




原文地址:Using SingleStore DB for Full-Text Index and Search
原文作者:Akmal Chaudhri
这篇文章继续探讨SingleStore DB的多模型功能。在这里,讨论SingleStore DB对全文索引和搜索的支持。
摘要
继续探索SingleStore数据库的多模型功能,我们将在本文中讨论SingleStore数据库对全文索引和搜索的支持。
以SingleStore自定进度培训课程中关于全文索引和搜索的医学期刊文章为例,我们将存储期刊文章中的文本,然后使用SingleStore DB的全文搜索功能执行各种查询。
本文中使用的SQL脚本可在GitHub上找到。
介绍
在各种用例中,我们可能希望对文本执行关键字搜索。示例包括报纸文章、期刊文章、餐厅评论、住宿评论等。这些用例的要求将包括以下特性:
-
存储和搜索大量文本正文
-
根据相关性返回查询结果。频率决定相关性,例如
SingleStore DB可以通过以下方式支持这些要求: -
CHAR、VARCHAR、TEXT或LONGTEXT数据类型。
-
匹配的文档返回的相关性指数介于0和1之间。结果可以按相关性排序。
首先,我们需要在SingleStore网站上创建一个免费的云帐户。在撰写本文时,SingleStore的云帐户附带$500的积分。这对于本文中描述的案例研究来说绰绰有余。
创建数据库表
在我们的SingleStore Cloud帐户中,让我们使用SQL编辑器创建一个新数据库。命名为fulltext_db,创建语句如下:
CREATE DATABASE IF NOT EXISTS fulltext_db;
再创建表,命名为journals ,如下:
USE fulltext_db;
CREATE TABLE journals (
volume VARCHAR(1000),
name VARCHAR(1000),
journal VARCHAR(1000),
body LONGTEXT,
KEY(volume),
FULLTEXT(body)
