




目前随着国产化的需求,企业数据库处理也面临着三座大山:第一是“过去”:业务数据孤岛;其次是“现在”:MPP数据库解决了
结构化业务数据的分析问题;最后是“未来”:大数据的挑战,全数据、多模型、异构、新技术…
企业的数据库也随之面临着处理变快Velocity,数据延时长,无法实时指导运营;类型变多Variety,数据源增多,结构化半结构化和非结构化数据类型;
负载变大Volume,数据量大,应用增多,数据库无法存储数据,承载负担;价值变高Value,传统数据模型无法有效支持深度挖掘,无法快速发现数据价值 这四大挑战。
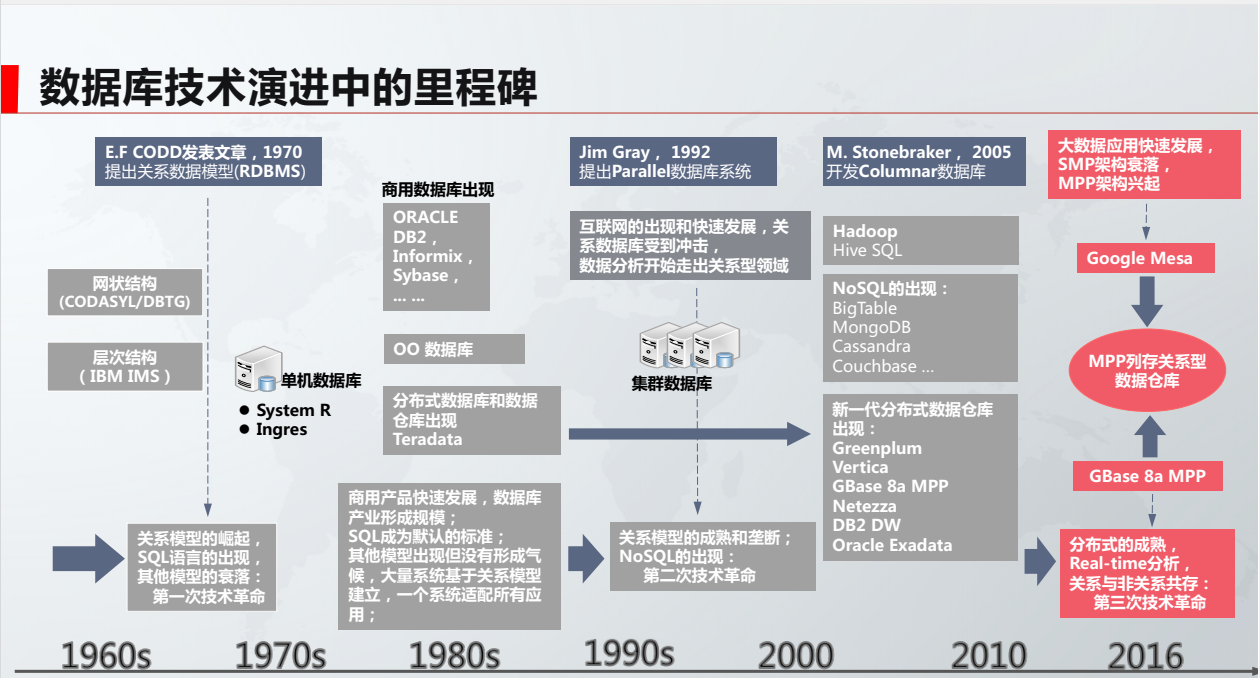
在数据库技术发展过程中,演变的里程碑:
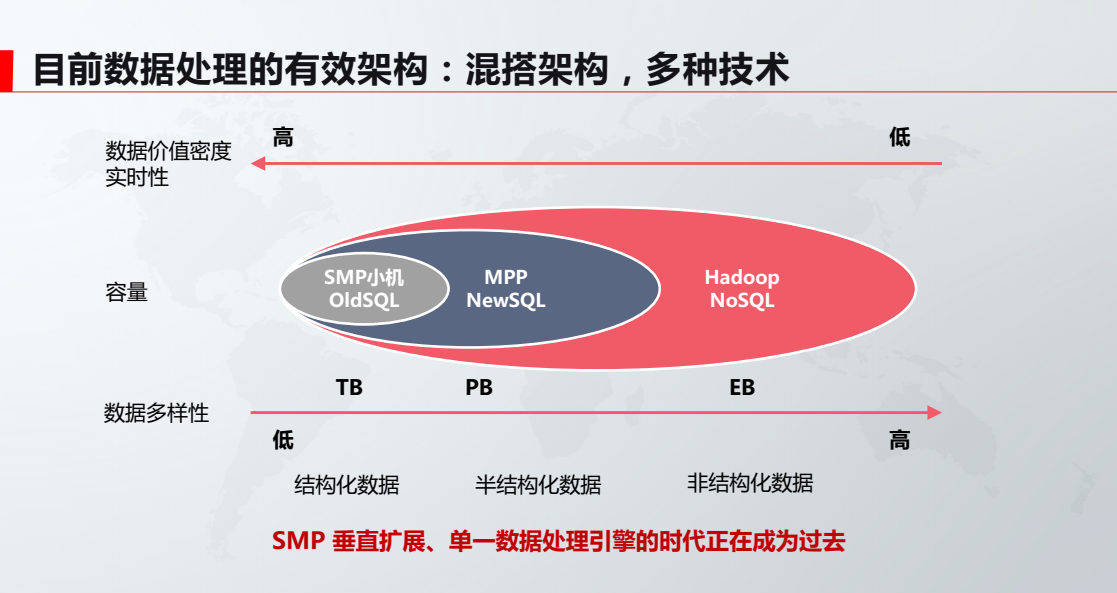
由此,大数据引发了处理架构的多元化。目前数据处理的有效架构:混搭架构,多种技术。
那么GBase UP具备哪些性能优势呢?
MPP VS. Hadoop - 性能对比
TPC-DS基准测试的特点:
• 共99个测试案例,遵循SQL99和SQL 2003的语法标准,SQL案例比较复杂
• 测试案例包含各种业务模型(如分析报告,迭代式联机分析,数据挖掘等)
• 分析的数据量大,并且测试案例是在回答真实的商业问题
• 几乎所有的测试案例都有很高的IO负载和CPU计算需求
MPP VS. Impala - 性能对比
TPC-H基准测试的特点:
• 同数据、同环境下的性能,Impala与MPP对比,根据数据特点不同,Impala较MPP会有低于7~12.3倍的性能差异
• Impala优化手段极其复杂,需要专业人士才能完成
• 不支持高精度decimal类型, 因此在实际生产环境中基本不可用
• 没有事务能力,加载和执行insert过程中可以看到脏数据,因此在实际生产环境中基本不可用
• 750G左右的数据,MPP加载17分钟,Impala +kudu加载需要23.5小时, 因此在实际生产环境中基本不可用
• 查询执行不稳定,执行SQL有时报错,当不执行任何任务时,也发现后台在做大量的IO操作,此时执行任何SQL都会报错(包括执行select count(*)这样简单的SQL), 因此在实际生产环境中基本不可用。
Hadoop价值:非结构化数据 & 深度机器学习
Hadoop
• 非结构化数据接入和实时分析
• 历史数据查询分析
Spark
• 流数据处理
• 深度机器学习
• 图算法引擎
• R语言非结构数据算法分析
MPP和Hadoop混搭方案进行数据处理
GBase MPP擅长:
• 报表
• 即席查询
• 结构化数据模型化处理(涉及表关联,星型化/雪花形化)/ETL/ELT
• 结构化的OLAP:多表关联、复杂查询、大数据查询、大数据插入
Hadoop擅长:
• 批处理/多表全表扫描
• 实时流处理
• 图计算
• 简单查询和迭代的算法(如聚类分类算法)
• 非结构化数据存储和转换
