




Spark目前最新版本为Spark3.x,这个大版本没有架构层面的变化,主要是针对SparkSQL性能优化层面的改进。
1:Spark 1.x~3.x的演变历史
在Spark 1.x中,主要是通过Rule这个执行框架,把一批规则应用在一个执行计划上进而得到一个新的执行计划。
在Spark 2.x中增加了基于计算的Cost模型,该Cost模型是为了让SparkSQL获得更好的优化效果,进而获得高效的执行计划,在应用基于 Cost模型优化的时候,需要对数据进行统计。
但是Cost模型在Spark中表现的并不好,主要是由于下面这几点原因:
一次性计算。
因为Spark的主要计算场景就是ETL,对数据只需要计算一次,但是它收集数据的成本是比较昂贵的,所以在最初生成任务执行计划的时候会缺少真实数据的统计信息,统计信息的缺失会导致基于Cost的优化基本不可能完成。
存储和计算的分离。
Spark不存储数据,用户可以通过不同的方式操作数据,如果统计信息出现错误,无法保证基于Cost优化的正确性,甚至优化后的结果可能会更差。
多种环境的部署。
在不同环境中Cost的模型是多样的。无法使用一套通用的Cost模型,而且针对Spark中的UDF功能,用户需要根据自己的需要任意添加。这种情况下也无法实现基于Cost的优化。
基于以上原因导致很多时候难以计算Cost模型,进而导致无法获取有效的优化计划。
因此,Spark 3.0 在Cost基础之上增加了Runtime,Runtime可以收集任务在运行期间的统计信息,实现动态优化任务的执行计划。
也就是说任务在最开始的时候先生成一个初始的执行计划,随着任务的执行,根据runtime收集到的运行期间的统计信息,可以对初始的执行计划进行动态优化修改,生成新的执行计划去执行。
2:Spark 3.x 新特性
总结下来大致包括下面这几个:
自适应查询执行(Adaptive Query Execution),可以简称为AQE
动态分区裁剪(Dynamic Partition Pruning),可以简称为DPP
加速器感知调度(Accelerator-aware Scheduling)
Catalog 插件 API(Catalog plugin API)
支持 Hadoop 3.x Java 11 Scala 2.12
更好的 ANSI SQL 兼容性(Better ANSI SQL compatibility)
Pandas API 的重大改进(Redesigned pandas UDF API with type hints)
用于流计算的新UI(Structured Streaming UI)
本文重点分析自适应查询执行(AQE)这个重要新特性!
自适应查询执行:可以简称为AQE。它是对Spark执行计划的优化,它可以基于任务运行时统计的数据指标动态修改Spark 的执行计划。
Spark 原有的执行计划是静态生成的,一旦代码编译好,即使后续发现执行计划可优化,也无法改变了。而自适应查询执行功能是在执行查询计划的同时,基于精确的运行时统计信息,对执行计划进行优化,进而提升性能。
通俗一点来说可以这样理解:
一个复杂的Spark任务在运行期间会产生多个State。假设有State0、Stage1和Stage2。

每个Stage内部都会有一系列的执行逻辑。
当Stage0执行结束之后,会产生一个中间结果,其实就是RDD,此时这个RDD中的数据量是可以准确获取到的。自适应查询机制就是根据这里的数据统计信息来决定是否对后面Stage1中的执行计划进行优化。
当Stage1执行结束后,再根据它产生的RDD数据来决定是否对后面Stage2中的执行计划进行优化
后面如果还有Stage,以此类推。
自适应查询执行主要带来了下面这3点优化功能:
1.自适应调整Shuffle分区数量。
2.动态调整 Join 策略。
3.动态优化倾斜的 Join。
首先看第1个:自适应调整Shuffle分区数量
2.1 自适应调整Shuffle分区数量
Spark在处理海量数据的时候,其中的Shuffle过程是比较消耗资源的,也比较影响性能,因为它需要在网络中传输数据。
shuffle 中的一个关键属性是:分区的数量。
分区的最佳数量取决于数据自身大小,但是数据大小可能在不同的阶段、不同的查询之间有很大的差异,这使得这个数字很难精准调优。
如果分区数量太多,每个分区的数据就很小,读取小的数据块会导致IO效率降低,并且也会产生过多的task, 这样会给Spark任务带来更多负担。
如果分区数量太少,那么每个分区处理的数据可能非常大,处理这些大分区的数据可能需要将数据溢写到磁盘(例如:排序或聚合操作),这样也会降低计算效率。
想要解决这个问题,就需要给Shuffle设置合适的分区数量,如果手工设置,基本上是无法达到最优效率的。想要达到最优效率,就需要依赖于我们这里所说的自适应调整Shuffle分区数量这个策略了。
那么这个自适应调整Shuffle分区数量的底层策略是怎么实现的呢?
