




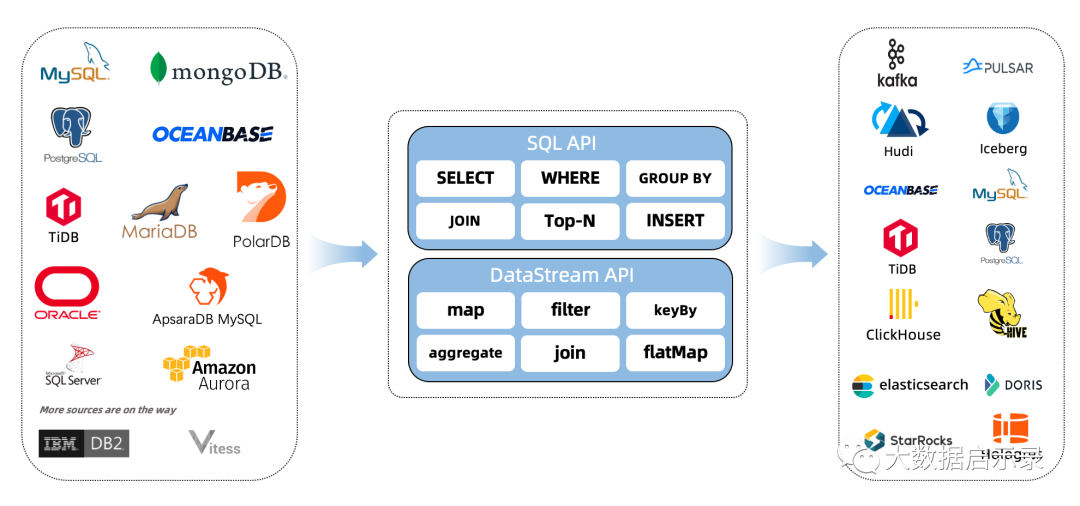
CDC Connectors for Apache Flink ®是一组用于Apache Flink ®的源连接器,使用变更数据捕获 (CDC) 从不同数据库获取变更。用于 Apache Flink ®的 CDC 连接器将 Debezium 集成为捕获数据更改的引擎。所以它可以充分发挥 Debezium 的能力。查看更多关于什么是Debezium的信息。
Connector | Database | Driver |
|---|---|---|
mongodb-cdc |
| MongoDB Driver: 4.3.1 |
mysql-cdc |
| JDBC Driver: 8.0.27 |
oceanbase-cdc |
| JDBC Driver: 5.7.4x |
oracle-cdc |
| Oracle Driver: 19.3.0.0 |
postgres-cdc |
| JDBC Driver: 42.2.12 |
sqlserver-cdc |
| JDBC Driver: 7.2.2.jre8 |
tidb-cdc |
| JDBC Driver: 8.0.27 |
支持的 Flink 版本
| Flink CDC Version | Flink Version |
| 1.0.0 | 1.11.* |
| 1.1.0 | 1.11.* |
| 1.2.0 | 1.12.* |
| 1.3.0 | 1.12.* |
| 1.4.0 | 1.13.* |
| 2.0.* | 1.13.* |
| 2.1.* | 1.13.* |
| 2.2.* | 1.13., 1.14.* |
flink 基本库表同步,千库千表同步功能此篇不做赘述,可以参看前几篇flink cdc 文章。本篇主要以cdc 动态监听新增表,表scheam变更的场景为案例。
注意几个参数:
获取dml query配置properties.setProperty("include.query","true");添加新表扫描.scanNewlyAddedTableEnabled(true) eanbel scan the newly added tables fature// output the schema changes as well 开启表结构变更支持.includeSchemaChanges(true)
demo
import com.ververica.cdc.connectors.mysql.source.MySqlSource;import com.xsy.wc.model.OperateSqlModel;import org.apache.flink.api.common.eventtime.WatermarkStrategy;import org.apache.flink.api.common.restartstrategy.RestartStrategies;import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.CheckpointConfig;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Properties;/*** author: lkn Date: 2022/4/22 ProjectName: flinkbase Version: 1.0*/public class MysqlStream {public static StreamExecutionEnvironment prepareEnvronment(){获取运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();设置并行度env.setParallelism(1);开启检查点 Flink-CDC将读取binlog的位置信息以状态的方式保存在CK,如果想要做到断点续传,需要从Checkpoint或者Savepoint启动程序2.1 开启Checkpoint,每隔5秒钟做一次CK ,并指定CK的一致性语义env.enableCheckpointing(5000L, CheckpointingMode.EXACTLY_ONCE);2.2 设置超时时间为1分钟env.getCheckpointConfig().setCheckpointTimeout(60000);2.3 指定从CK自动重启策略env.setRestartStrategy(RestartStrategies.fixedDelayRestart(2, 2000L));本次CheckpointingMode模式 精确一次 即exactly-onceenv.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);同一时间只允许进行一个检查点env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);2.4 设置任务关闭的时候保留最后一次CK数据env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);2.5 设置状态后端env.setStateBackend(new HashMapStateBackend());env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop52:9820/flinkCDC/chk-17");//2.6 设置访问HDFS的用户名System.setProperty("HADOOP_USER_NAME", "flowreplay");return env;}public static DataStreamSource <OperateSqlModel> buildStreamSource(StreamExecutionEnvironment env){Properties properties = new Properties();// debezium 配置properties.setProperty("include.query","true");MySqlSource<OperateSqlModel> mySqlSource = MySqlSource.