




Visual C++数据库编程
ODBC基本概念
ODBC(Open Database Connectivity,开放数据库互连)是微软公司开放服务结构(WOSA,Windows Open Services Architecture)中有关数据库的一个组成部分,它建立了一组规范,并提供了一组对数据库访问的标准API(应用程序编程接口)。这些API利用SQL来完成其大部分任务。ODBC本身也提供了对SQL语言的支持,用户可以直接将SQL语句送给ODBC。
一个基于ODBC的应用程序对数据库的操作不依赖任何DBMS,不直接与DBMS打交道,所有的数据库操作由对应的DBMS的ODBC驱动程序完成。也就是说,不论是FoxPro、Access还是Oracle数据库,均可用ODBC API进行访问。由此可见,ODBC的最大优点是能以统一的方式处理所有的数据库。
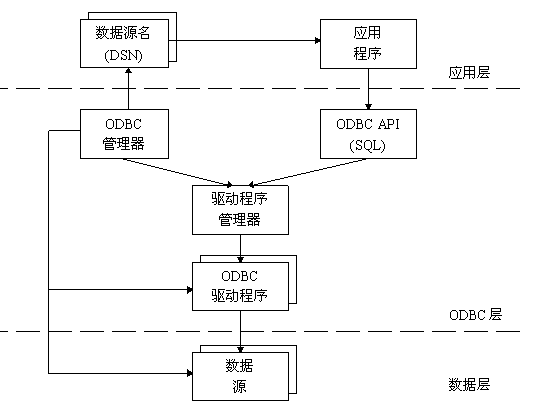
一个完整的ODBC由下列几个部件组成:
应用程序(Application)。
ODBC管理器(Administrator)。该程序位于Windows 95控制面板(Control Panel)的32位ODBC内,其主要任务是管理安装的ODBC驱动程序和管理数据源。
驱动程序管理器(Driver Manager)。驱动程序管理器包含在ODBC32.DLL中,对用户是透明的。其任务是管理ODBC驱动程序,是ODBC中最重要的部件。
ODBC API。
ODBC 驱动程序。是一些DLL,提供了ODBC和数据库之间的接口。
数据源。数据源包含了数据库位置和数据库类型等信息,实际上是一种数据连接的抽象。
各部件之间的关系如图下图所示:
应用程序要访问一个数据库,首先必须用ODBC管理器注册一个数据源,管理器根据数据源提供的数据库位置、数据库类型及ODBC驱动程序等信息,建立起ODBC与具体数据库的联系。这样,只要应用程序将数据源名提供给ODBC,ODBC就能建立起与相应数据库的连接。
在ODBC中,ODBC API不能直接访问数据库,必须通过驱动程序管理器与数据库交换信息。驱动程序管理器负责将应用程序对ODBC API的调用传递给正确的驱动程序,而驱动程序在执行完相应的操作后,将结果通过驱动程序管理器返回给应用程序。
在访问ODBC数据源时需要ODBC驱动程序的支持。用Visual C++ 5.0安装程序可以安装SQL Server、 Access、 Paradox、 dBase、 FoxPro、 Excel、 Oracle 和Microsoft Text等驱动程序.在缺省情况下,VC5.0只会安装SQL Server、 Access、 FoxPro和dBase的驱动程序.如果用户需要安装别的驱动程序,则需要重新运行VC 5.0的安装程序并选择所需的驱动程序。
ADO对象访问模型
本节简要介绍了微软的活动数据对象(ADO)模型,结合实例阐述了在Visual C++环境下使用ADO操纵数据库的基本步骤,分析ADO的特点及与开放式数据库连接(ODBC)的差异与应用前景。
关键词: 活动数据对象 数据库 Visual C++
1 ADO是微软整个COM战略体系中的一个组成部分
活动数据对象(ADO)是一组由微软提供的COM组件。 ADO建立在微软所提倡的COM体系结构之上,它的所有接口都是自动化接口,因此在C++、VisualBasic、Delphi等支持COM的开发语言中通过接口都可以访问到ADO。ADO通过使用OLE DB这一新技术实现了以相同方式可以访问关系数据库、文本文件、非关系数据库、索引服务器和活跃目录服务等的数据,扩大了应用程序中可使用的数据源范围,从而成为微软整个COM战略体系中访问数据源组件的首选,是ODBC的替代产品。
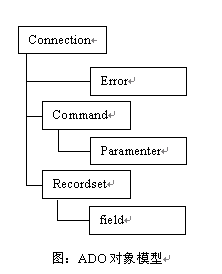
2 ADO对象模型组成
与微软的其它数据访问模型DAO和RDO相比,ADO对象模型非常精炼,仅由三个主要对象Connection、Command、Recordset和几个辅助对象组成,其相互关系如图所示。Connection对象提供OLE DB数据源和对话对象之间的关联,它通过用户名称和口令来处理用户身份的鉴别,并提供事务处理的支持;它还提供执行方法,从而简化数据源的连接和数据检索的进程。Command对象封装了数据源可以解释的命令,该命令可以是SQL命令、存储过程或底层数据源可以理解的任何内容。Record set用于表示从数据源中返回的表格数据,它封装了记录集合的导航、记录更新、记录删除和新记录的添加等方法,还提供了批量更新记录的能力。其它辅助对象则分别提供封装ADO错误、封装命令参数和封装记录集合的列。
3 ADO的特点分析
(1)由于封装了许多底层工作,使用ADO与使用ODBC几乎是一样方便。
(2) ADO不仅具有ODBC的主要功能,而且ADO适用的数据源的范围要大的多。
(3)在定义ADO记录集变量和数据库表字段绑定类时,要求记录集的字段变量、状态变量与数据库表字段的个数、顺序必须相同。这一点比在FMC中使用ODBC要复杂一些。但在数据库字段与ADO记录集字段变量绑定的宏中,ADO 提供的数据类型要远多于FMC中的RFX(如日期时间类型,在ODBC中只能转换为Cstring类型)。
(4)ADO允许同一Connection实例下有多个Record set实例。
(5)ADO允许进行批更新(使用的Update Batch方法),这样将大大减轻网络负担,提高数据库处理效率。
4 ADO在Visual C++中的使用
利用微软在Micrsoft Studio 6中提供的ADO2,可以在Visual C++中使用ADO接口操纵SQL SERVER数据库。在编译型高级语言中使用ADO,比起在一些脚本语言(如Visual Basic Scropt和JavaScript)中使用ADO要困难一些。
以下给出一个Visual C++下使用ADO的Connection对象及其Record set对象的基本步骤:
(1) 使用import指令引入ADO2组件
例:#import "C:\ADO\msado15.dll" no_namespace rename("EOF", "EndOfFile")
