




一、StarRocks特性
StarRocks是一款极速全场景MPP分析型数据库,可以“一栈式”的响应企业各类低延迟场景的查询需求。
为了对StarRocks有一个准确的认知,我们不妨将StarRocks概念的关键词逐项展开介绍:“极速”、“全场景”、“MPP”和“分析型数据库”。
极速
StarRocks打造了原生向量化执行引擎,采用向量化技术,充分利用CPU的并行计算能力,在多维分析中实现亚秒级查询返回。StarRocks的向量化技术配合列式存储、智能物化视图和CBO查询优化器等诸多加速手段,实现较以往系统5-10倍的性能提升。
全场景
StarRocks兼容MySQL协议,我们可以方便的使用各种客户端和BI工具来访问它。StarRocks可以灵活的满足多类数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等,让用户摆脱冗杂的技术栈。让数据分析不再需要做Cube,也不需要打成宽表,而是通过星型模型、雪花模型等进行多表关联灵活join,真正的“一栈式”解决数据分析难题。
同时,StarRocks还具有强大的联邦查询能力,支持创建外部表直接访问来自Hive、MySQL和Elasticsearch的数据,而无需导入。
MPP架构
StarRocks使用现代化MPP(Massively Parallel Processing,大规模并行处理)架构,简单来说,StarRocks会将任务并行的分散到集群多个服务器节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。这种架构下,StarRocks集群每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过网络互相连接,彼此协同计算,作为整体提供数据库服务。StarRocks的现代化MPP架构保证了StarRocks具有可伸缩、高可用、高性能、高性价比、高容错、易运维等优势。
分析型数据库
StarRocks的定位是OLAP分析型数据库,这也就是说它适合对大规模的数据进行多维度的查询分析,而不适合像OLTP类数据库(比如MySQL)一样对少量的数据进行大并发频繁的插入和修改。经过业界头部互联网公司的长期使用验证,StarRocks完全可以应对PB级别的结构化数据分析场景,查询时间一般可达到秒级或毫秒级。
二、StarRocks架构
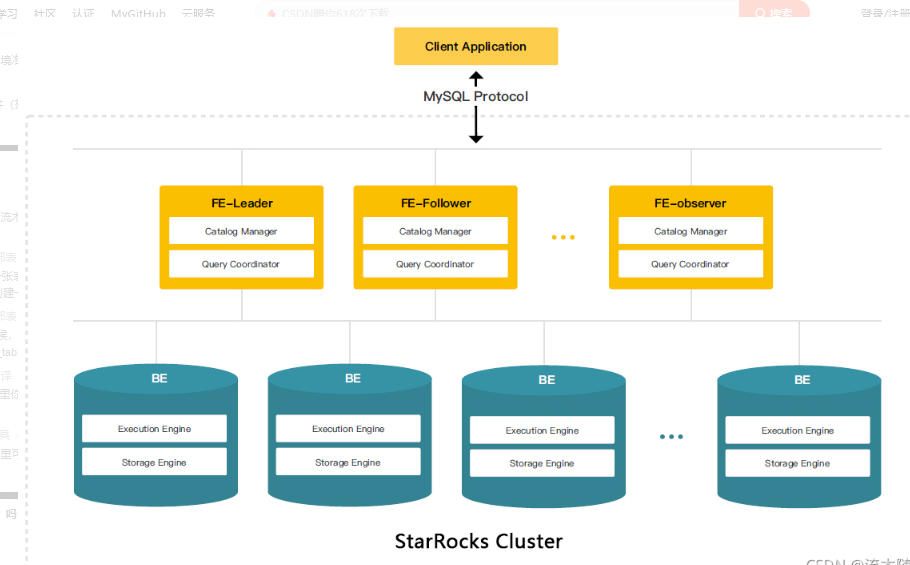
针对上面的架构图,由上至下简单介绍几个基本概念:
Client
StarRocks没有自带客户端,推荐使用mysql-client进行访问。StarRocks兼容MySQL协议,所以我们可以使用任意的MySQL JDBC/ODBC客户端,例如SQLyog、DBeaver、Navicat等,将StarRocks视为MySQL进行连接访问。
FE
StarRocks的前端节点,使用Java语言编写,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。准确来说,FE有两种角色:Follower和Observer,其中Follower会通过类raft的bdbje协议选主出一个Leader(实现选主需要集群中有半数以上的Follower实例存活),只有Leader会对元数据进行写操作。Observer和Follower的差别就是Observer不会参与选主。Observer同样不会进行任何的数据写入,只会参与读取,用来扩展集群的查询能力。每个FE节点都有一份完整的元数据,以此来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
BE
StarRocks的后端节点,使用C++语言开发,负责数据存储,计算执行,以及compaction,副本管理等工作。StarRocks会将我们创建的表根据分区和分桶机制划分成多个Tablet多副本存储在不同BE节点上。这里的Tablet是StarRocks表的逻辑分片,也是StarRocks中副本管理的基本单位。
Broker
在上面的架构图中没有体现,它是StarRocks和外部HDFS/对象存储等外部数据对接的中转服务组件,辅助提供导入导出功能,可以视需求添加使用。Broker本身无状态,可以随意启停,不会影响集群。
三、StarRocks业务架构
在对StarRocks的架构有了基本的了解后,我们再简单介绍一下企业使用StarRocks时,大数据架构的整体设计。下图就是一个常见的大数据业务架构图,StarRocks在整个大数据架构中一般会处在比较靠上的位置,我们会将数据ETL后导入至StarRocks,而后提供给上层的各类业务系统进行展示和分析。
在这套架构中,Hadoop作为大数据存储和批量处理的行业标准,用于原始数据的落地和存储。Kafka用于支持实时数据的传输。Hive,Spark,Flink作为数据加工和处理的工具,将经过清洗和处理的明细数据导入StarRocks。根据业务对数据实时性的要求,我们既可以按照“T+1”的方式批量导入,也可以进行实时的导入。在StarRocks中对明细数据进行进一步的计算、聚合、建立物化视图等处理后,便可以直接提供给上层的各类线上业务系统。
上层应用可以根据自身需要,通过标准SQL语句直接查明细数据,或者查聚合数据。查询的灵活性完全由SQL语句来提供,不需要再额外开发其他用于数据处理的程序模块。