);
每行由4列组成。期刊文章内容通过使用LONGTEXT存储在body列中。我们还使用FULLTEXT在body列上创建一个倒排索引。因为停用词经常出现,所以需忽略。SingleStore DB默认停用词列表如下:
a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, such, that, the, their, then, there, these, they, this, to, was, will, with
填充数据库表
我们将创建一个Pipeline,将日志数据加载到我们的SingleStore DB表中。在上一篇文章中,我们已将Pipeline与Kafka结合使用,将数据加载到SingleStore DB中,现在我们将对Amazon S3使用相同的技术。
CREATE PIPELINE IF NOT EXISTS journal_pipeline AS
LOAD DATA S3 'zhou-fts/*json'
CONFIG '{
"region" : "us-west-1"}'
INTO TABLE journals
FORMAT JSON
( volume <- volume,
name <- name,
journal <- journal,
body <- body
);
现在,我们将启动Pipeline,语句如下:
START PIPELINE journal_pipeline;
几分钟后,我们可以使用以下查询检查表:
SELECT COUNT(*) FROM journals;
查询结果有31000行,如图 1 所示。

图 1:计数
示例查询
现在我们已经构建了系统,可以执行一些查询。SingleStore DB支持两个主要功能,可用于全文:
- MATCH:使用此函数将会返回相关性分数介于0和1之间的结果。分数接近0表示匹配率较低,分数接近1表示匹配率较高。该文档包含其他详细信息和示例。