<OperateSqlModel>builder().hostname("127.0.0.1").port(3306).scanNewlyAddedTableEnabled(true) // eanbel scan the newly added tables fature.databaseList("xsy_flowreplay") // set captured database, If you need to synchronize the whole database, Please set tableList to ".*"..tableList("xsy_flowreplay.gen_table_copy1") // set captured table// .tableList("xsy_flowreplay.*") // set captured table.username("root").password("root").deserializer(new FlinkCdcDeserializationSchema()) // converts SourceRecord to JSON String.includeSchemaChanges(true).debeziumProperties(properties).build();// 读取数据封装流DataStreamSource <OperateSqlModel> mySQLDS = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source").setParallelism(1);mySQLDS.print(">>>").setParallelism(1);// 对流进行处理 包括过滤非法格式,并转换成json 字符串,发送给下游的kafkareturn mySQLDS;}/*** 执行命令* bin/flink run \* -t yarn-per-job \* -d \* -p 5 \* -Drest.flamegraph.enabled=true \* -Dyarn.application.queue=test \* -Djobmanager.memory.process.size=1024mb \* -Dtaskmanager.memory.process.size=2048mb \* -Dtaskmanager.numberOfTaskSlots=2 \* -Dmetrics.latency.interval=30000 \* -c com.neo.flowreplay.data.sync.Mysqlcdc \* /opt/module/flink-1.13.1/myjar/FlowReplayDbSync-1.0-SNAPSHOT.jar* @param args*/public static void main(String[] args) throws Exception {// 准备执行环境StreamExecutionEnvironment env= prepareEnvronment();DataStreamSource<OperateSqlModel> sourceStream = buildStreamSource(env);// sourceStream.addSink(new MyMysqlSink()).setParallelism(1);env.execute("mysql test");}}
序列化
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;import com.xsy.wc.model.OperateSqlModel;import io.debezium.data.Envelope;import org.apache.flink.api.common.typeinfo.TypeInformation;import org.apache.flink.util.Collector;import org.apache.kafka.connect.data.Struct;import org.apache.kafka.connect.source.SourceRecord;/*flink 监听到的数据库变化数据的反序列化器*/public class FlinkCdcDeserializationSchema implements DebeziumDeserializationSchema <OperateSqlModel> {@Overridepublic void deserialize(SourceRecord sourceRecord, Collector <OperateSqlModel> collector) throws Exception {// FlinkCDC采集数据格式try{Struct valueStruct = (Struct) sourceRecord.value();Struct sourceStrut = valueStruct.getStruct("source");//获取数据库的名称String database = sourceStrut.getString("db");//获取表名String table = sourceStrut.getString("table");// 获取完整sqlString dml = sourceStrut.getString("query");//获取类型String type = Envelope.operationFor(sourceRecord).toString().toLowerCase();//向下游传递数据collector.collect(new OperateSqlModel(type,dml));}catch (Exception e){e.printStackTrace();}}@Overridepublic TypeInformation <OperateSqlModel> getProducedType() {return TypeInformation.of(OperateSqlModel.class);}}
