察查询执行缓慢进度的有趣方法。
在特定情况下,作者提醒:
不要在生产环境中使用它。
我同意。本文讨论的是长时间运行的查询,例如SELECT,UPDATE,DELETE以及有的进度监控作用的“invasive”方法。在 OLTP 生产环境中,在大多数情况下,我们应尝试限制此类查询的持续时间,应将其阈值设置为非常低的值,如 30 秒甚至 15 秒,然后执行语句超时。
让我们更深入地探讨查询进度监控主题,讨论各种类型的查询,如何监控其进度,同时分别考虑生产环境和非生产环境。
更新/删除/插入的进度监控#
生产:分批进行,并监控整体进度
为什么长时间运行的查询不利于OLTP生产系统(具有许多用户的 Web 和移动应用)的生产?
原因如下:
- 密集写入引起的压力。在没有最强磁盘子系统的服务器上执行的批量更改,特别是如果检查点程序未调整(首先,max_wal_size - 我们很快就会在单独的文章中讨论它),它可能会使您的系统崩溃。
- 还有两个原因与DELETE和UPDATE有关:
-
- 锁定问题导致性能下降
-
- autovacuum无法清理死元组,直到长时间运行的修改查询结束 - 这也会使您的服务器停机。
常见的解决方案是将工作分成相对较小的批次。但是选择很小的批大小(例如,几十行)是不合理的 - 因为每个事务都有其开销。
同时,如果使用过大的批次,则存在锁定和autovacuum相关问题再次出现的风险。我通常建议选择合理的批大小,这样单个查询始终花费不到1秒
为什么是 1 秒?
在"What is a slow SQL query?"一文中,我解释了用户请求处理的性能与人类的感知能力有何关系。根据我的实践,在大多数情况下,1秒被证明是批处理修改查询的合理限制 - 尽管在某些情况下,进一步降低此阈值是有意义的。在类似 OLTP 的情况下,允许持续时间值超过 1 秒从来都不是一个好主意,因为明显的性能问题的风险会增加,从而导致用户投诉。
现在,回到“progress bar”的想法。我们如何实现它,比如说,分批的DELETE?
让我们以Brian的帖子为例 - big表,稍微调整数字
drop table if exists big;
create table big (
other_val int
);
insert into big
select gs % 1000 + 1
from generate_series(1, 5000000) as gs;
create index on big (other_val);
vacuum analyze big;
在这种情况下,可以合理地考虑由1000 个批次的值定义的批次,每个批次有 50000 行。同样,对于实时生产中类似 OLTP 的工作负荷,我建议使用足够小的批处理,以使删除时间调整为 1 秒。
批量删除行:
select set_config('adm.big_last_deleted_val', null, false) as reset;
with find_scope as (
select other_val
