





IPO
Focus


intro
Databricks :未来最值得期待的数字领域超级独角兽
在数据库领域,如果问当下谁最火,那Databricks一定排得上号。
一直以来,数据领域备受关注。之前,基于AmazonS3打造云端数据仓库的Snowflake于2020年上市,一举成就了史上规模最大的软件IPO。而今天的主角是同赛道的Databricks。去年8月,距离10亿美元的G轮融资刚过去7个月,Databricks再次获得16亿美元H轮融资,身价摇身一变成380亿美元。
彭博等外媒认为这家重量级独角兽将于2022年上市,成为今年最值得期待的IPO之一。据悉,公司目前一直在筹备上市计划,正慢慢吸引投资者参与其首次公开募股。另外,如果从2007年开始计算,全球的数据量至今已经膨胀了近200倍,数字化被写入战略规划成了各类行业的共识。

IPO Focus
文章字数过多,请根据索引阅读 ”↓
01. 自我定位与SaaS业务模式
02. 独特的盈利模式 ☆
03. 从0到1:一群加州嬉皮士RD
04. 再到380亿:强劲成长力
05. 老对手:Snowflake ☆
06. 疫情带来新机遇
07. 何时上市?
+

1
自我定位与SaaS业务模式
IPO Focus
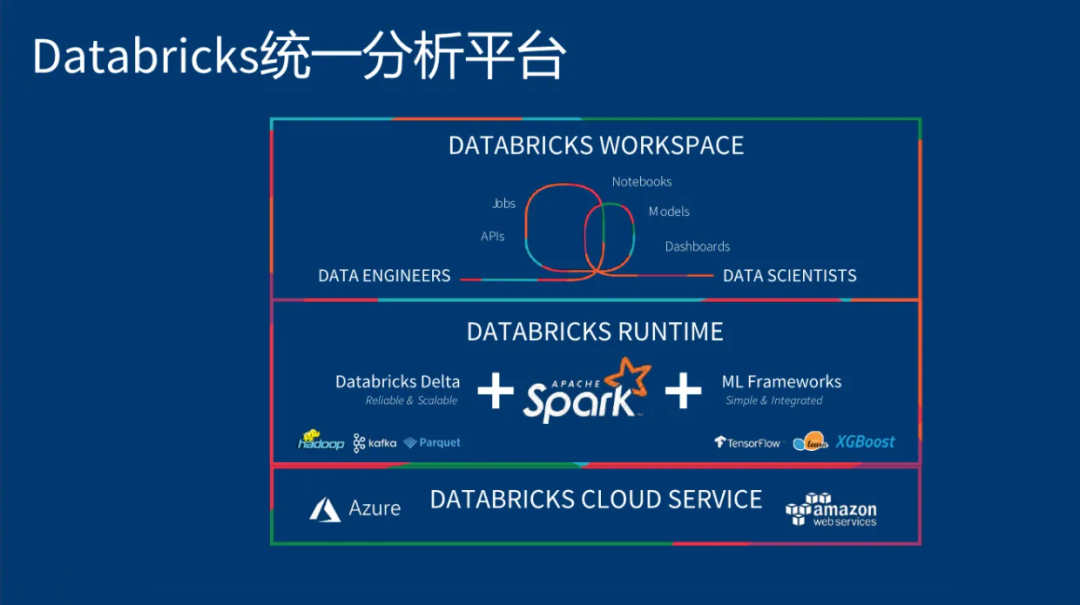
大数据独角兽Databricks于2013 年成立,总部位于旧金山。在世界各地设有办事处和数百个全球合作伙伴,包括 Microsoft、Amazon、Tableau、Informatica、Cap Gemini 和 Booz Allen Hamilton,其使命是简化数据和 AI 并使之民主化,帮助数据团队解决世界上最棘手的问题。
Databricks作为世界上第一个也是唯一一个云中的 Lakehouse 平台,结合了最好的数据仓库和数据湖,为数据和 AI 提供了一个开放和统一的平台。由美国伯克利大学AMP实验室的开源处理引擎系统Apache Spark的多位创始人联合创立。
公司旗下产品Spark为业界所熟知,除此之外公司还有不少产品,如开发和维护 AI 生命周期管理平台 MLflow、数据分析工具 Koalas 和 Delta Lake。
其中,Delta Lake 为Apache Spark 和其他大数据引擎提供可伸缩的 ACID 事务,让用户可以基于 HDFS 和云存储构建可靠的数据湖(Data Lakes数据湖是一种数据存储理念)。
目前,Databricks已经与亚马逊、Google、微软以及阿里巴巴等全球领先的公共云服务提供商建立了合作关系,且全球有超过40%的财富500强企业都在使用Databricks的云平台,如今,全球 7,000 多家组织(包括荷兰银行、康泰纳仕、H&M 集团、再生元和壳牌)依靠 Databricks 实现大规模数据工程、协作数据科学、全生命周期机器学习和业务分析。

图为:其部分客户