- HIGHLIGHT: 类似于MATCH,但返回的结果是JSON文档。JSON文档包含偏移量、唯一术语计数和少量文本。该文档包含其他详细信息和示例。
让我们看看这些函数对应的的示例。
首先,让我们查找包含optometry一词的所有期刊文章。
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('optometry');
此查询返回的结果是40行。部分结果展示如图 2。
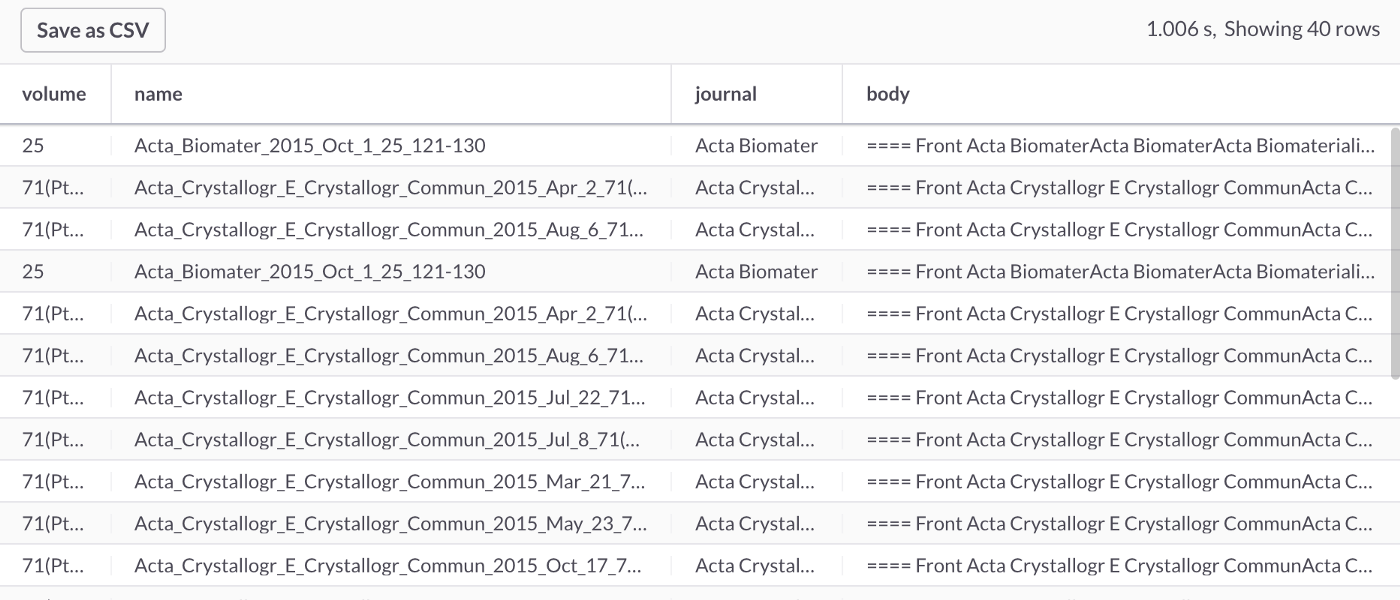
图2:Optometry
接下来,让我们在文本中的查找包含dentistry(牙科)和cavities(蛀牙)这两个词的文章,查询语句如下:
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('dentistry AND cavities');
除了使用AND,我们还可以使用&&。表示此查询的另一种方法如下:
-- Alternative query
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('+dentistry +cavities');
通过使用+运算符,我们指定这两个单词必须出现在文本中的任何位置。
此查询返回的结果有3行,如图 3 所示。

图3:Dentistry and Cavities
在以下查询中,我们将查找包含optometry一词但不包含contacts一词的任何文章,如下所示:
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('optometry -contacts');
此查询返回的结果有28行,部分如图 4 所示。
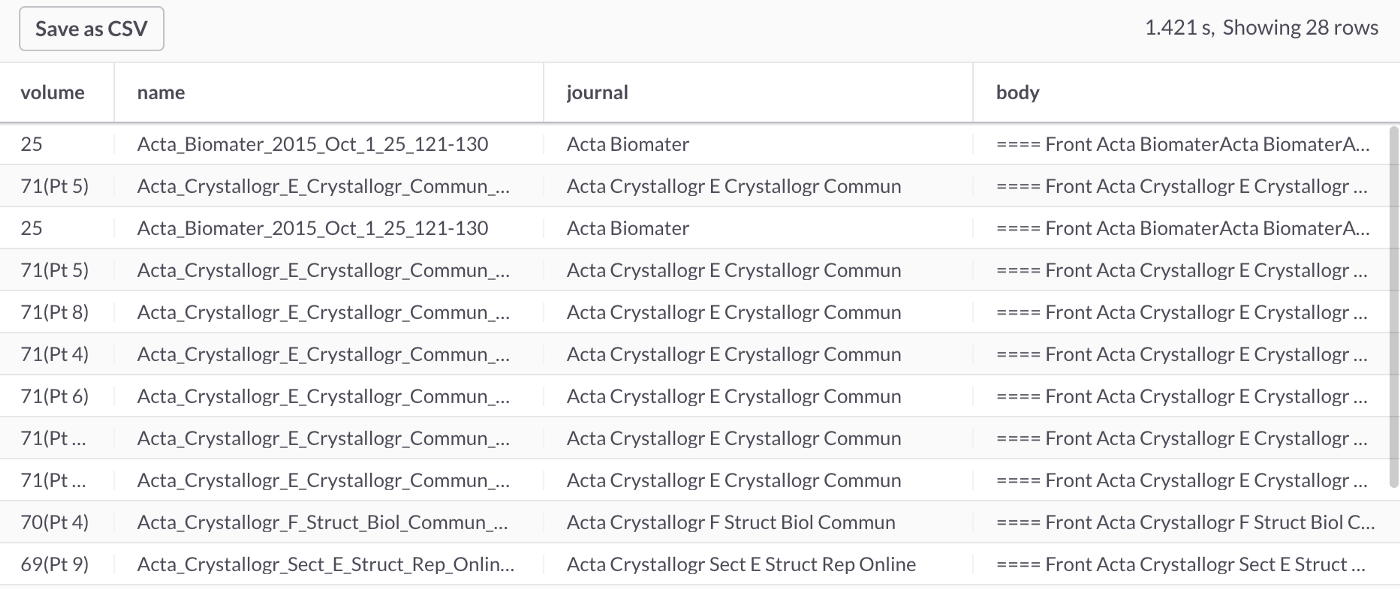
图4:Optometry - Contacts
该字符~还可用于模糊搜索。该文档包含运算符的完整列表。
通配符支持也可用于分别使用?和的单个和多个字符。在以下示例中,我们将使用该字符来匹配dentistry、cavities这两个词等。