Spark初始会设置一个较大的Shuffle分区个数,这个数值默认是200,后续在运行时会根据动态统计到的数据信息,将小的分区合并,也就是慢慢减少分区数量。
假设我们运行下面这个SQL语句:
select flag,max(num) from t1 group by flag
这个SQL语句,表t1中的数据比较少。
现在我们把初始的Shuffle 分区数量设置为5,所以在 Shuffle 过程中数据会产生5 个分区。如果没有开启自适应调整Shuffle分区数量这个策略,Spark会启动5个Recuce任务来完成最后的聚合。但是这里面有3个非常小的分区,为每个分区分别启动一个单独的任务会浪费资源,并且也无法提高执行效率。因为这3个非常小的分区对应的任务很快就执行完了,另外2个比较大的分区对应的任务需要执行很长时间,资源没有被充分利用到。
看下面这个图:
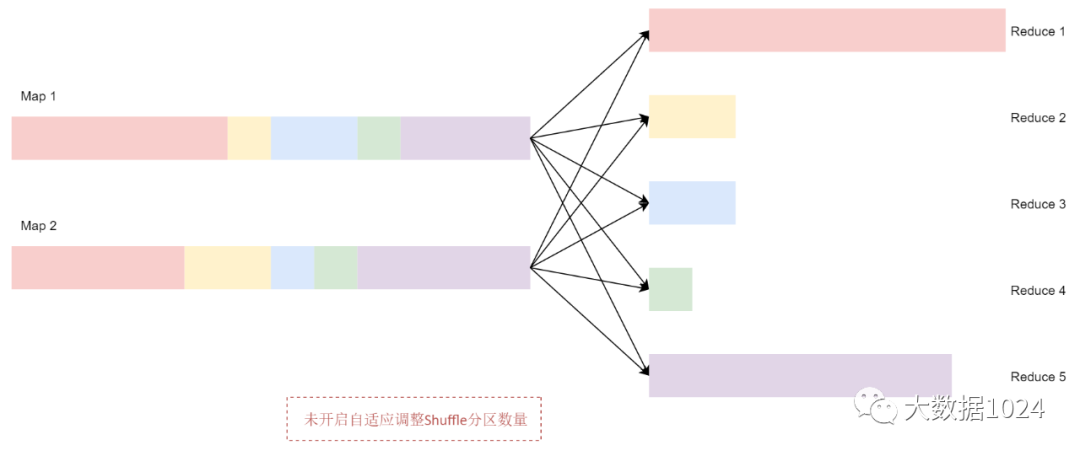
开启自适应调整Shuffle分区数量之后,Spark 会将这3个数据量比较小的分区合并为1个分区,让1个reduce任务处理,这个时候最终的聚合操作只需要启动3个reduce任务就可以了。
看下面这个图:
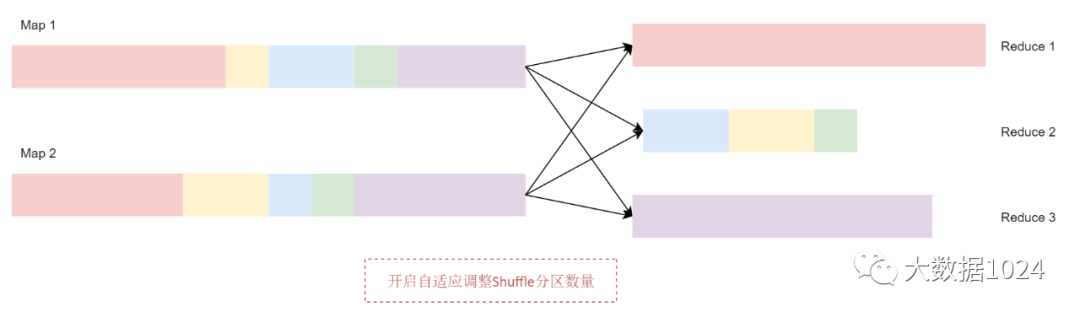
关于自适应调整Shuffle分区数量这个机制的核心参数主要包括下面这几个:
| 核心参数 | 默认值 | 解释 |
| spark.sql.adaptive.enabled | true | 是否开启AQE机制 |
| spark.sql.adaptive.coalescePartitions.enabled | true | 是否开启AQE中的自适应调整Shuffle分区数量机制 |
| spark.sql.adaptive.advisoryPartitionSizeInBytes | 67108864b (64M) | 建议的Shuffle分区大小 |
解释:
spark.sql.adaptive.enabled:这个参数是控制整个自适应查询执行机制是否开启的,也就是控制AQE机制的。默认值是true,表示默认是开启的。
spark.sql.adaptive.coalescePartitions.enabled:这个参数才是真正控制自适应调整Shuffle分区数量这个机制是否开启的。默认值是true,表示默认也是开启的。注意:想要开启这个功能,第1个参数肯定也要设置为true。因为自适应调整Shuffle分区数量这个机制是AQE机制中的一个子功能。
