




引言
本文内容:深入理解RDD,RDD的基本特性,RDD的创建,和RDD源码解析
01
—
学习RDD的必要性
RDD是spark重要概念,深入理解RDD有利于理解整个Spark的工作原理,虽然现在已经很少写RDD的API,但是当使用DataFrame或者DataSet的时候,底层最终还是会转换成RDD进行执行,如果想解决运行时的性能瓶颈,必须理解RDD。
02
—
RDD概念理解
(1)自动进行内存和磁盘数据切换
(2)基于Lineage的高效容错(第n个节点计算错误,会从第n-1个节点恢复)
(3)Task如果失败进行特定次数重试
(4)Task如果计算失败会自动进行特定次数重试,而且只会计算失败的分片数据(默认4次)
(5)checkpoint和persist(cache)
(6)数据调度弹性:DAG task 和资源管理无关
(7)数据分片的高度弹性,partition很小的时候把多个partition合并成一个大的partition,或内存比较小,partition数据比较大,这个时候划分分片比较多,这个是人工作的。不是自动的。
03
—
RDD的其它理解
(1)spark中计算结果可以重复使用,第一个运行计算结果后,第二个计算如果和前面的计算相同,可以利用第一个计算,接着计算不同部分。
(2)RDD是分布函数编程的抽象
(3)RDD是懒加载的
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {val cleanF = sc.clean(f)new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))}
这里的this是父RDD,这样做是为了进行计算的时候能够从后向前展开如下:
f(x)=x+1;
x = y+2
y = z+3
f(x) = z +3 + 2 +1
这里说明spark比hadoop快是必然的,不用每次都保存到磁盘,然后再读取数据。
spark会直接展开进行一次计算f(x) = z +3 + 2 +1,不会一个一个计算。
(4)容错方式
数据检查点
记录的更新
(5)记录更新方式高效
RDD是不可变的且是lazy,(从后向前回溯,不会每次都有一个计算结果。如果有100个步骤,在90个步骤出错,会从前一个步骤89个进行计算,不会从第1个步骤进行计算)
RDD是粗粒度(为了效率,为了简化,注意RDD可以粗粒度也可以细粒度)
04
—
RDD的5个主要特性
* Internally, each RDD is characterized by five main properties:** - A list of partitions* - A function for computing each split* - A list of dependencies on other RDDs* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for* an HDFS file)
05
—
RDD的创建
(1)使用集合创建RDD
(2)使用本地文件创建RDD
(3)使用HDFS文件创建RDD
06
—
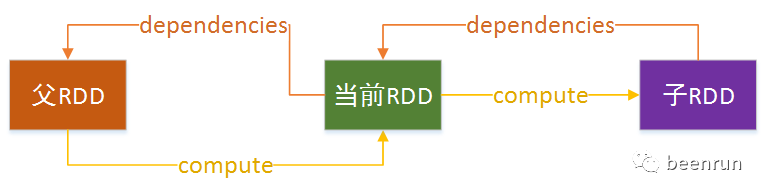
源码解析
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](var prev: RDD[T],f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)preservesPartitioning: Boolean = false,isFromBarrier: Boolean = false,isOrderSensitive: Boolean = false)extends RDD[U](prev) {override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else Noneoverride def getPartitions: Array[Partition] = firstParent[T].partitionsoverride def compute(split: Partition, context: TaskContext): Iterator[U] =f(context, split.index, firstParent[T].iterator(split, context))...}
(1)横向属性,分布式
partitions:变量:对应着RDD分布式数据实体中所有的数据分片
partitioner:方法:数据分片的分区规则,如按照hash或者分区
(2)纵向属性,容错性
dependencies:变量:生成RDD所需要的数据源,父RDD
compute:方法:封装了从父RDD到当前RDD的计算逻辑