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('dentist*');
此查询应返回91行,部分如图5所示。
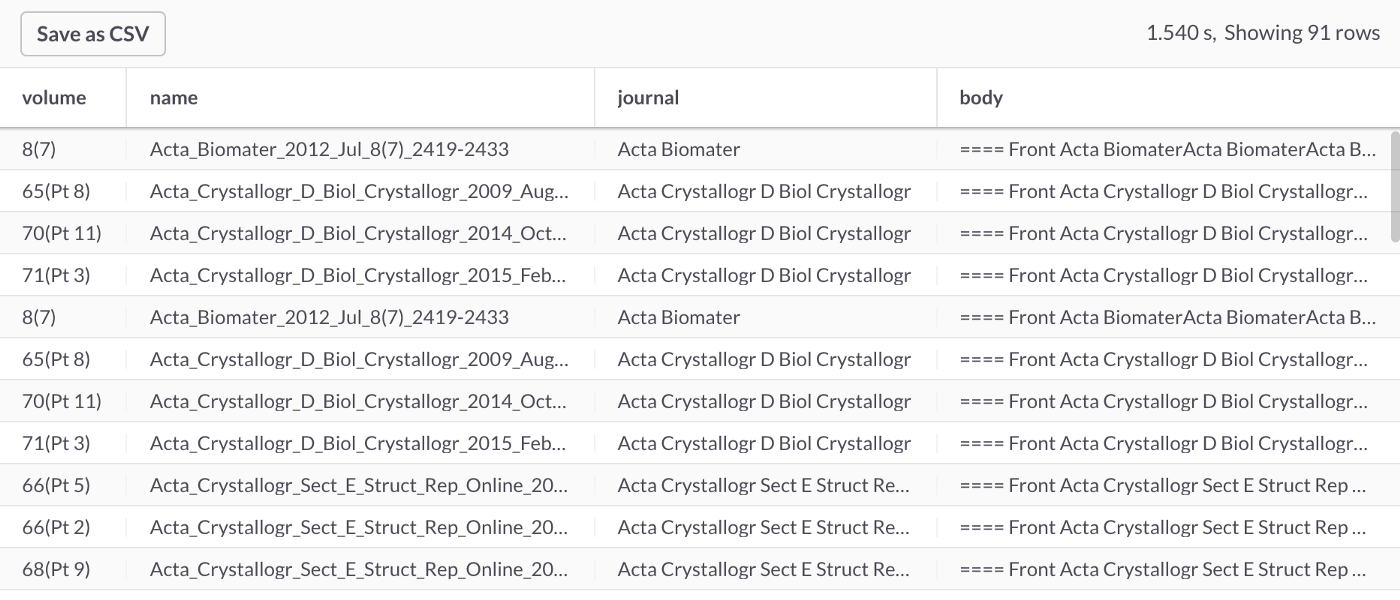
图5:Dentist*
编写的早期查询有轻微变化。让我们搜索pediatrician(儿科医生)这个词,如下所示:
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('pediatrician');
此查询应返回6行,如图 6 所示。
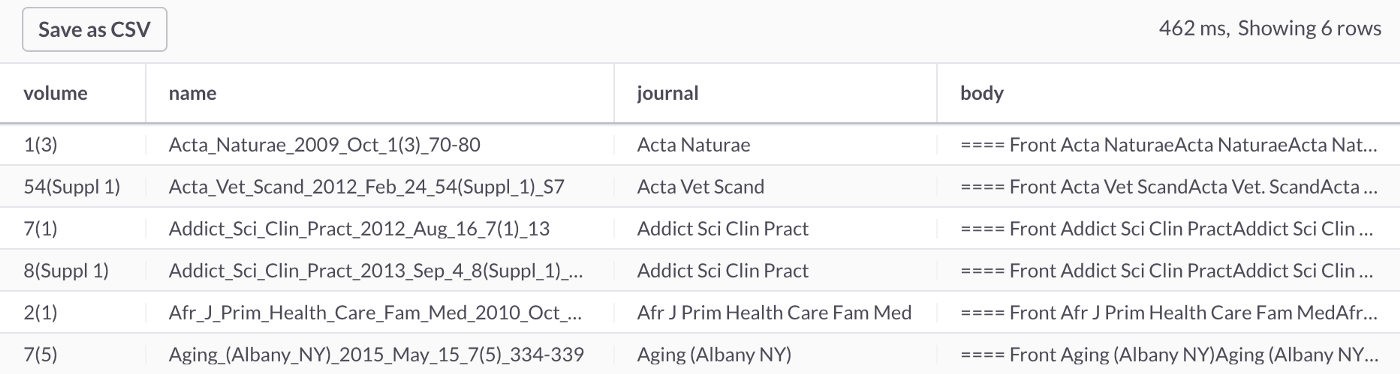
图6:pediatrician
如果我们使用主查询作为SELECT的一部分,如下:
SELECT MATCH(body) AGAINST ('pediatrician') AS score, *
FROM journals
WHERE MATCH(body) AGAINST ('pediatrician')
ORDER BY score DESC;
我们可以看到相关性分数,如图 7 所示。
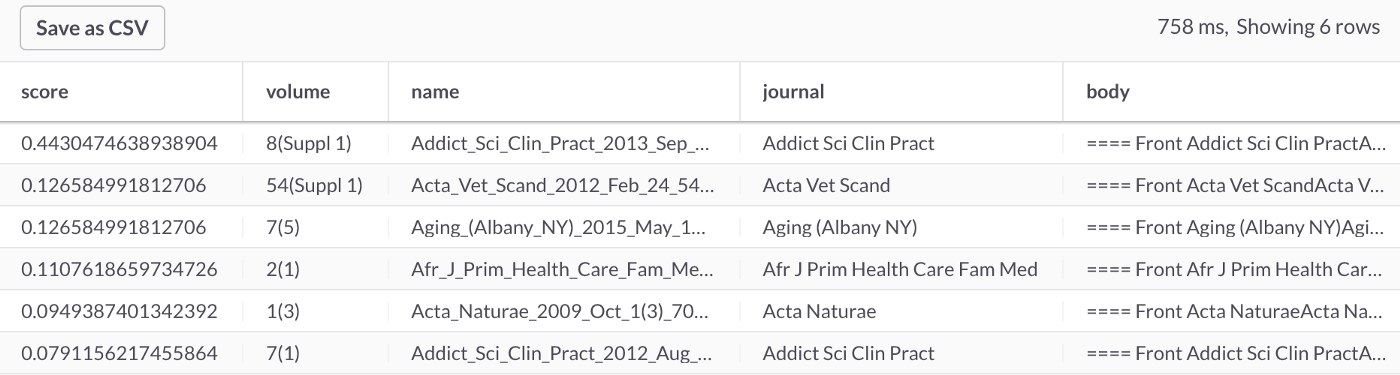
图 7:Score
最后,我们还可以使用HIGHLIGHT来返回偏移量、唯一术语计数和少量文本,如下所示:
SELECT HIGHLIGHT(body) AGAINST ('pediatrician')
FROM journals
WHERE MATCH(body) AGAINST ('pediatrician');
我们可以看到图 8 中的输出,如果仔细检查结果,我们可以看到文本片段中的pediatrician模式。

图8:HIGHLIGHT
总结
在本文中,我们了解了如何使用SingleStore DB内置的全文索引和搜索功能。SingleStore DB支持两种函数MATCH和HIGHLIGHT、一系列运算符以及单字符和多字符通配符搜索。
文中相关链接:
