




:基数
在数据库中,某一列的唯一键(distinct Keys)的数量叫作基数。
比如性别列,该列只有男女之分,那么这一列基数是2。而主键列的基数等于表的总行数。
查看某个列的基数。
select count(distinct column_name) from table_name;
选择性
列的基数与表中总行数的比值再乘以100%就是某个列的选择性。
列的选择性可以衡量数据库索引能够帮助缩小对表中特定值的搜索范围的程度。
查看某个列的选择性。
select Concat((count(distinct column_name) / count(*))*100,'%') from table_name;
我们知道索引最重要的目的之一是尽可能地缩小匹配行的初始候选值,从而减少io,提升查询性能。所以通常来说索引的选择性越高则查询效率越高,因为选择性高的索引可以让数据库在查找时过滤掉更多的行。
了解列的选择性的作用
帮助我们更好地创建复合索引。
在建立复合索引时,一般我们要把选择性更高的列放在前面,以尽可能地缩小匹配行的初始候选值。
帮助我们更好地创建前缀索引。
比如在mysql中,建立前缀索引的意义在于相对于整列建立索引,前缀索引仅仅是选择该列的部分字符作为索引,减少索引的字符可以节约索引空间,从而提高索引效率,但这样也会降低索引的选择性。
建立合理前缀索引的诀窍在于要选择足够长的前缀以保证较高的选择性,同时又不能太长(以便节约空间)。
那么确定前缀索引的长度呢?
答:前缀应该足够长,以使得前缀索引的选择性接近于索引的整个列的选择性。
举个例子,假设整个列的选择性是0.6。那么我们应该去分别去看每个索引长度的选择性,直到找到第一个接近0.6的索引长度。
整个列的选择性。
select count(distinct column_name) / count(*) from table_name;
找出合适的前缀长度。
select count(distinct left(column_name,1))/count(*) as sel1, count(distinct left(column_name,2))/count(*) as sel2, count(distinct left(column_name,3))/count(*) as sel3, count(distinct left(column_name,4))/count(*) as sel4 from table_name;
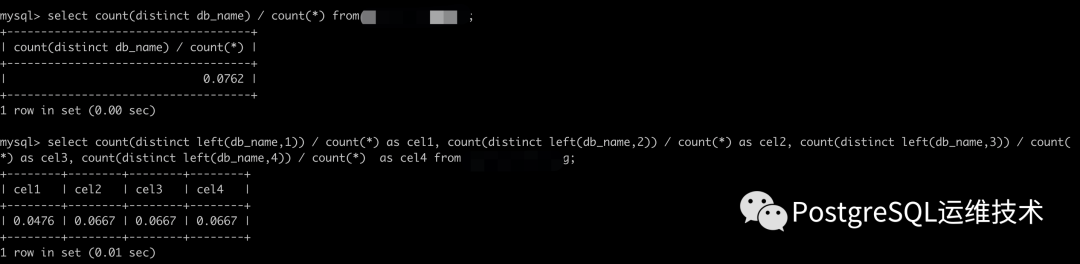
比如下图所示的结果,我们就应该选择left(db_name,3)了。
创建前缀索引:
alter table table_name add index idx_db_name(db_name(3));
总结
基数:在数据库中,某一列的唯一键(distinct Keys)的数量叫作基数。
选择性:列的基数与表中总行数的比值再乘以100%就是某个列的选择性。
了解列的基数和选择性的概念可以帮助我们更好地创建性能更高的索引,比如我们一般把选择性更好的列放到复合索引的前面,创建前缀索引时,前缀应该足够长,以使得前缀索引的选择性接近于索引的整个列的选择性。
参考:
https://orangematter.solarwinds.com/2018/07/18/what-is-database-index-selectivity/ https://orangematter.solarwinds.com/2020/01/05/what-is-cardinality-in-a-database/
https://blog.csdn.net/dhrome/article/details/72853153
《SQL优化核心思想》

点个“赞 or 在看” 你最好看!

👇👇👇谢谢各位老板!!!
