




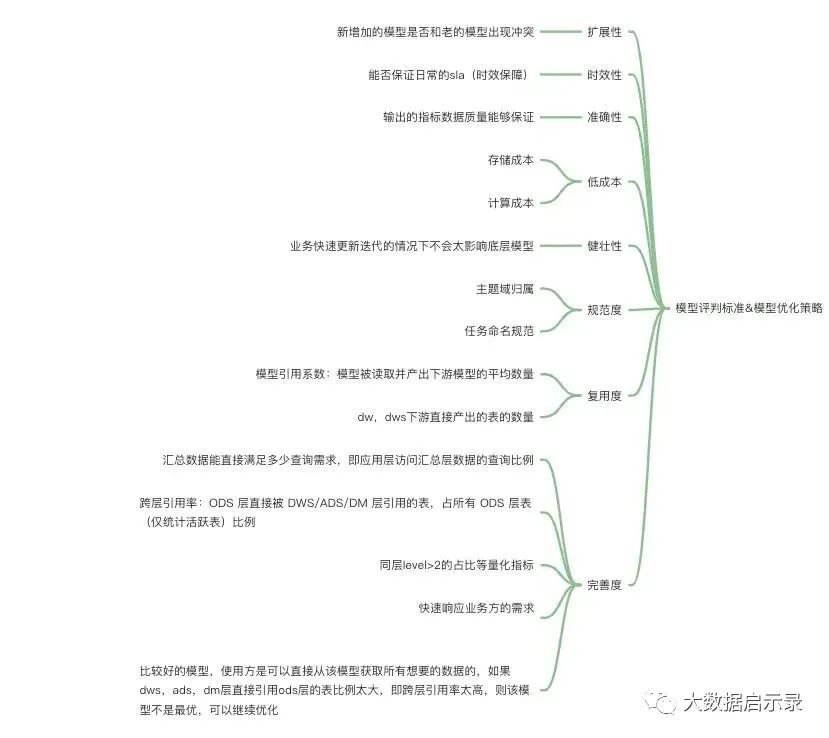
数仓模型是建设的目标,有以下评价规则:
(1)规范度衡量
采用表归类率。计算公式为“表归类率 = 有分层信息与主题域信息的表的数量占比”。数仓分层规范:公共逻辑下沉。出现相同逻辑的时候可以在dwd或者做个中间层收口,万一口径发生变化,只需要在最底层修改逻辑,上层只需要回溯验证数据即可,而不是说到处修改用到的地方任务命名规范:见名知义,遵循命名库表命名规范。
(2)完善度衡量
可以采用公共层的表引用率(ODS层的表直接被DWD层引用的表占所有ODS层活跃表的比例)、汇总层的查询比例(DWD ADS层的查询占所有查询的比例)来衡量。跨层依赖的占比;同层Level>2的占比;ods层被app层直接使用的占比等量化指标
(3)复用度衡量
主要采用公共层的模型调用热度(DWD层的数据模型被DWS ADS层调用并加工产出新模型的平均数量)来进行衡量。只有复用能力上来了,响应速度才能提上来,体现在下游依赖、调用次数、核心字段覆盖率等指标上;
(4) 健壮性
除了电商等已经耕耘多年的领域外,绝大多数业务模型,都会快速的变化,如何适应这种变化,就非常考验架构功底。
(5) 准确性/一致性
输出的指标数据质量能够保证;数据可回滚,进行验证。确保一些经常变化的维度可以回滚,比如:当下游每天产出指标的时候,突然今天的指标值和昨天的差异性很大,这个时候我们就要去回滚昨天的数据,看今天数据是否异常还是逻辑错误等等定义一致性指标、统一命名规范、统一业务含义、统一计算口径,专业的建模团队
(6)可扩展性
新增加的模型是否和老的模型出现冲突;
(7)稳定性
能否保证日常的sla(数据到岗时间);如何尽量减少任务运行失败
(8)时效性
响应速度:数据架构的主要场景包括:业务开发、数据产品、运营分析三大类,不论是那种场景,数据架构均应该在尽可能短的时间内响应需求;监控数仓任务的运行时长进行优化
(9)成本指标
避免烟囱式的重复建设,节约计算、存储、人力成本。不做无意义的分层复杂逻辑前置,降低业务方的使用门槛。通过冗余维度和事实表,进行公共计算逻辑下沉,明细与汇总共存等为业务提供灵活性
(1)数据质量保证(可参考前文)
(2)统一数仓规范
词根梳理评审指标评审及指标定义指标命名规范指标管理规范
(3)开发规范
清洗规范单位统一,比如金额单位统一为元字段类型统一注释补全空值用默认值或者中位数填充时间字段格式统一,如2020-10-16,2020/10/16,20201016统一格式为2020-10-16json数据解析枚举值统一过滤没有意义的数据逻辑规范表之间的关联关系,依赖与调用,sql检验
(4)建立/需求/模型评审机制
建立统一的需求评审机制,从需求承接时间、制定需求模板(业务背景、所需的数据指标等)等制定一套规范,严格把控需求质量,如果需求承接本身变得很混乱,例如需求不明确、需求没有统一管理,那么很可能会导致重复性的建设工作;模型评审主要评审模型设计的是否合理,表/字段命名是否规范、应该是全量表还是增量表、分层是否按照要求、公共指标应该放在dws层还是adm层等,保证模型的质量来避免以后出现的二义性。
(5)建立一致性维度
建立一致性维度,保证参与计算的数据来源一致,统一数据的计算口径。另外可以提前对数据进行交叉验证,即明细层与不同维度层数据进行交叉验证,确保数据的一致性。
(6)离线、实时交叉验证
计算逻辑无法对齐,其原因有二:一、实时、离线是两个不同的数据团队成员开发,其对业务的理解不同;二、离线逻辑本身相对比较复杂,可以做很多补偿逻辑,实时处理却相对比较简单; 数据源不一致,通常接入的数据源有日志与binlog,binlog基本都能保证一致,但是对于日志在一些场景不能做到完全一致,例如风控场景提供的点击日志提供下游使用,实时、离线反作弊模型差异导致风控过后的数据存在差异;
离线、实时技术栈对一致性的支持程度不同,离线通常都是批处理的调度模式,当出现异常情况,只需要重新调度直接进行分区覆盖即可,而实时处理本身对消息处理的顺序性有比较高的要求,另外加上端到端一致性实现复杂等等,在某些场景并不能保证与离线同等的一致性。
文章转载自大数据启示录,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