简单来说,使用Databricks的方式有无数种,例如,再生元制药公司使用其ML算法检测与慢性肝脏疾病有关的DNA基因,可以开发针对这一特殊基因的靶向药物。
Comcast等公司使用Databricks驱动声控遥控器。当你对着遥控器讲话时,声音数据会进入云,Databricks便通过机器学习进行处理,如果它明白了你的指令,就会将电视换到相应频道。
而在疫情期间,医院使用Databricks实时掌握急诊室的使用情况,这样就可以将救护车上的患者转到另一家有床位的医院。
金融服务公司会分析卫星数据,预测应投资哪一全球领域和公司。
壳牌公司使用Databricks监控2亿个阀门的传感器数据,预测是否有任何阀门会断裂,这样就可以提前更换,维持系统的运行、节约成本并确保员工安全。
图源:官网
值得注意的是与典型的开源商业模式有所不同,Databricks的业务模式采取云端托管的SaaS服务。Ghodsi认为除软件产品本身外,这种业务模式也对公司的发展形成了关键的优势。
开源模式下,软件免费,而厂商收取支持和服务费用。在预置(on-prem)软件世界中具有可行性,但在云计算领域中或许将遇到不同的处境。
CEO Ghodsi解释道,在这种SaaS服务的业务模式下,公司在云端托管开源项目并将它们租给用户,客户的流失率会更低,在满足客户满意度的同时,实现利润更快速的增长。
同时SaaS租赁模式也为Databricks的资产(即知识产权)提供了保护。公司最有价值的知识产权蕴藏在他用来监控和管理云端软件的工具和技术中,而不是在他所赞助的软件项目中(这些项目是公开的),因此不会像典型的开源模式那么容易被泄露。
2
独特的盈利模式
IPO Focus
Databricks不仅仅在业务上与典型的开源商业模式有所不同,盈利模式上Databricks也是借助其独特的SaaS开源模式进行。
传统的开源商业模式是软件免费,厂商收取支持和服务费用,这在on-prem里或许可行,但在云的世界就不一定了。对Databricks来说,Databricks只有SaaS,因此他们只是在后台不断更新产品。
Databricks在开发、软件运行、运营和托管方面向客户收费。采用SaaS开源的盈利模式,客户可以在本地开源平台下载免费的基础软件,同时也可以下载开源公司打造的其他付费版本。
同时,公司也将一直致力于支持完全免费的Databricks开源版本,另外,SaaS服务不同,它会有非常多企业感兴趣的特征,比如可靠性、可及性和可扩展性。
Databricks曾表示:“我们一直在做SaaS,并且只做SaaS,没有收益是来自本地版本,因此我们必须从一开始就在云交付的各个方面做到出色。”
不高估开源,也不低估市场,如上文Ghodsi说:“在云端托管开源项目并把它们租给用户,客户流失率更低,利润增长更快”。
而SaaS租赁模式下,Databricks的核心知识产权没有存放在它所赞助的开源软件项目中,而是在它用来监管云端软件的工具中,这样避免了泄露的风险。