from big
where
other_val >= 1 + coalesce(
nullif(current_setting('adm.big_last_deleted_val', true), '')
, '0'
)::int
order by other_val
limit 1
), del as (
delete from big
where other_val = (select other_val from find_scope)
returning ctid, other_val
), get_max_val as (
select max(other_val) as max_val
from big
), result as (
select
set_config(
'adm.big_last_deleted_val',
max(other_val)::text, false
) as current_val,
(select max_val from get_max_val) as max_val,
count(*) rows_deleted,
1 / count(*) as stop_when_done,
min(ctid) as min_ctid,
max(ctid) as max_ctid,
round(max(other_val)::numeric
/ (select max_val from get_max_val)::numeric, 2) as progress
from del
)
select
*,
format(
'%s%s %s%%',
repeat('▉', round(progress * 50)::int),
repeat('░', greatest(0, 50 - round(progress * 50)::int)),
round(progress * 100)
) as progress_vis
from result
\watch .5
动画演示:
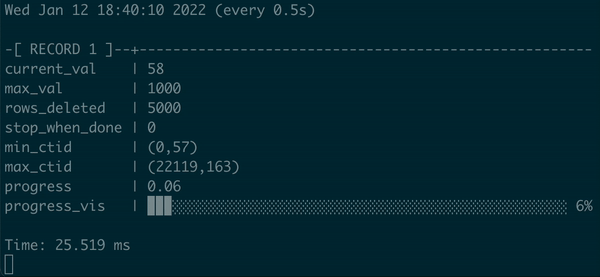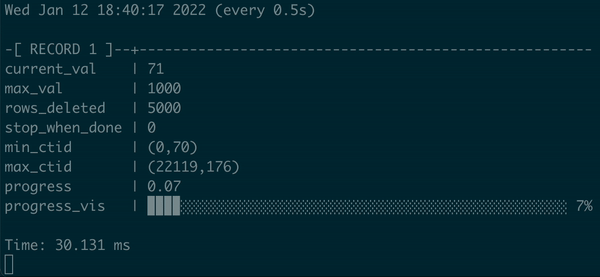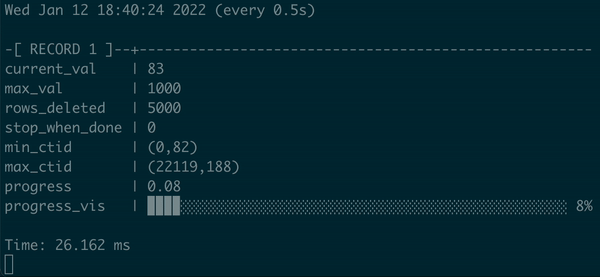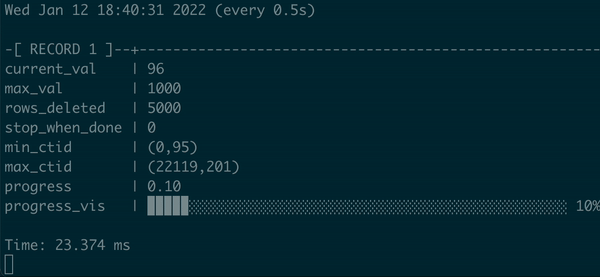
在 psql 中执行的批处理 DELETE 的动画演示,带有进度条
我们不仅在这里有一些进度条,而且我们可以用百分比和可视化来显示它,当过程结束时向用户发出信号。真正的进度条,耶!
您可能会发现在脚本编写中有用的小技巧:
-
最后,我用了\watch .5 代替了分号。这是针对psql的(Postgres默认控制台客户端,它不亚于Postgres服务器本身)。本例中的延迟值 500 ms 应根据特定情况进行选择,同时考虑服务器的功能、autovacuum调整等。
-