(2) 定义CADORecordBinding 的派生类,用于程序与数据库表字段的交互,该类的定义可参见icrsint.h。
例:
class CIntlive : public CADORecordBinding
{
public:
DBTIMESTAMP m_datetime; //定义ADO记录集字段变量(与数据库表字段相对应)
long m_key;
long m_value;
long m_quality;
WORD m_stsdatetime; //定义ADO记录集状态变量
WORD m_stskey;
WORD m_stsvalue;
WORD m_stsquality;
BEGIN_ADO_BINDING(CIntlive) //将数据库字段与ADO记录集字段变量绑定
ADO_VARIABLE_LENGTH_ENTRY2(1,adDBTimeStamp,m_datetime,sizeof(m_datetime),m_stsdatetime,true)
ADO_NUMERIC_ENTRY(2,adInteger,m_key,10,0,m_stskey,true)
ADO_NUMERIC_ENTRY(3,adInteger,m_value,10,0,m_stsvalue,true)
ADO_NUMERIC_ENTRY(4,adInteger,m_quality,10,0,m_stsquality,true)
END_ADO_BINDING()
};
(3) 调用CoInitialize初始化COM ::CoInitialize(NULL);
(4) 声明ADO的Connection对象指针和Recordset对象指针并初始化。(类型名在 msado15.dll中已定义)
例:
_ConnectionPtr pConnection1 = NULL;
_RecordsetPtr rstADO1 = NULL;
(5) 定义CADORecordBinding派生类的实例及其Bind接口指针。
例:
CIntlive m_intdata;
IADORecordBinding *rstADOBind1 = NULL;
(6) 产生Connection对象实例和Record set对象实例。
例:
pConnection1.CreateInstance(_uuidof(Connection));
rstADO1.CreateInstance(__uuidof(Recordset)) ;
(7) 连接到数据库并打开Record set对象,其中open函数的参数的使用方法可参见微软MSDN中ADO 相应对象参数的Basic描述。
例:
PConnection1->Open("driver={SQL server};server=servera;uid=sa;pwd=;database=pubs","","",NULL);
rstADO1->Open("data", _variant_t((IDispatch *)pConnection1,true),
adOpenKeyset,adLockBatchOptimistic, adCmdTable);
(8) 将CADORecordBinding派生类的实例联编到Record set对象的Bind接口。
例:
RstADOBind1->BindToRecordset(&m_intdata);
(9) 对Record set对象实例进行操作。操作方法可参见微软MSDN中ADO Record set对象相应方法的Basic描述。
例:
rstADO1->Move Next(); //移动游标到下一条记录
rstADO1->Update(_variant_t("quality"),_variant_t("3"))); //修改记录的quality字段的值为3
rstADO1->Update Batch(adAffectAll)); //将在Record set对象上的所有更新一次送入数据库
(10) 关闭Record set对象并释放Bind接口。
例:
RstADO1->Close();
RstADOBind2->Release();
(11) 关闭连接 pConnection1->Close();
(12) 调用CoUnitialize释放COM资源 ::CoUninitialize();
5 结论
作为ODBC的替代产品,ADO确实有其过人之处。由于ADO数据源几乎覆盖了目前常见的数据源类型,对于ODBC所不支持的数据源,ADO无疑是唯一的选择。而ADO的批更新功能,更是网络环境下大数据量更新应用的重要因素。由于ADO缺乏大量的第三方厂商的支持,使得ADO目前远不如ODBC普及,但其面向对象的特性将使ADO具有比较广阔的发展前景。
ODBC编程实例
Microsoft Developer Studio为大多数标准的数据库格式提供了32位ODBC驱动器。这些标准数据格式包括有:SQL Server、Access、Paradox、dBase、FoxPro、Excel、Oracle以及Microsoft Text。如果用户希望使用其他数据格式,则需要安装相应的ODBC驱动器及DBMS。
用户使用自己的DBMS数据库管理功能生成新的数据库模式后,就可以使用ODBC来登录数据源。对用户的应用程序来说,只要安装有驱动程序,就能注册很多不同的数据库。登录数据库的具体操作参见有关ODBC的联机帮助。
一、MFC提供的ODBC数据库类
Visual C++的MFC基类库定义了几个数据库类。在利用ODBC编程时,经常要使用到 CDatabase(数据库类)、CRecordSet(记录集类)和CRecordView(可视记录集类)。
CDatabase类对象提供了对数据源的连接,通过它可以对数据源进行操作。
CRecordSet类对象提供了从数据源中提取出的记录集。CRecordSet对象通常用于两种形式:动态行集(dynasets)和快照集(snapshots)。动态行集能与其他用户所做的更改保持同步,快照集则是数据的一个静态视图。每种形式在记录集被打开时都提供一组记录,所不同的是,当在一个动态行集里滚动到一条记录时,由其他用户或应用程序中的其他记录集对该记录所做的更改会相应地显示出来。
CRecordView类对象能以控件的形式显示数据库记录,这个视图是直接连到一个CRecordSet对象的表视图。
二、应用ODBC编程