目前,Databricks暂未上市,公开的财务数据较为有限,根据报告Databricks的年度经常性收入(ARR)达到6 亿美元,高于2020财年的4.25亿美元。此外,公司预计到2022年公司员工人数将从2300人增加到 3000多人,整体处在快速发展的进程中。
而横向比较,6亿美元,相当于同赛道Snowflake同财年12亿营业收入的一半,截至目前,后者市值超400亿美元,如果按照两倍之比来简单预估,Databricks380亿的估值也比较合理。以新估值计算,Databricks的价值是当前ARR的63倍,相较于2020年的4.25亿美元,ARR近30%的增长率让投资者对它未来的收入十分看好。
3
从0到1:一群加州嬉皮士RD
IPO Focus
企业的性格往往被它的创始人和技术背景所决定。
据了解,Databricks的基础开源代码是在加州大学伯克利分校构建的。
开始的故事是伯克利分校有一位非常出色的计算机科学教授--Dave Patterson,他向学生开放实验室和办公空间,让学生进行头脑风暴和协作。Databricks的初创团队中有计算机科学家、工程师、数学家和ML专家,从中诞生的Apache Spark,最初的版本是为了将巨量的数据集加载到内存中。

图为:创始团队
Spark为Databricks的大部分工作奠定基础。Spark项目做出一个能够更轻松处理大量数据和机器算法的引擎,并且开源了代码。相比较多数开源项目,面向的都是底层技术性强要求的infra工程师,spark面向更广泛的客户群,同时在上层加了很多的新的API,降低了技术门槛。
Databricks初创团队自2009年在伯克利时就一直致力于核心技术,而正式成立在2013年,其团队依旧深度参与到产品的创建和编程中。而Databricks的成立帮助没有优秀的开发者社区运营和推广团队Spark变现,以商业化方式推动Spark社区发展。
即便Spark是过去硅谷的顶流产品,但这并没有让AWS等巨头买账,他们选择绕过Databricks,直接将Spark集成到自己的产品里。
Databricks创始团队走了一条不被大众熟知的激进的路:云。
虽然不管对公司还是客户来说,云可以更快部署,也更容易维护,但正如联合创始人Reynold Xin所说,大部分的人知道云是未来,但绝不是现在。
当时只有小部分风投注资这家初创企业,New Enterprise Associates的投资者Pete Sonsini说:“我们在Databricks的软件收入为零时投资,认为他们会在大流行中加速发展,也许是一两个月,每个人都无法及时知道会发生什么”。和Databricks一样,他们也在赌未来。

图为:官网
2013到2015这三年,虽然有硅谷风投支持,Databricks也借力这些资金吸引人才,推出了基于云端的简化大数据处理平台Databricks Cloud,但不管是招主管、找融资还是见客户,Databricks都会被质疑:真的不支持on-prem吗?
因为背靠Spark,很多客户甚至愿意年付几千万美金让Databricks提供咨询定制化项目,但Databricks做的是一个给数据工程师的平台,这是当时大部分公司闻所未闻的玩法,也是前几年商途不顺的原因之一。
同时,另一个难题也横跨在Databricks面前:云厂商把开源软件拿来经过简单的封装,再作为服务卖出去。由于这个过程只需要简单的部署和调试,工程成本极低,定价也不高,巨头从中赚走大部分,这对Databricks来说无疑是吸血,怎样和有钱有人的云巨头对抗,是Databricks必须在技术上打造的壁垒。
他们赌的另一条路,是不做数据仓库。
因为当时数据仓库竞争过于激烈,以亚马逊为首的巨头占据大部分市场份额,而Databricks继续小众打法:避开红海厮杀,尝试切入一个新兴却可能会有爆炸性增长的小市场,针对数据科学家、数据工程师和AI的方向做产品。
开源小公司的优势在于更懂项目,迭代更快,能够聚焦、死磕产品性能,而公有云大厂很难在单一方向投入最好的工程师。随着数据量的爆发,云的生态优势逐渐被认可,加上当时市面上也没有大量竞品,这给Databricks的产品带来机会。
另外,在2019年微软投资Databricks之前,其CEO纳德拉推动“云为先”的战略,两家合作的Azure Databricks进入到微软的企业许可协议。微软直接从一个大数据竞争劣势的云产品摇身成为业界领先,形成了云巨头三足鼎立的局面,共生效应之下,客户原本买云买Office的预算自然流向Databricks。
而Databricks创始团队曾表示,持续创新就是其最大的壁垒,保持相对敏捷是促进Databricks创新的一个因素;从0到1,团队就一直牢记史蒂夫·乔布斯的一句话——你应该“在别人干掉你之前干掉自己”,而且要永远在未来科技和当前利益之间选择前者。
在最初坚持做云版本之时,市场更喜欢本地解决方案,当时,一个潜在客户甚至给Databricks2000万美元,要求打造一个Databricks软件的本地版本。
这一要求很难拒绝,但Databricks仍坚定地只做云版本,而现在,前期很多的质疑者现在都在使用Databricks的SaaS产品。
Databricks表示:勇往无前是使公司真正获得成功的唯一途径,因为如果你只是以些许不同的方式来做同一件事情,大公司便会吞并你。他们会复制你的战略并做的更好,因为他们有更多的资金和工程师。因此你必须考虑未来会发生什么,然后以此为指引创建一家公司。
或许因为团队人员都是伯克利分校的研究员,他们视自己为真理的追求着,坚信应该由数据来做决定,而不是人。
市场上有人将Databricks创始团队比作一群幸运的加州嬉皮士RD,他们信仰技术,信仰来源,信仰共享和长期主义,这些也都成为了Databricks的底色。
4
再到380亿:强劲成长力
IPO Focus
虽“大势”来的稍晚,但在这家大数据独角兽的发展历程中,一直被知名机构和投资方所看好。
2013年9月,Databricks 宣布从Andreessen Horowitz筹集1390万美元,并表示旨在提供Google MapReduce系统的替代方案。