配置函数set_config(…)和current_setting(…),用于传递上一次迭代中的上下文。这是可选的 - 请注意,我使用了>=查找big表中other_val列中存在的最小值给find_scop,因此我们无论如何都会找到要删除的目标行。但是,如果autovacuum延迟,没有足够快地清理最近删除的行,如果没有这个技巧,我们将看到进一步迭代的性能如何随着时间的推移而降低。当Postgres开始扫描索引中指向死元组的条目时,就会发生这种情况。但是,记住上下文有助于我们的查询成为最佳查询,即使累积了许多死元组也是如此。你可以深入分析它使用EXPLAIN (ANALYZE, BUFFERS),不仅应用于第一次迭代,而且应用到第1000次迭代(并记住注意缓冲区,正如我在上一篇文章中解释的那样)。
-
表达式coalesce(nullif(current_setting(‘adm.big_last_deleted_val’, true), ‘’), ‘0’)::int看起来很重,但这是一个简短的方式,说“给我一个来自用户定义的GUC (configuration parameters in Postgres) adm.big_last_deleted_val,如果它是empty/undefined的,请使用0”。
-
返回和显示系统列ctid是一些“extra”,但我通常发现它很有用 - 当我们需要批量执行大量操作时,此信息(显示页面内的physical page ID 和偏移量)可以告诉我们已删除行的稀疏存储程度,在某些情况下,建议使用一些不同的方法来处理行。在我们的示例中,我们确实看到每个批处理中删除的行非常分散 - 但是,我们对此无能为力,因为我们在表中只有一列和单个索引,没有提供一些其他方法来处理行。
-
表达式 1 / count(*) as stop_when_done在某种程度上是一个肮脏的黑客 - 它适用于我们在psql会话中运行此类SQL的情况(可能在靠近Postgres服务的可靠服务器内部或上启动,以避免在连接问题的情况下中断)。一旦没有刚刚删除的行,我们将收到错误,并且\watch 命令将被中断。使用项目中的某种现有机制实现迭代是有意义的 - 通常涉及已在使用的现有语言,框架,库,日志记录和监视功能。
-
有关除以零的更多信息。在表达式round(max(other_val)::numeric / (select max_val from get_max_val)::numeric, 2)中,此错误是不可能的 - 当get_max_val找不到任何行时,max_val的NULL值将有效,并且除以给定的NULL。但是,如果我们使用其他方法来确定“progress”,则此处的分母值可能是 0。在这种情况下,我建议将其包装成nullif(…, 0) - 因此0将被替换为NULL,并且当不需要时,我们将避免“division by zer”。
-
最后,可视化很简单 - 它是使用format(为了更好的可读性,我更喜欢它而不是简单的串联使用 ||)和函数repeat(…)来完成的。
非生产、自我管理:pg_query_state