应用Visual C++的AppWizard可以自动生成一个ODBC应用程序框架,步骤是:打开File菜单的New选项,选取Projects,填入工程名,选择MFC AppWizard (exe),然后按AppWizard的提示进行操作。
当AppWizard询问是否包含数据库支持时,如果想读写数据库,那么选定Database view with file support;如果想访问数据库的信息而不想写回所做的改变,那么选定Database view without file support。
选好数据库支持之后,Database Source 按钮会被激活,选中它去调用Data Options对话框。在Database Options对话框中会显示出已向ODBC注册的数据库资源,选定所要操作的数据库,如:Super_ES,单击OK后出现Select Database Tables对话框,其中列举了选中的数据库包含的全部表;选择要操作的表后,单击OK。在选定了数据库和数据表之后,就可以按照惯例继续进行AppWizard操作。
特别需要指出的是:在生成的应用程序框架View类(如:CSuper_ESView)中,包含一个指向CSuper_ESSet对象的指针m_pSet,该指针由AppWizard建立,目的是在视表单和记录集之间建立联系,使得记录集中的查询结果能够很容易地在视表单上显示出来。
要使程序与数据源建立联系,需用CDateBase::OpenEx()或CDatabase::Open()函数来进行初始化。数据库对象必须在使用它构造记录集对象之前初始化。
三、实例
1.查询记录
查询记录使用CRecordSet::Open()和CRecordSet::Requery()成员函数。在使用CRecordSet类对象之前,必须使用CRecordSet::Open()函数来获得有效的记录集。一旦已经使用过CRecordSet::Open()函数,再次查询时就可以应用CRecordSet::Requery()函数。
在调用CRecordSet::Open()函数时,如果将一个已经打开的CDatabase对象指针传给CRecordSet类对象的m_pDatabase成员变量,则使用该数据库对象建立ODBC连接;否则如果m_pDatabase为空指针,就新建一个CDatabase类对象,并使其与缺省的数据源相连,然后进行CRecordSet类对象的初始化。缺省数据源由GetDefaultConnect()函数获得。也可以提供所需要的SQL语句,并以它来调用CRecordSet::Open()函数,例如:Super_ESSet.Open(AFX_DATABASE_USE_DEFAULT,strSQL);
如果没有指定参数,程序则使用缺省的SQL语句,即对在GetDefaultSQL()函数中指定的SQL语句进行操作:
CString CSuper_ESSet::GetDefaultSQL()
{return _T(″[BsicData],[MinSize]″);}
对于GetDefaultSQL()函数返回的表名,对应的缺省操作是SELECT语句,即:
SELECT *FROM BasicData,MainSize
在查询过程中,也可以利用CRecordSet的成员变量m_strFilter和m_strSort来执行条件查询和结果排序。m_strFilter为过滤字符串,存放着SQL语句中WHERE后的条件串;m_strSort为排序字符串,存放着SQL语句中ORDER BY后的字符串。如:
Super_ESSet.m_strFilter=″TYPE=‘电动机’″;
Super_ESSet.m_strSort=″VOLTAGE″;
Super_ESSet.Requery();
对应的SQL语句为:
SELECT *FROM BasicData,MainSize
WHERE TYPE=‘电动机’
ORDER BY VOLTAGE
除了直接赋值给m_strFilter以外,还可以使用参数化。利用参数化可以更直观、更方便地完成条件查询任务。使用参数化的步骤如下:
S声明参变量:
CString p1;
float p2;
S在构造函数中初始化参变量:
p1=_T(″″);
p2=0.0f;
m_nParams=2;
S将参变量与对应列绑定:
pFX->SetFieldType(CFieldExchange::param)
RFX_Text(pFX,_T(″P1″),p1);
RFX_Single(pFX,_T(″P2″),p2);
完成以上步骤后就可以利用参变量进行条件查询:
m_pSet->m_strFilter=″TYPE=? AND VOLTAGE=?″;m_pSet->p1=″电动机″;
m_pSet->p2=60.0;
m_pSet->Requery();
参变量的值按绑定的顺序替换查询字串中的“?”通配符。
如果查询的结果是多条记录,可以用CRecordSet类的函数Move()、MoveNext()、MovePrev()、MoveFirst()和MoveLast()来移动光标。
2.增加记录
增加记录使用AddNew()函数,要求数据库必须是以允许增加的方式打开:
m_pSet->AddNew(); //在表的末尾增加新记录
m_pSet->SetFieldNull(&(m_pSet->m_type), FALSE);
m_pSet->m_type=″电动机″;
……
//输入新的字段值
m_pSet->Update();
//将新记录存入数据库
m_pSet->Requery();
//重建记录集
3.删除记录
可以直接使用Delete()函数来删除记录,并且在调用Delete()函数之后不需调用Update()函数:
m_pSet->Delete();
if (!m_pSet->IsEOF())
m_pSet->MoveNext();
else
m_pSet->MoveLast();
4.修改记录
修改记录使用Edit()函数:
m_pSet->Edit();
//修改当前记录
m_pSet->m_type=″发电机″;
//修改当前记录字段值
……
m_pSet->Update(); //将修改结果存入数据库
m_pSet->Requery();
5.撤消操作