spark.sql.adaptive.advisoryPartitionSizeInBytes:这个参数是控制shuffle中分区大小的,默认是64M。理论上来说,这个参数越大,shuffle中最终产生的分区数量就越少,但是也不能太大,太大的话的产生的分区数量就太少了,会导致产生的任务数量也变少,最终会影响执行效率。
注意:针对自适应调整Shuffle分区数量的实战案例演示,请到课程中查看最新更新的内容,如下图所示:

2.2 动态调整Join策略
Spark中支持多种Join 策略,其中 BroadcastHashJoin的性能通常是最好的,但是前提是参加Join的其中一张表的数据能够存入内存。
基于这个原因,当Spark评估参加Join的表的数据量小于广播大小的阈值时,会将Join策略调整为BroadcastHashJoin。广播大小的阈值默认是10M。
但是,很多情况都可能导致这种大小的评估出错。例如:Join的时候SQL语句中存在过滤器。
开启了自适应查询执行机制之后,可以在运行时根据最精确的数据指标重新规划Join策略,实现动态调整Join策略。
看下面这个图:
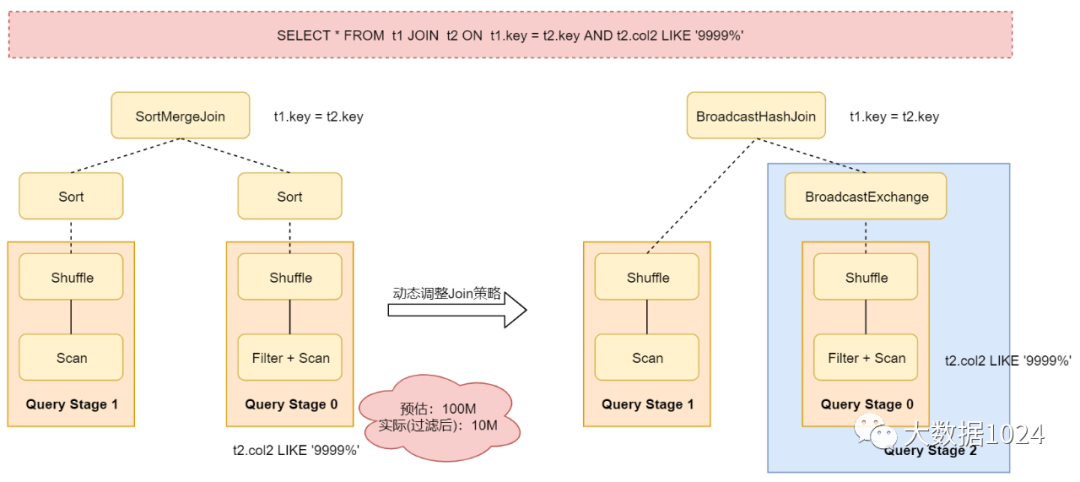
从这个图里面可以看到,对表t2进行过滤之后的数据大小比预估值小得多,并且小到足以进行广播,因此在重新优化之后,之前静态生成的SortMergeJoin策略就会被转换为BroadcastHashJoin策略了。
针对动态调整Join策略的核心参数主要包括下面这1个:
| 核心参数 | 默认值 | 解释 |
| spark.sql.adaptive.autoBroadcastJoinThreshold | none | 设置允许广播的表的最大值。 设置为-1表示禁用。 如果未设置会参考spark.sql.autoBroadcastJoinThreshold参数的值(10M)。 |
解释:
spark.sql.adaptive.autoBroadcastJoinThreshold:这个参数没有默认值,通过这个参数可以控制允许广播的表的最大值。当两个表进行join的时候,如果一个表比较小,可以通过广播机制广播出去,这样就可以把本来是reduce端的join,改为map端的join,提高join效率。如果把这个参数的值设置为-1,表示禁用自动广播策略。如果我们没有给这个参数设置值,则默认会使用spark.sql.autoBroadcastJoinThreshold参数的值,这个参数的值默认是10M。那也就是说当一个表中的数据小于10M的时候在这里支持将这个表广播出去。
注意:针对动态调整Join策略的实战案例演示,请到课程中查看最新更新的内容,如下图所示:

2.3 动态优化倾斜的Join
在进行Join操作的时候,如果数据在多个分区之间分布不均匀,很容易产生数据倾斜,如果数据倾斜比较严重会显著降低计算性能。
动态优化倾斜的 Join这个机制会从Shuffle文件统计信息中自动检测到这种倾斜,然后它会将倾斜的分区做进一步切分,切分成更小的子分区,这些子分区会连接到对应的分区进行关联。
在Spark 3.0版本之前,如果在join的时候遇到了严重的数据倾斜,是需要我们自己对数据进行切分处理,提高计算效率的。现在有了动态优化倾斜的 Join这个机制之后就很方便了。
假设有两个表 t1和t2,其中表t1中的P0分区里面的数据量明显大于其他分区,默认的执行情况是这样的,看这个图:
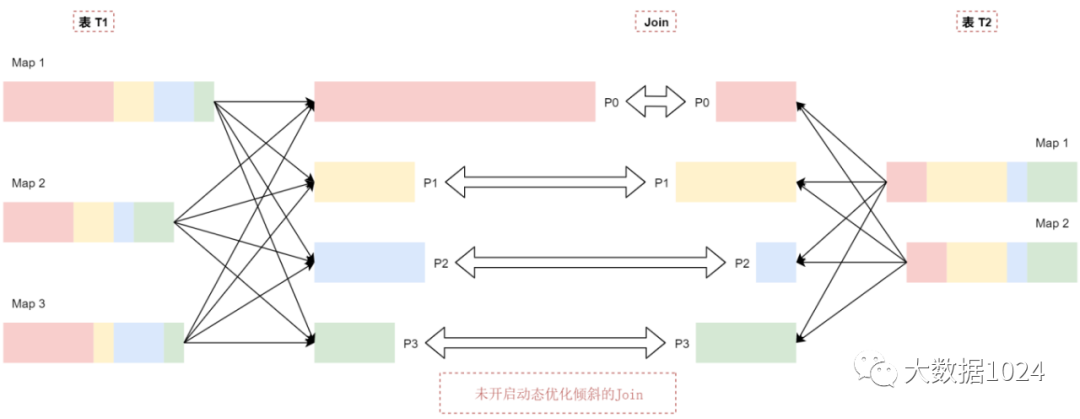
t1表中p0分区的数据比p1\p2\p3这几个分区的数据大很多,可以认为t1表中的数据出现了倾斜。
当t1和t2表中p1、p2、p3这几个分区在join的时候基本上是不会出现数据倾斜的,因为这些分区的数据相对适中。但是P0分区在进行join的时候就会出现数据倾斜了,这样会导致join的时间过长。
动态优化倾斜的 Join机制会把P0分区切分成两个子分区P0-1和P0-2,并将每个子分区关联到表t2的对应分区P0,看这个图:
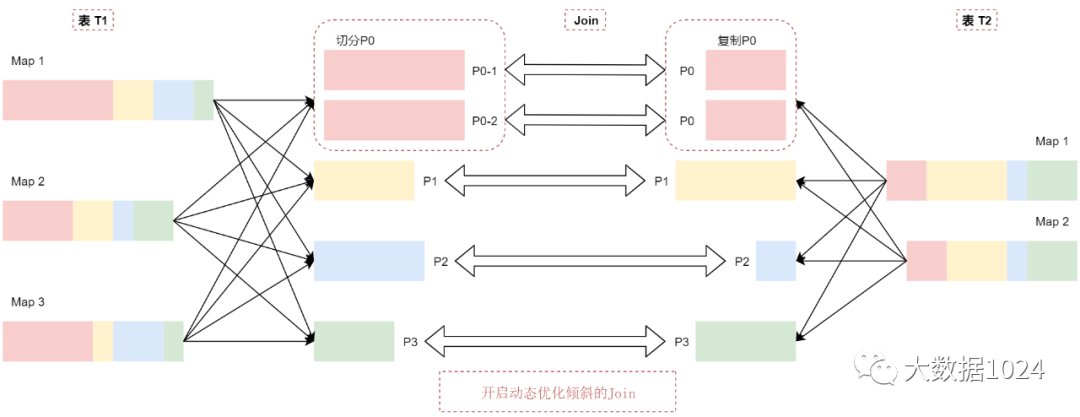
t2表中的P0分区会复制出来两份相同的数据,和t1表中切分出来的P0分区的数据进行Join关联。
这样相当于就把t1表中倾斜的分区拆分打散了,最终在join的时候就不会产生数据倾斜了。
如果没有这个优化,将有4个任务运行Join操作,其中P0分区对应的任务将消耗很长时间。优化之后,会有5个任务运行Join操作,每个任务消耗的时间大致相同,这样就可以获得最优的执行性能了。
针对动态优化倾斜的 Join策略的核心参数主要包括下面这3个:
| 核心参数 | 默认值 | 解释 |