pg_query_state是PostgresPro的一个有趣的扩展,它允许观察操作中的执行计划。
它非常奇特,因此您不会在AWS RDS或其他主要托管的Postgres云服务上找到它。但是,如果您自己管理Postgres,您可能会发现它对非生产环境非常有用。请记住,它仍然不是一个“clean”的扩展 - 它需要修补Postgres核心。但值得考虑将其安装在“lab”环境中。
当然,pg_query_state不仅可以帮助监视“live”查询执行计划,不仅用于修改查询(UPDATEs/DELETEs/INSERTs),还可用于SELECT。EXPLAIN 可以用于任何支持的查询 - 这并不意味着DML完全受支持,而DDL则不支持。例如,EXPLAIN不能用于COPY或TRUNCATE, 但可与 CREATE TABLE … AS … or或 CREATE MATERIALIZED VIEW AS …一起使用。(至于COPY命令,Postgres 14引入了有用的pg_stat_progress_copy)。
为了演示它是如何工作的,我使用了从源代码编译(and patched)的PostgreSQL 14.1,创建了两个表,然后使用了两个psql会话,一个执行一个简单的JOIN,另一个执行执行计划:
-- 1st psql session
create table t as select id::int8 from generate_series(1, 10000000) id;
create table t2 as select id::int8 from generate_series(1, 10000000) id;
select pg_backend_pid();
select *
from t
join t2 using (id)
order by id
limit 5;
-- 2nd psql session, using the PID value from the first one
\set PID 123456
select pid, leader_pid, (select plan from pg_query_state(pid))
from pg_stat_activity
where :PID in (pid, leader_pid)
\watch .5
以下是它的外观:
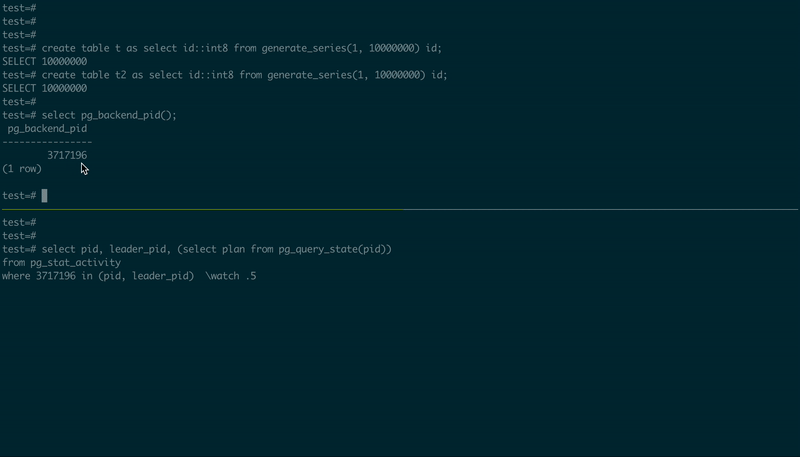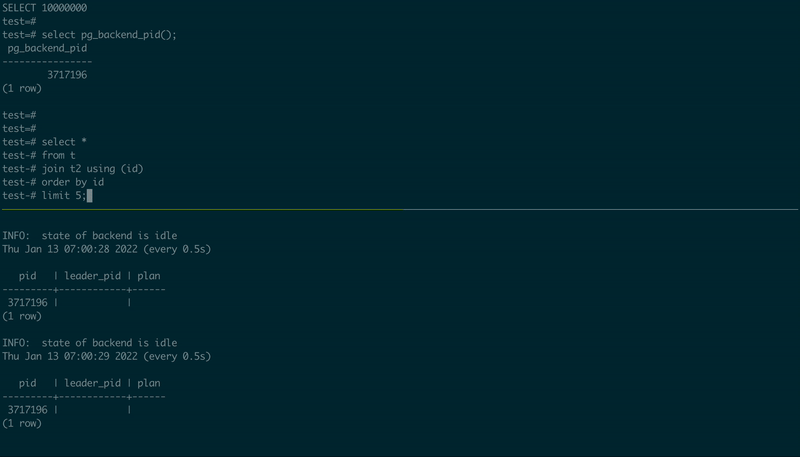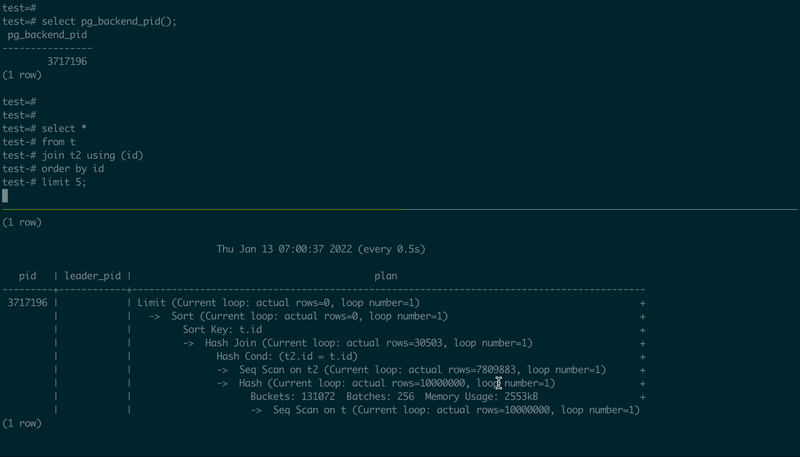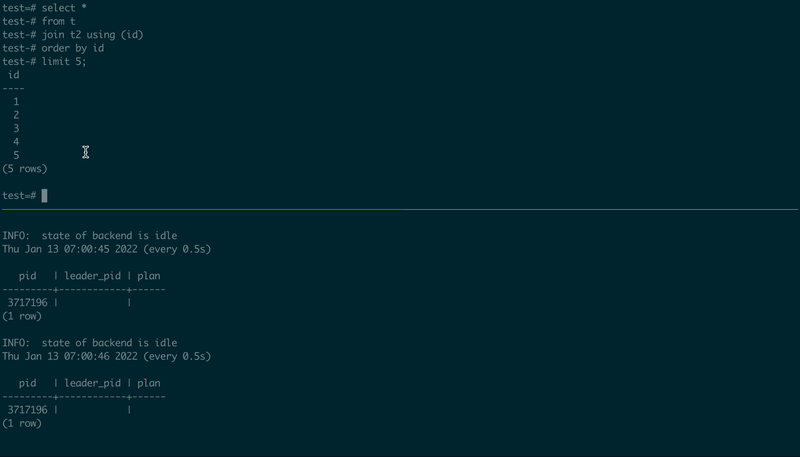
pg_stat_query演示
UPDATE (2021-01-18) 看看另一个处于早期阶段的有趣项目:pg_plan_inspector,“The Internals of PostgreSQL”的作者。它还有一个真正的进度条!
