




对于ora.crf资源大家都很熟悉吧,其资源对应的功能是CHM资源对应的功能是ClusterHealthMonitor(以下简称CHM)是一个Oracle提供的工具,用来自动收集操作系统的资源(CPU、内存、SWAP、进程、I/O以及网络等)的使用情况。CHM会每秒收集一次数据。这些系统资源数据对于诊断集群系统的节点重启、Hang、实例驱逐(Eviction)、性能问题等是非常有帮助的。另外可以使用CHM来及早发现一些系统负载高、内存异常等问题,从而避免产生更严重的问题。ora.crf资源是11.2.0.2之后才出现的。本文要聊的OSYSMOND进程就是CHM的进程。
OK,现在优点说完了,再说说缺点。由于ora.crf服务生成的文件crf*.bdb,$HOSTNAME.ldb会很大,这样就对$GI_HOME目录的使用率造成了压力。并且其核心进程OSYSMOND在收集OS层面的信息时,经常会出现CPU消耗过大、内存使用过高甚至导致集群hang的情况。
例如:AIX:osysmond.bin High CPU Usage ( Doc ID 1397988.1 ) ,osysmond.binsocket leak causing RAC node hang and ACFS issues (Doc ID1526421.1),osysmond.binHigh Memory Consumption on Solaris 11 (Doc ID1543623.1)等等,MOS一搜太多太多类似案例,有兴趣的朋友自己去撸撸。
看到这里大家都明白了本文主角OSYSMOND进程是用于收集os层面的诊断信息,在windows平台这种没有OSWatcher的情况下有用。对于可以部署OSWatcher的平台,CHM作用有限,既然有对主机资源消耗更少的OSW,那就完全没有选择CHM的必要了,所以果断关闭CHM才是最合理的选择。
接下来聊聊笔者遇到过的两起CHM相关的问题。
一、11GR2中OSYSMOND进程CPU使用率过高(这个现象在12C和19C均有出现过)
1、问题现象
经topas发现osysmond进程CPU使用率在10%以上,正常情况在1%以下
例:
Name PID CPU% PgSp Owner PageIn 0 PAGINGSPACE
osysmond 2162770 10.3 196M root PageOut 320 Size,MB 57600
tnslsnr 31589424 4.5 48.2M grid Sios 320 % Used 1
oracle 49939238 4.3 6.46M grid % Free 99
oracle 46073098 4.1 6.41M grid NFS (calls/sec)
sh 656268 2.3 77.9M oracle SerV2 0 WPARActiv 0
oracle 48039194 1.2 7.68M grid CliV2 0 WPAR Total 0
oracle 30606586 1.2 137M oracle SerV3 0 Press:"h"-help
oracle 24970622 1.2 134M oracle CliV3 0 "q"-quit
oracle 61670090 0.8 7.67M grid
oracle 21037544 0.7 7.60M grid
oracle 12846444 0.7 7.71M grid
oracle 21824332 0.6 7.63M grid
oracle 49742446 0.6 6.62M grid
oracle 25888420 0.6 24.2M oracle
oracle 2426150 0.6 73.5M oracle
2、分析过程
1)分析OSYSMOND进程:
分为两种情形:
Case1 - high number of disks
Case2 - high number of open file descriptor
根据文档:
ClusterHealth Monitor (CHM/OS) osysmond.bin High Resource (CPU, Memory andFD etc) Usage ( Doc ID 1554116.1 )
11.2.0.3版本相关的bug在GIPSU 11.2.0.3.7中均已修复。
1、查看OSWatcher输出,以便区分下两种情形
2、查看gi和oracle用户的opatchlsinventory输出
2)综合当前情况继续分析
查看OSW的iostat发现不存在大量的磁盘问题,并且当前GI版本为11.2.0.3.9,
结合opatch补丁清单做了下排除,已知的这方面bug中匹配的只剩下这个了:
Bug16901346 : OSYSMOND PROCESS TAKING ALMOST 5% OF CPU BECAUSE OF HIGHOPEN FDS COUNT
其补丁下载中也有GIPSU 11.2.0.3.9上的fix:
https://updates.oracle.com/download/16901346.html
该bug的判断方法是:
ocludumpnode view shows: Too many open FDs (100090)on node racnode1 (> 90%of max allowed)
#cpus:16 cpu: 45.93 cpuq: 40 physmemfree: 10178944 physmemtotal: 50331648mcache: 4781768
swapfree:8242176 swaptotal: 8388608 ior: 6234 iow: 2624 ios: 353 swpin: 0swpout: 0 pgin: 0 pgout: 0
netr:12450.397 netw: 11801.061 procs: 2134 rtprocs: 1346
#fds:100036;';3:Time=07-08-13 15.44.25, Too many open FDs (100036)on noderacnode1 (> 90% of max allowed)'
#sysfdlimit:65534 #disks: 43 #nics: 4 nicErrors: 0
运行如下命令输出看下:
su- grid
$oclumondumpnodeview -allnodes -v -s "2016-08-08 00:00:00" -e"2016-08-09 12:00:00"
如果以上命令运行报错,也可通过如下命令查看
su-
#<gi_home>/bin/diagcollection.pl--collect --chmos
命令输出结果示例如下:
#/oracle/app/11.2.0/grid/bin/diagcollection.pl --collect --chmos
ProductionCopyright 2004, 2010, Oracle. All rights reserved
ClusterReady Services (CRS) diagnostic collection tool
Cannotparse master oclumon get
ClusterHealth Monitor (OS) information has not been retrieved. 《===仍然无法获取CHM数据
Rundiagcollection on master node to collect CHM/OS information
CollectingOS logs
Collectingsysconfig data
无法获取CHM原因分析:
chm可能停掉了吧或者hang了,所以无法dump出信息(可以通过crflog来查看其目前的状态<GRID_HOME>/log/<node_name>/
下的crfmond和crflogd)。
在11.2.0.3.9之上没有其他已知bug会导致这个情况,只有该BUG16901346会导致。
3、处理方法
由于chm只是收集os层面的诊断信息而已,chm收集的信息OSWatcher也会收集,故选择停掉chm。
关闭chm:
su - grid
$GRID_HOME/bin/crsctlstop res ora.crf -init
关闭chm自启动:
su -
#<GRID_HOME>/bin/crsctlmodify resource ora.crf -attr "AUTO_START=never" -init
二、CHM产生的文件过大
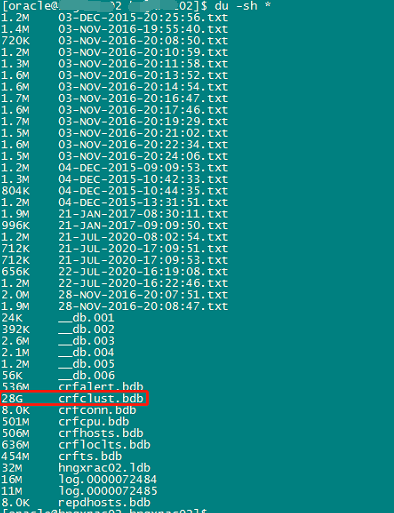
从上图我们可以看到crf*.bdb文件大小很大,处理方法与问题1一样,关闭chm并关闭其自启动,然后直接rm掉文件即可。