如果用户选择了增加或者修改记录后希望放弃当前操作,可以在调用Update()函数之前调用:
CRecordSet::Move(AFX_MOVE_REFRESH)来撤消增加或修改模式,并恢复在增加或修改模式之前的当前记录。其中,参数AFX_MOVE_REFRESH的值为零。
6.数据库连接的复用
在CRecordSet类中定义了一个成员变量m_pDatabase:
CDatabase* m_pDatabase;
它是指向对象数据库类的指针。如果在CRecordSet类对象调用Open()函数之前,将一个已经打开的CDatabase类对象指针传给m_pDatabase,就能共享相同的CDatabase类对象。如:
CDatabase m_db;
CRecordSet m_set1,m_set2;
m_db.Open(_T(″Super_ES″)); //建立ODBC连接
m_set1.m_pDatabase=&m_db;
//m_set1复用m_db对象
m_set2.m_pDatabse=&m_db;
// m_set2复用m_db对象
7.SQL语句的直接执行
虽然我们可以通过CRecordSet类完成大多数的查询操作,而且在CRecordSet::Open()函数中也可以提供SQL语句,但是有时候我们还是希望进行一些其他操作,例如建立新表、删除表、建立新的字段等,这时就需要使用CDatabase类直接执行SQL语句的机制。通过调用CDatabase::ExecuteSQL()函数来完成SQL语句的直接执行:
BOOL CDB::ExecuteSQLAndReportFailure(const CString& strSQL)
{TRY
{m_pdb->ExecuteSQL(strSQL);
//直接执行SQL语句}
CATCH (CDBException,e)
{CString strMsg;
strMsg.LoadString(IDS_EXECUTE_SQL_FAILED);
strMsg+=strSQL;
return FALSE;}
END_CATCH
return TRUE;}
应当指出的是,由于不同的DBMS提供的数据操作语句不尽相同,直接执行SQL语句可能会破坏软件的DBMS无关性,因此在应用中应当慎用此类操作。
8.动态连接表
表的动态连接可以利用在调用CRecordSet::Open()函数时指定SQL语句来实现。同一个记录集对象只能访问具有相同结构的表,否则查询结果将无法与变量相对应。
void CDB::ChangeTable()
{
if (m_pSet->IsOpen()) m_pSet->Close();
switch (m_id)
{
case 0:
m_pSet->Open(AFX_DB_USE_DEFAULT_TYPE,″SELECT * FROM SLOT0″);
//连接表SLOT0
m_id=1;
break;
case 1:
m_pSet->Open(AFX_DB_USE_DEFAULT_TYPE,″SELECT * FROM SLOT1″); //连接表SLOT1
m_id=0;
break;
}
}
9.动态连接数据库
可以通过赋与CRecordSet类对象参数m_pDatabase来连接不同数据库的CDatabase对象指针,从而实现动态连接数据库。
void CDB::ChangeConnect()
{
CDatabase* pdb=m_pSet->m_pDatabase;
pdb->Close();
switch (m_id)
{
case 0:
if (!pdb->Open(_T(″Super_ES″)))
//连接数据源Super_ES
{
AfxMessageBox(″数据源Super_ES打开失败″,″请检查相应的ODBC连接″, MB_OK|MB_ICONWARNING);
exit(0);
}
m_id=1;
break;
case 1:
if (!pdb->Open(_T(″Motor″)))
//连接数据源Motor
{
AfxMessageBox(″数据源Motor打开失败″,″请检查相应的ODBC连接″, MB_OK|MB_ICONWARNING);
exit(0);
}
m_id=0;
break;
}
}
总结:
Visual C++中的ODBC类库可以帮助程序员完成绝大多数的数据库操作。利用ODBC技术使得程序员从具体的DBMS中解脱出来,从而可以减少软件开发的工作量,缩短开发周期,并提高效率和软件的可靠性。
Visual C++ ADO数据库编程入门
一、在VC++中使用ADO编程
ADO实际上就是由一组Automation对象构成的组件,因此可以象使用其它任何Automation对象一样使用ADO。ADO中最重要的对象有三个:Connection、Command和Recordset,它们分别表示连接对象、命令对象和记录集对象。如果您熟悉使用MFC中的ODBC类(CDatabase、CRecordset)编程,那么学习ADO编程就十分容易了。
使用ADO编程时可以采用以下三种方法之一:
1、使用预处理指令#import
#import "C:\Program Files\Common Files\System\ADO\msado15.dll" \ |
但要注意不能放在stdAfx.h文件的开头,而应该放在所有include指令的后面。否则在编译时会出错。
程序在编译过程中,VC++会读出msado15.dll中的类型库信息,自动产生两个该类型库的头文件和实现文件msado15.tlh和msado15.tli(在您的Debug或Release目录下)。在这两个文件里定义了ADO的所有对象和方法,以及一些枚举型的常量等。我们的程序只要直接调用这些方法就行了,与使用MFC中的COleDispatchDriver类调用Automation对象十分类似。
2、使用MFC中的CIDispatchDriver
就是通过读取msado15.dll中的类型库信息,建立一个COleDispatchDriver类的派生类,然后通过它调用ADO对象。
3、直接用COM提供的API
如使用如下代码:
CLSID clsid; |
以上三种方法,第一和第二种类似,可能第一种好用一些,第三种编程可能最麻烦。但可能第三种方法也是效率最高的,程序的尺寸也最小,并且对ADO的控制能力也最强。