而微软是2019年Databricks的著名投资者,参与了该公司的E轮融资,具体金额不详。
2019年后,Databricks以绝无仅有的加速度在增长。
截至2021年2月,公司已经筹集近20亿美元资金,包括由富兰克林邓普顿领投的10亿美元G轮融资,其他投资者包括亚马逊网络服务AWS、Alphabet(谷歌母公司)的一家成长型股权公司 CapitalG和Salesforce Ventures,以及微软等多家早前参与投资的投资方跟投。此时Databricks估值已经达到280亿美元,与2019年10月份完成上一轮融资时的估值62亿美元相比,飙升了近五倍。
2021年8月31日的H轮融资是最新一轮融资,由摩根士丹利的Counterpoint Global领投,Counterpoint Global还引入了其他新投资者,包括Baillie Gifford、ClearBridge Investments和加州大学的 UC Investments。此外,包括BlackRock(贝莱德)、Andreessen Horowitz、Tiger Global Management、T. Rowe Price Associates和Fidelity Investments在内的现有投资者也参与了本轮融资。
融资筹集了16亿美元,以扩大其工程团队,以保持其在市场上的领先地位。此时距离上一轮10亿美元的G轮融资才7个月时间,而估值增加的速度进一步提升,已经增加了100亿美元,飙升至380亿美元。而380亿的身价与三年前的62亿相比暴增了近13倍。
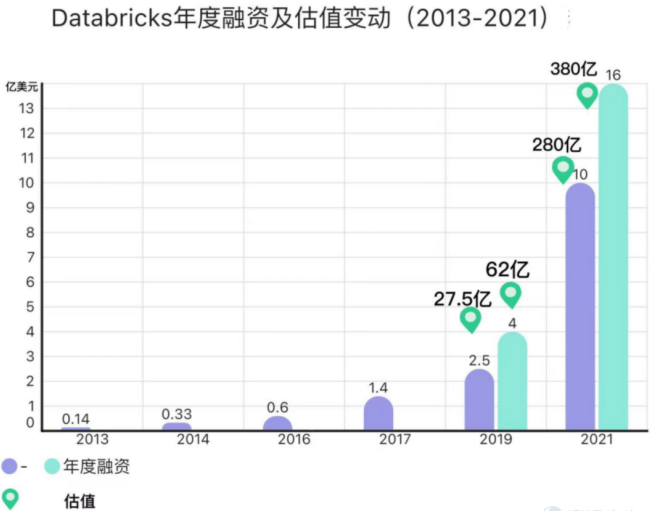
图为:Databricks年度融资及估值变动
基本面决定价值,价值决定价格,如果将Databricks的成功仅归结于对技术犀利的洞察,借助了巨人的肩膀和好运气,这还远远不够。
基于开源的创新是Databricks成长的关键,从大数据领域杀入云计算和AI,它的产品矩阵里包括DeltaLake、MLflow、Koalas以及开源分析引擎Spark等杀伤利器。
其中,超过80%的用户使用Delta Lake;MLFlow为数据科学家提供了标准化的开源框架,下载量以每月80万的速度增长,拥有比Spark更多的用户;而Koalas可以让数据科学家在笔记本电脑上使用Pandas编程,调用几个API就可以将工作部署到大型的分布式Spark集群上,把Pandas社区的数据科学创新带给了Spark用户。
帮助其他企业构建自己的AI能力,透露出了Databricks的野心:从BI到AI,构建一个企业AI平台,因为Ghodsi认为,在企业计算领域,行业还没有出现头部的企业AI平台。
5
老对手:Snowflake
IPO Focus
上文有提到,这一赛道的另外一名选手——Snowflake基于AmazonS3打造了云端的数据仓库。
目前,Databricks已经从原来的infra向更广泛场景延伸,和昔日的伙伴Snowflake同台竞技。
Snowflake于2020年上市,一举成就了史上规模最大的软件IPO。首日涨幅即超110%,市值破800亿美元,远超戴尔等IT公司,引起轩然大波。