DDL 查询的进度监视
如果您的目标是在不停机的情况下更改架构,则 DDL 查询应快速且持续时间小于 1 秒。除了那些应该持续很长时间,没有引入持久的独占锁。也许后者最常见的情况是 CREATE INDEX CONCURRENTLY和 ALTER TABLE … VALIDATE CONSTRAINT(对于以前使用标志快速创建的NOT VALID约束)。
创建或重建索引的进展
For index creation and recreation, there is pg_stat_progress_create_index, implemented in Postgres 12. Some time ago, I created a useful snippet to monitor the progress of index [re]creation:
对于索引创建和重建,pg_stat_progress_create_index,在 Postgres 12 中实现了 。前段时间,我创建了一个有用的代码片段来监视索引的创建或重建的进度:
select
now(),
query_start as started_at,
now() - query_start as query_duration,
format('[%s] %s', a.pid, a.query) as pid_and_query,
index_relid::regclass as index_name,
relid::regclass as table_name,
(pg_size_pretty(pg_relation_size(relid))) as table_size,
nullif(wait_event_type, '') || ': ' || wait_event as wait_type_and_event,
phase,
format(
'%s (%s of %s)',
coalesce((round(100 * blocks_done::numeric / nullif(blocks_total, 0), 2))::text || '%', 'N/A'),
coalesce(blocks_done::text, '?'),
coalesce(blocks_total::text, '?')
) as blocks_progress,
format(
'%s (%s of %s)',
coalesce((round(100 * tuples_done::numeric / nullif(tuples_total, 0), 2))::text || '%', 'N/A'),
coalesce(tuples_done::text, '?'),
coalesce(tuples_total::text, '?')
) as tuples_progress,
current_locker_pid,
(select nullif(left(query, 150), '') || '...' from pg_stat_activity a where a.pid = current_locker_pid) as current_locker_query,
format(
'%s (%s of %s)',
coalesce((round(100 * lockers_done::numeric / nullif(lockers_total, 0), 2))::text || '%', 'N/A'),
coalesce(lockers_done::text, '?'),
coalesce(lockers_total::text, '?')
) as lockers_progress,
format(
'%s (%s of %s)',
coalesce((round(100 * partitions_done::numeric / nullif(partitions_total, 0), 2))::text || '%', 'N/A'),
coalesce(partitions_done::text, '?'),
coalesce(partitions_total::text, '?')
) as partitions_progress,
(
select
format(
'%s (%s of %s)',
coalesce((round(100 * n_dead_tup::numeric / nullif(reltuples::numeric, 0), 2))::text || '%', 'N/A'),
coalesce(n_dead_tup::text, '?'),
coalesce(reltuples::int8::text, '?')
)
from pg_stat_all_tables t, pg_class tc
where t.relid = p.relid and tc.oid = p.relid
) as table_dead_tuples
from pg_stat_progress_create_index p
left join pg_stat_activity a on a.pid = p.pid
order by p.index_relid
; -- in psql, use "\watch 5" instead of semicolon
演示 :REINDEX TABLE CONCURRENTLY
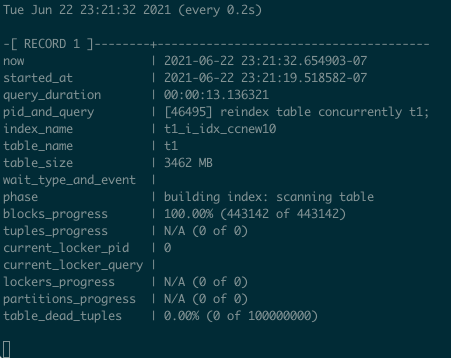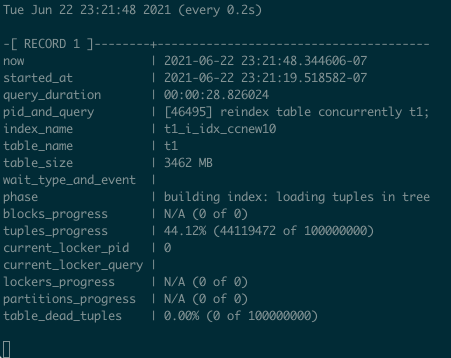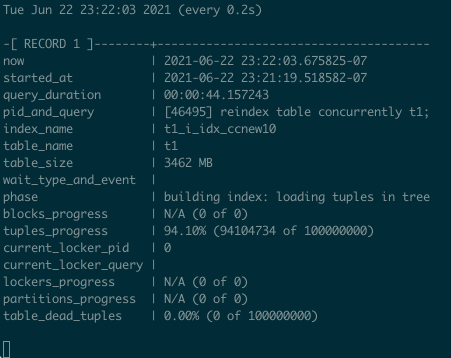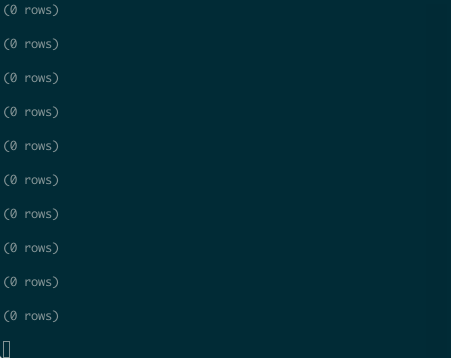
pg_stat_query演示
其他长时间运行的命令
您可以在“28.4. Progress Reporting告“ – 有有用的视图来监视 VACUUM、ANALYZE、CLUSTER.所有这些功能都很棒,可以在任何Postgres安装上使用,而无需特殊/外部的工具。
遗憾的是,没有监视约束验证进度的pg_stat_progress_***视图。一个想法是进行一些进度监控(for Linux machines):使用后端的PID(s)(使用pg_backend_pid()和/or pid,leader_pid列在 pg_stat_activity),然后观察数字以查看/proc/PID/io某些进程读取或写入了多少字节。
使用在服务器上运行的 psql 会话和 Postgres 以及 psql 的!命令来演示这个想法:
test=# select pg_backend_pid();
pg_backend_pid
----------------
135263
(1 row)
test=# \! while sleep 1; do cat /proc/135263/io | egrep ^write_bytes; done &
test=# create table huge as select id from generate_series(1, 100000000) id;
write_bytes: 2881523200
write_bytes: 3036499456
...
write_bytes: 16707886080
write_bytes: 16801512448
SELECT 100000000
test=# \! killall sleep
Terminated
test=#
test=#
test=# alter table huge add constraint c_h_1 check (id is not null) not valid;
ALTER TABLE
test=#
test=# \! while sleep 1; do cat /proc/135263/io | egrep ^read_bytes; done &
test=# alter table huge validate constraint c_h_1;
read_bytes: 3866767939
read_bytes: 4156198467
...
read_bytes: 7026241091
read_bytes: 7257476675
ALTER TABLE
test=# \! killall sleep
Terminated
test=# select
test-# pg_size_pretty(16801512448 - 2881523200) as written_during_create,
test-# pg_size_pretty(7257476675 - 3866767939) as read_during_validate;
written_during_create | read_during_validate
-----------------------+----------------------
13 GB | 3234 MB
(1 row)
当然,此方法仅适用于自我管理的 Postgres 安装,您可以在其中访问文件系统。
总结
进度监视非常有用,有助于避免错误,尤其是在高负载下处理大型数据库时。区分生产和非生产用途,以及SELECT and INSERT and UPDATE/DELETE and DDL非常重要。在本文中,我提供了一些方法,希望这些方法对我的读者有用 - 特别是那些使用multi-terabyte database 并需要在负载下处理数十亿行的读者。