据微软资料介绍,第一种方法不支持方法调用中的默认参数,当然第二种方法也是这样,但第三种就不是这样了。采用第三种方法的水平也最高。当你需要绕过ADO而直接调用OLE DB底层的方法时,就一定要使用第三种方法了。
ADO编程的关键,就是熟练地运用ADO提供的各种对象(object)、方法(method)、属性(property)和容器(collection)。另外,如果是在MS SQL或Oracle等大型数据库上编程,还要能熟练使用SQL语言。
二、使用#import方法的编程步骤
这里建议您使用#import的方法,因为它易学、易用,代码也比较简洁。
1、 添加#import指令
打开stdafx.h文件,将下列内容添加到所有的include指令之后:
#include <icrsint.h> //Include support for VC++ Extensions |
其中icrsint.h文件包含了VC++扩展的一些预处理指令、宏等的定义,用于COM编程时使用。
2、定义_ConnectionPtr型变量,并建立数据库连接
建立了与数据库服务器的连接后,才能进行其他有关数据库的访问和操作。ADO使用Connection对象来建立与数据库服务器的连接,所以它相当于MFC中的CDatabase类。和CDatabase类一样,调用Connection对象的Open方法即可建立与服务器的连接。
数据类型 _ConnectionPtr实际上就是由类模板_com_ptr_t而得到的一个具体的实例类,其定义可以到msado15.tlh、comdef.h 和comip.h这三个文件中找到。在msado15.tlh中有:
_COM_SMARTPTR_TYPEDEF(_Collection, __uuidof(_Collection)); |
经宏扩展后就得到了_ConnectionPtr类。_ConnectionPtr类封装了Connection对象的Idispatch接口指针,及一些必要的操作。我们就是通过这个指针来操纵Connection对象。类似地,后面用到的_CommandPtr和_RecordsetPtr类型也是这样得到的,它们分别表示命令对象指针和记录集对象的指针。
(1)、连接到MS SQL Server
注意连接字符串的格式,提供正确的连接字符串是成功连接到数据库服务器的第一步,有关连接字符串的详细信息参见微软MSDN Library光盘。
本例连接字符串中的server_name,database_name,user_name和password在编程时都应该替换成实际的内容。
_ConnectionPtr pMyConnect=NULL; |
注意Connection对象的Open方法中的连接字符串参数必须是BSTR或_bstr_t类型。另外,本例是直接通过OLE DB Provider建立连接,所以无需建立数据源。
(2)、通过ODBC Driver连接到Database Server连接字符串格式与直接用ODBC编程时的差不多:
_bstr_t strConnect="DSN=datasource_name; Database=database_name; uid=user_name; pwd=password;"; |
此时与ODBC编程一样,必须先建立数据源。
3、定义_RecordsetPtr型变量,并打开数据集
定义_RecordsetPtr型变量,然后通过它调用Recordset对象的Open方法,即可打开一个数据集。所以Recordset对象与MFC中的CRecordset类类似,它也有当前记录、当前记录指针的概念。如:
_RecordsetPtr m_pRecordset; |
Recordset对象的Open方法非常重要,它的第一个参数可以是一个SQL语句、一个表的名字或一个命令对象等等;第二个参数就是前面建立的连接对象的指针。此外,用Connection和Command对象的Execute方法也能得到记录集,但是只读的。
4、读取当前记录的数据
我认为读取数据的最方便的方法如下:
try{ |
本例中的name和age都是字段名,读取的字段值分别保存在sName和cAge变量内。例中的Fields是Recordset对象的容器,GetItem方法返回的是Field对象,而Value则是Field对象的一个属性(即该字段的值)。通过此例,应掌握操纵对象属性的方法。例如,要获得Field 对象的Value属性的值可以直接用属性名Value来引用它(如上例),但也可以调用Get方法,例如:
CString sName=(char*)(_bstr_t)(m_pRecordset->Fields->GetItem |
从此例还可以看到,判断是否到达记录集的末尾,使用记录集的adoEOF属性,其值若为真即到了结尾,反之则未到。判断是否到达记录集开头,则可用BOF属性。
另外,读取数据还有一个方法,就是定义一个绑定的类,然后通过绑定的变量得到字段值(详见后面的介绍)。
5、修改数据
方法一:
try{ |
改变了Value属性的值,即改变了字段的值。
方法二:
m_pRecordset->Fields->GetItem |
方法三:就是用定义绑定类的方法(详见后面的介绍)。
6、添加记录
新记录添加成功后,即自动成为当前记录。AddNew方法有两种形式,一个含有参数,而另一个则不带参数。
方法一(不带参数):
// Add new record into this table: |
这种方法弄完了还要调用Update()。
方法二(带参数):
_variant_t varName[4],narValue[4]; |
这种方法不需要调用Update,因为添加后,ADO会自动调用它。此方法主要是使用SafeArray挺麻烦。
方法三:就是用定义绑定类的方法(详见后面的介绍)。
7、删除记录
调用Recordset的Delete方法就行了,删除的是当前记录。要了解Delete的其它用法请查阅参考文献。
try{ |
8、使用带参数的命令
Command对象所代表的就是一个Provider能够理解的命令,如SQL语句等。使用Command对象的关键就是把表示命令的语句设置到CommandText属性中,然后调用Command对象的Execute方法就行了。一般情况下在命令中无需使用参数,但有时使用参数,可以增加其灵活性和效率。