去年6月,专注实时数据/信息处理技术的Confluent同样在纽交所挂牌上市,首日市值即超120亿美元。
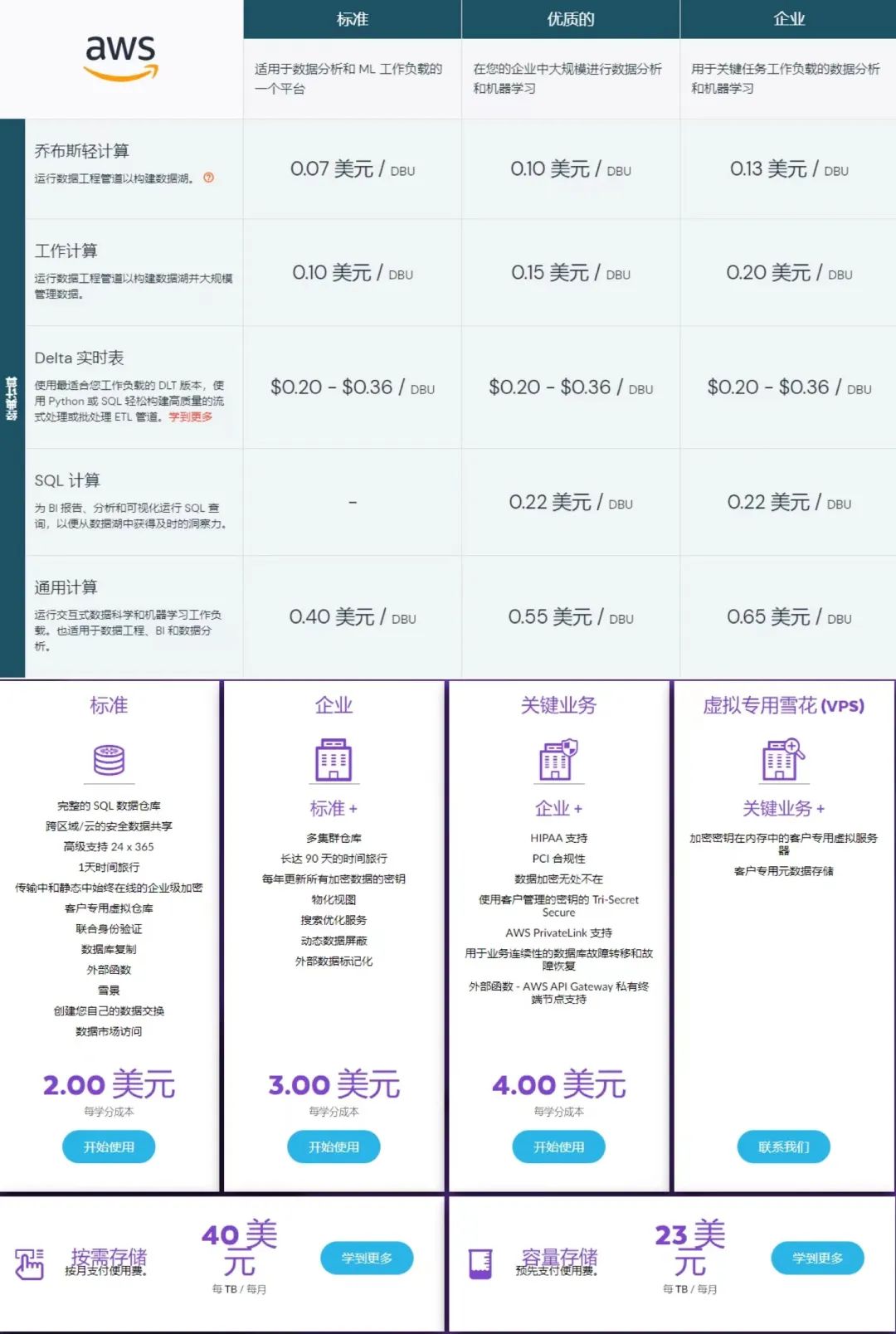
图为:两者价格表
另外,通过对比官网收费方式发现,虽然是平台租出服务器的计算资源,但这些服务器整个系统都建立在主要的云厂商的基础服务上。以Snowflake(下)为例,同样是以每秒粒度使用的计算资源付费,Snowflake是平台和云厂商打包收费方式,客户对底层服务界面(如EC2)和上游的Snowflake的成本花费要一次性付清,但比例是怎样无从得知,而打包之后Snowflake需要支付给云厂商另外成本,这在无形中增加了费用风险。
Databricks(上)的玩法是分开收费,用户的账单主要分为两部分:常规的底层云厂商服务器租用成本,以及Databricks在这些服务器上的功能费用。客户使用底层器时,费用单独付给云厂商,并不算在Databricks的营收里。
所以如果对比营收,比如2020年的Snowflake营收近6亿,但刨去付给云厂商的费用,和Databricks4亿多的营收相比,也差不了多少。而这既是Databricks毛利率比Snowflake高的原因,也是前者赚钱能力强的体现。
从类别数量上,Databricks要多于Snowflake,Databricks利用大数据和AI为广告和营销、通讯服务商、教育、能源、联邦政府、金融、医疗等13类行业提供服务。同时,全球已经有7000 多家组织(包括荷兰银行、康泰纳仕、H&M 集团、再生元和壳牌)依靠 Databricks 实现大规模数据工程、协作数据科学、全生命周期机器学习和业务分析。
值得注意的是,一般情况下,企业客户在进行数据架构时,第三方平台提供数据湖方案,在数据湖中做一些常见的数据工程;同时会有一个数据仓库,存放相当于数据湖5%-10%的结构化数据,来做BI等简单的数据分析。
但由于数据分裂在两个系统上,针对同一个客户问题分析,不同团队有不同权限,因而会看到不同版本的同一份数据,当得出不同结论后,做商业决策的团队不相信数据,进而导致底层数据平台失信,这是个很致命的问题。
将结构化和非结构化数据结合到一个地方,让客户在不移动底层数据的情况下执行数据科学和商业智能工作,是大数据发展的一个关键变化。于是,Databricks决定力推Lakehouse,能够直接在数据湖的低成本存储上,实现类似于数据仓中的数据结构和数据管理的功能,可支持BI到AI所有的工作流。
从Databricks的网页介绍上看,无论是数据工程、数据科学,还是机器学习都要依靠Lakehouse运行,加上过去使用低成本对象存储的数据湖的访问速度很慢,如今DB SQL提高了分析质量和性能,使数据湖在大数据集上的处理与数据仓库相媲美。
“Lakehouse是一个新赛道,这是一场地盘争夺战”,H轮融资之后,Ghodsi表示,这笔资金将主要用于加速Lakehouse的产品创新和市场开拓。与此同时,Databricks透露保留所有主要公共云的选择和灵活性,并将Lakehouse发展成传统数据仓库的替代品。