| spark.sql.adaptive.skewJoin.enabled | true | 是否开启AQE机制中的动态优化倾斜的Join机制 |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 5 | 数据倾斜判断因子,必须同时满足(数据倾斜判断阈值) |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes | 268435456b (256M) | 数据倾斜判断阈值,必须同时满足(数据倾斜判断因子) |
解释:
spark.sql.adaptive.skewJoin.enabled:默认值是true,表示默认开启AQE机制中的动态优化倾斜的Join机制。
spark.sql.adaptive.skewJoin.skewedPartitionFactor:默认值是5,这个参数属于判断分区数据倾斜的一个因子。
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes:默认值是256M,这个参数也属于判断分区数据倾斜的一个因子。
如果Shuffle中的一个分区的大小大于skewedPartitionFactor这个因子乘以Shuffle分区中位数的值,并且这个分区也大于skewedPartitionThresholdInBytes这个参数的值,则认为这个分区是倾斜的。
理想情况下,skewedPartitionThresholdInBytes参数的值应该大于advisoryPartitionSizeInBytes参数的值。因为后期在切分这个倾斜的分区时会依据advisoryPartitionSizeInBytes参数的值进行切分,如果skewedPartitionThresholdInBytes参数的值小于advisoryPartitionSizeInBytes的值,那就无法切分了。
通过下面这个图,可以更加清晰的理解如何判断数据倾斜:

如果分区A中的数据大小 大于 skewedPartitionFactor * 分区大小的中位数。
并且分区A中的数据大小 也大于 skewedPartitionThresholdInBytes参数的值,则分区A就是一个倾斜的分区了,那也就意味着这个任务中的数据出现了数据倾斜,这样才会触发动态优化倾斜的Join功能。
注意:针对动态优化倾斜的Join的实战案例演示,请到课程中查看最新更新的内容,如下图所示:

本文完!