(1). 建立连接、命令对象和记录集对象
本例中表示命令的语句就是一个SQL语句(SELECT语句)。SELECT语句中的问号?就代表参数,如果要多个参数,就多放几个问号,每个问号代表一个参数。
_ConnectionPtr Conn1; |
要注意命令对象必须与连接对象关联起来才能起作用,本例中将命令对象的ActiveConnection属性设置为连接对象的指针,即为此目的:
Cmd1->ActiveConnection = Conn1; |
(2). 创建参数对象,并给参数赋值
// Create Parameter Object |
用命令对象的方法来创建一个参数对象,其中的长度参数(第三个)如果是固定长度的类型,就填-1,如果是字符串等可变长度的就填其实际长度。Parameters是命令对象的一个容器,它的Append方法就是把创建的参数对象追加到该容器里。Append进去的参数按先后顺序与SQL语句中的问号从左至右一一对应。
(3). 执行命令打开记录集
// Open Recordset Object |
但要注意,用Command和Connection对象的Execute方法得到的Recordset是只读的。因为在打开Recordset之前,我们无法设置它的LockType属性(其默认值为只读)。而在打开之后设置LockType不起作用。
我发现用上述方法得到记录集Rs1后,不但Rs1中的记录无法修改,即使直接用SQL语句修改同一表中任何记录都不行。
要想能修改数据,还是要用Recordset自己的Open方法才行,如:
try{ |
Recordset对象的Open方法真是太好了,其第一个参数可以是SQL语句、表名字、命令对象指针等等。
9、响应ADO的通知事件
通知事件就是当某个特定事件发生时,由Provider通知客户程序,换句话说,就是由Provider调用客户程序中的一个特定的方法(即事件的处理函数)。所以为了响应一个事件,最关键的就是要实现事件的处理函数。
(1). 从ConnectionEventsVt接口派生出一个类
为了响应_Connection的通知事件,应该从ConnectionEventsVt接口派生出一个类:
class CConnEvent : public ConnectionEventsVt |
(2). 实现每一个事件的处理函数(凡是带raw_前缀的方法都把它实现了):
STDMETHODIMP CConnEvent::raw_InfoMessage( |
有些方法虽然你并不需要,但也必须实现它,只需简单地返回一个S_OK即可。但如果要避免经常被调用,还应在其中将adStatus参数设置为adStatusUnwantedEvent,则在本次调用后,以后就不会被调用了。
另外还必须实现QueryInterface, AddRef, 和Release三个方法:
STDMETHODIMP CConnEvent::QueryInterface(REFIID riid, void ** ppv) |
(3). 开始响应通知事件
// Start using the Connection events |
也就是说在连接(Open)之前就做这些事。
(4). 停止响应通知事件
pConn->Close(); |
在连接关闭之后做这件事。
10、邦定数据
定义一个绑定类,将其成员变量绑定到一个指定的记录集,以方便于访问记录集的字段值。
(1). 从CADORecordBinding派生出一个类:
class CCustomRs : public CADORecordBinding |
其中将要绑定的字段与变量名用BEGIN_ADO_BINDING宏关联起来。每个字段对应于两个变量,一个存放字段的值,另一个存放字段的状态。字段用从1开始的序号表示,如1,2,3等等。
特别要注意的是:如果要绑定的字段是字符串类型,则对应的字符数组的元素个数一定要比字段长度大2(比如m_szau_fname[22],其绑定的字段au_fname的长度实际是20),不这样绑定就会失败。我分析多出的2可能是为了存放字符串结尾的空字符null和BSTR字符串开头的一个字(表示BSTR的长度)。这个问题对于初学者来说可能是一个意想不到的问题。
CADORecordBinding类的定义在icrsint.h文件里,内容是:
class CADORecordBinding |
(2). 绑定
_RecordsetPtr Rs1; |
派生出的类必须通过IADORecordBinding接口才能绑定,调用它的BindToRecordset方法就行了。
(3). rs中的变量即是当前记录字段的值
//Set sort and filter condition: |
只要字段的状态是adFldOK,就可以访问。如果修改了字段,不要忘了先调用picRs的Update(注意不是Recordset的Update),然后才关闭,也不要忘了释放picRs(即picRs->Release();)。
(4). 此时还可以用IADORecordBinding接口添加新纪录
if(FAILED(picRs->AddNew(&rs))) |
11. 访问长数据
在Microsoft SQL中的长数据包括text、image等这样长类型的数据,作为二进制字节来对待。
可以用Field对象的GetChunk和AppendChunk方法来访问。每次可以读出或写入全部数据的一部分,它会记住上次访问的位置。但是如果中间访问了别的字段后,就又得从头来了。
请看下面的例子:
//写入一张照片到数据库: |
12. 使用SafeArray问题
学会使用SafeArray也是很重要的,因为在ADO编程中经常要用。它的主要目的是用于automation中的数组型参数的传递。因为在网络环境中,数组是不能直接传递的,而必须将其包装成SafeArray。实质上SafeArray就是将通常的数组增加一个描述符,说明其维数、长度、边界、元素类型等信息。SafeArray也并不单独使用,而是将其再包装到VARIANT类型的变量中,然后才作为参数传送出去。在VARIANT的vt成员的值如果包含VT_ARRAY│...,那么它所封装的就是一个SafeArray,它的parray成员即是指向SafeArray的指针。SafeArray中元素的类型可以是VARIANT能封装的任何类型,包括VARIANT类型本身。