越来越多的企业乐于看到Databricks的实力和发展潜力,这和它本身的商业逻辑有关,业内传统企业如Teradata在营收额上虽高过Databricks好几个身位,但市值仍徘徊在40多亿美元。大剂量的资金注入后,Databricks选择并购来填补产品路线图中的空白或不足,重点是机器学习和数据初创公司,以及扩大与云公司的合作伙伴关系。
6
疫情带来新机遇
IPO Focus
大数据行业的科技新贵一直是资本市场的香饽饽,近两年的疫情更是加速了这种风潮。
疫情之下,银行支付、公共健康服务以及5G互联网等领域的大数据信息处理需求日益增加。时势创下的机遇也让全球投资者感知到了商机,大量投资者涌入这个市场,一些大数据公司也接连在美股上市,并取得了不错的成绩。
据公司CEO Ghodsi在媒体采访中表示,新冠肺炎疫情也加速了Databricks在云、开源和机器学习这三个关键领域的发展势头。
“云、开源、机器学习,这三个方面已成为每家企业战略的核心。我们真的很幸运能够处在这三大趋势的中心位置上。”Ghodsi在接受采访时说到。如果说2019年前看好Databricks的小部分风投是赌趋势,如今匆匆进场的其他机构也并没有迟到,因为在他们眼里,这家独角兽仍具备难以估量的增长能力。
另外,Databricks近两年已与多家医疗保健组织和政府机构进行合作,通过分析大量数据、预测结果助其改善运营。据Ghodsi阐释,这些公司渴望将他们的数据和数据管道流程更快地迁移到云,而Databricks也在此同时与这些原本采用传统本地供应商的传统企业的机会相距更近。
7
何时上市?
IPO Focus
针对Databricks的上市时间安排,在去年曾风靡一阵的上市传言时期,CEO也并未对媒体透露具体计划,只是曾在2021年夏天接受The Register采访时曾表示目标是当年“准备 IPO”。
而在其最新的一轮融资中,该公司联合创始人兼首席执行官Ghodsi表示,大规模注资“并不会推动首次公开募股”。他拒绝透露Databricks计划何时上市,也不愿透露它是会走传统路线,还是会采用直接上市的方式,(即公司在不发行新股或筹集新资金的情况下上市现有股票)。
Ghodsi确实排除了通过与空白支票公司或特殊目的收购公司(SPAC)合并上市的可能性,这是许多初创公司流行的上市方式。他说:“我认为SPAC更适合那些可能难以自行IPO、难以从我们所说的那种共同基金获得此类投资的公司。”他补充说,Databricks的年收入为6亿美元。他表示,这种规模的公司很少会通过SPAC上市。
同时,据市场消息,最新一轮融资之后,公司目前一直在筹备上市计划,正慢慢吸引投资者参与其首次公开募股。
而据多家的媒体的预测,延展到又一个年头的2022年,准备工作应该也陆续就位了吧,是不是可以尽情期待一下今年属于他的亮眼首秀呢?
document
Databricks官网;Snowflake财报及官网
作者信息

作者 | Isabella
联系 | Isabella-LS
Wonderful review
精彩回顾