使用SafeArray的具体步骤:
方法一:
包装一个SafeArray:
(1). 定义变量,如:
VARIANT varChunk; |
(2). 创建SafeArray描述符:
uIsRead=f.Read(bVal,ChunkSize);//read array from a file. |
(3). 放置数据元素到SafeArray:
for(long index=0;index<uIsRead;index++) |
一个一个地放,挺麻烦的。
(4). 封装到VARIANT内:
varChunk.vt = VT_ARRAY│VT_UI1; |
这样就可以将varChunk作为参数传送出去了。
读取SafeArray中的数据的步骤:
(1). 用SafeArrayGetElement一个一个地读
BYTE buf[lIsRead]; |
就读到缓冲区buf里了。
方法二:
使用SafeArrayAccessData直接读写SafeArray的缓冲区:
(1). 读缓冲区:
BYTE *buf; |
(2). 写缓冲区:
BYTE *buf; |
这种方法读写SafeArray都可以,它直接操纵SafeArray的数据缓冲区,比用SafeArrayGetElement和SafeArrayPutElement速度快。特别适合于读取数据。但用完之后不要忘了调用::SafeArrayUnaccessData(psa),否则会出错的。
13. 使用书签( bookmark )
书签可以唯一标识记录集中的一个记录,用于快速地将当前记录移回到已访问过的记录,以及进行过滤等等。Provider会自动为记录集中的每一条记录产生一个书签,我们只需要使用它就行了。我们不能试图显示、修改或比较书签。ADO用记录集的Bookmark属性表示当前记录的书签。
用法步骤:
(1). 建立一个VARIANT类型的变量
_variant_t VarBookmark;
(2). 将当前记录的书签值存入该变量
也就是记录集的Bookmark属性的当前值。
VarBookmark = rst->Bookmark;
(3). 返回到先前的记录
将保存的书签值设置到记录集的书签属性中:
// Check for whether bookmark set for a record |
设置完后,当前记录即会移动到该书签指向的记录。
14、设置过滤条件
Recordset对象的Filter属性表示了当前的过滤条件。它的值可以是以AND或OR连接起来的条件表达式(不含WHERE关键字)、由书签组成的数组或ADO提供的FilterGroupEnum枚举值。为Filter属性设置新值后Recordset的当前记录指针会自动移动到满足过滤条件的第一个记录。例如:
rst->Filter = _bstr_t ("姓名='赵薇' AND 性别=’女’"); |
在使用条件表达式时应注意下列问题:
(1)、可以用圆括号组成复杂的表达式
例如:
rst->Filter = _bstr_t ("(姓名='赵薇' AND 性别=’女’) OR AGE<25"); |
但是微软不允许在括号内用OR,然后在括号外用AND,例如:
rst->Filter = _bstr_t ("(姓名='赵薇' OR 性别=’女’) AND AGE<25"); |
必须修改为:
rst->Filter = _bstr_t ("(姓名='赵薇' AND AGE<25) OR (性别=’女’ AND AGE<25)"); |
(2)、表达式中的比较运算符可以是LIKE
LIKE后被比较的是一个含有通配符*的字符串,星号表示若干个任意的字符。
字符串的首部和尾部可以同时带星号*
rst->Filter = _bstr_t ("姓名 LIKE '*赵*' "); |
也可以只是尾部带星号:
rst->Filter = _bstr_t ("姓名 LIKE '赵*' "); |
Filter属性值的类型是Variant,如果过滤条件是由书签组成的数组,则需将该数组转换为SafeArray,然后再封装到一个VARIANT或_variant_t型的变量中,再赋给Filter属性。
15、索引与排序
(1)、建立索引
当以某个字段为关键字用Find方法查找时,为了加快速度可以以该字段为关键字在记录集内部临时建立索引。只要将该字段的Optimize属性设置为true即可,例如:
pRst->Fields->GetItem("姓名")->Properties-> |
说明:Optimize属性是由Provider提供的属性(在ADO中称为动态属性),ADO本身没有此属性。
(2)、排序
要排序也很简单,只要把要排序的关键字列表设置到Recordset对象的Sort属性里即可,例如:
pRstAuthors->CursorLocation = adUseClient; |
关键字(即字段名)之间用逗号隔开,如果要以某关键字降序排序,则应在该关键字后加一空格,再加DESC(如上例)。升序时ASC加不加无所谓。本操作是利用索引进行的,并未进行物理排序,所以效率较高。
但要注意,在打开记录集之前必须将记录集的CursorLocation属性设置为adUseClient,如上例所示。Sort属性值在需要时随时可以修改。
16、事务处理
ADO中的事务处理也很简单,只需分别在适当的位置调用Connection对象的三个方法即可,这三个方法是:
(1)、在事务开始时调用
pCnn->BeginTrans(); |
(2)、在事务结束并成功时调用
pCnn->CommitTrans (); |
(3)、在事务结束并失败时调用
pCnn->RollbackTrans (); |
在使用事务处理时,应尽量减小事务的范围,即减小从事务开始到结束(提交或回滚)之间的时间间隔,以便提高系统效率。需要时也可在调用BeginTrans()方法之前,先设置Connection对象的IsolationLevel属性值,详细内容参见MSDN中有关ADO的技术资料。
三、使用ADO编程常见问题解答
以下均是针对MS SQL 7.0编程时所遇问题进行讨论。
1、连接失败可能原因
Enterprise Managemer内,打开将服务器的属性对话框,在Security选项卡中,有一个选项Authentication。
如果该选项是Windows NT only,则你的程序所用的连接字符串就一定要包含Trusted_Connection参数,并且其值必须为yes,如:
"Provider=SQLOLEDB;Server=888;Trusted_Connection=yes" |
如果不按上述操作,程序运行时连接必然失败。
如果Authentication选项是SQL Server and Windows NT,则你的程序所用的连接字符串可以不包含Trusted_Connection参数,如:
"Provider=SQLOLEDB;Server=888;Database=master;uid=lad;pwd=111;"; |
因为ADO给该参数取的默认值就是no,所以可以省略。我认为还是取默认值比较安全一些。
2、改变当前数据库的方法
使用Tansct-SQL中的USE语句即可。
3、如何判断一个数据库是否存在
(1)、可打开master数据库中一个叫做SCHEMATA的视图,其内容列出了该服务器上所有的数据库名称。
(2) 、更简便的方法是使用USE语句,成功了就存在;不成功,就不存在。例如:
try{ |
4、判断一个表是否存在
(1)、同样判断一个表是否存在,也可以用是否成功地打开它来判断,十分方便,例如:
try{ |
(2)、要不然可以采用麻烦一点的办法,就是在MS-SQL服务器上的每个数据库中都有一个名为sysobjects的表,查看此表的内容即知指定的表是否在该数据库中。
(3)、同样,每个数据库中都有一个名为TABLES的视图(View),查看此视图的内容即知指定的表是否在该数据库中。
5、类型转换问题
(1)、类型VARIANT_BOOL
类型VARIANT_BOOL等价于short类型。The VARIANT_BOOL is equivalent to short. see it's definition below:
typdef short VARIANT_BOOL
(2)、_com_ptr_t类的类型转换
_ConnectionPtr可以自动转换成IDspatch*类型,这是因为_ConnectionPtr实际上是_com_ptr_t类的一个实例,而这个类有此类型转换函数。
同理,_RecordsetPtr和_CommandPtr也都可以这样转换。
(3)、_bstr_t和_variant_t类
在ADO编程时,_bstr_t和_variant_t这两个类很有用,省去了许多BSTR和VARIANT类型转换的麻烦。
6、打开记录集时的问题
在打开记录集时,在调用Recordset的Open方法时,其最后一个参数里一定不能包含adAsyncExecute,否则将因为是异步操作,在读取数据时无法读到数据。
7、异常处理问题
对所有调用ADO的语句一定要用try和catch语句捕捉异常,否则在发生异常时,程序会异常退出。
8、使用SafeArray问题
在初学使用中,我曾遇到一个伤脑筋的问题,一定要注意:
在定义了SAFEARRAY的指针后,如果打算重复使用多次,则在中间可以调用::SafeArrayDestroyData释放数据,但决不能调用::SafeArrayDestroyDescriptor,否则必然出错,即使调用SafeArrayCreate也不行。例如:
SAFEARRAY *psa; |
我分析在定义psa指针时,一个SAFEARRAY的实例(也就是SAFEARRAY描述符)也同时被自动建立了。但是只要一调用::SafeArrayDestroyDescriptor,描述符就被销毁了。
所以我认为::SafeArrayDestroyDescriptor可以根本就不调用,即使调用也必须在最后调用。
9、重复使用命令对象问题
一个命令对象如果要重复使用多次(尤其是带参数的命令),则在第一次执行之前,应将它的Prepared属性设置为TRUE。这样会使第一次执行减慢,但却可以使以后的执行全部加快。
10、绑定字符串型字段问题
如果要绑定的字段是字符串类型,则对应的字符数组的元素个数一定要比字段长度大2(比如m_szau_fname[22],其绑定的字段au_fname的长度实际是20),不这样绑定就会失败。
11、使用AppendChunk的问题
当用AddNew方法刚刚向记录集内添加一个新记录之后,不能首先向一个长数据字段(image类型)写入数据,必须先向其他字段写入过数据之后,才能调用AppendChunk写该字段,否则出错。也就是说,AppendChunk不能紧接在AddNew之后。另外,写入其他字段后还必须紧接着调用AppendChunk,而不能调用记录集的Update方法后,才调用AppendChunk,否则调用AppendChunk时也会出错。换句话说,就是必须AppendChunk在前,Update在后。因而这个时候就不能使用带参数的AddNew了,因为带参数的AddNew会自动调用记录集的Update,所以AppendChunk就跑到Update的后面了,就只有出错了!因此,这时应该用不带参数的AddNew。
我推测这可能是MS SQL 7.0的问题,在MS SQL 2000中则不存在这些问题,但是AppendChunk仍然不能在Update之后。
四、小结
一般情况下,Connection和Command的Execute用于执行不产生记录集的命令,而Recordset的Open用于产生一个记录集,当然也不是绝对的。特别Command主要是用于执行参数化的命令,可以直接由Command对象执行,也可以将Command对象传递给Recordset的Open。
本文中的代码片断均在VC++ 6.0、Windows NT 4.0 SP6和MS SQL 7.0中调试通过。相信您读过之后,编写简单的数据库程序应该没有问题了。当然要编写比较实用的、复杂一点的程序,还需要对OLE DB、ADO以及数据库平台再多了解一点,希望您继续努力,一定会很快成功的!详细参考资料请参见微软MSDN July 2000光盘或MS SQL 7.0在线文档资料(Books online)。文中难免有错误和不妥之处,敬请各位批评指正!