如果想要sink到kafka 多topic ,该怎么办呢?答案很简单,只需要实现KafaDeserializationSchema类重写deserialize方法即可
DataStream<String> stream = ...KafkaSink<String> sink = KafkaSink.<String>builder()// .setBootstrapServers(brokers).setRecordSerializer(KafkaRecordSerializationSchema.builder()// 自定义 topic.setTopicSelector(new TopicSelector<Object>() {@Overridepublic String apply(Object o) {// 此处写入逻辑即可return null;}})// 此处自定义分区.setPartitioner(new FlinkKafkaPartitioner<Object>() {@Overridepublic int partition(Object o, byte[] bytes, byte[] bytes1, String s, int[] ints) {// 此处写入逻辑即可return 0;}}).setValueSerializationSchema(new SimpleStringSchema()).build()).setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE).setTransactionalIdPrefix("t_0001").build();stream.sinkTo(sink);
aws 的dms 数据迁移工具,相较于flink CDC的同步方式区别在于:
支持的都是aws 服务套件,支持的常见源端有:
Oracle ,SQL Server ,Azure SQL ,Azure SQL ,Google Cloud MySQL ,PostgreSQL ,MySQL ,SAP ASE ,MongoDB ,Amazon DocumentDB ,Amazon S3 ,IBM Db2 LUW
支持的常见目标端有:
Oracle ,SQL Server ,PostgreSQL ,MySQL ,Amazon Redshift ,SAP ASE ,Amazon S3 ,Amazon DynamoDB ,Amazon Kinesis Data Streams ,Apache Kafka ,OpenSearch ,Amazon DocumentDB ,Amazon Neptune ,Redis
相较于其他同步工具的有点在于:只需要通过配置文件,就可以实现库表的同步,字段筛选,字段添加,类型转换,sql 处理(etl),可以支持动态schema 变更,源端字段增减,终端相应感知变化。
常见配置模版:
{"rules": [{"rule-type": "selection","rule-id": "894683742","rule-name": "894683742","object-locator": {"schema-name": "market11","table-name": "t_nft_token"},"rule-action": "include"},{"rule-type": "selection","rule-id": "894683749","rule-name": "894683749","object-locator": {"schema-name": "assets","table-name": "token_tx_flow"},"rule-action": "include"},// 所有表中的modify_time改变类型为datetime{"rule-type": "transformation","rule-id": "2","rule-name": "2","rule-action": "change-data-type","rule-target": "column","object-locator": {"schema-name": "%","table-name": "%","column-name": "modify_time"},"data-type": {"type": "datetime"}},// 所有表中添加整型的hr,dt字段{"rule-type": "transformation","rule-id": "3","rule-name": "3","rule-action": "add-column","rule-target": "column","object-locator": {"schema-name": "%","table-name": "%"},"value": "hr","expression": "strftime('%H',$create_time)","data-type": {"type": "int4"}},{"rule-type": "transformation","rule-id": "4","rule-name": "4","rule-action": "add-column","rule-target": "column","object-locator": {"schema-name": "%","table-name": "%"},"value": "dt","expression": "date ($create_time)","data-type": {"type": "date","precision": 6}}]}
详细语法参见:https://docs.aws.amazon.com/zh_cn/zh_cn/dms/latest/userguide/CHAP_Tasks.CustomizingTasks.TableMapping.html下的Table mapping (表映射)
TIS快速为您构建企业级实时数仓库服务,基于批(DataX)流(Flink-CDC)一体数据中台,提供简单易用的操作界面,降低用户实施各端(MySQL、PostgreSQL、Oracle、ElasticSearch、ClickHouse、Doris等) 之间数据同步的实施门槛,缩短任务配置时间,避免配置过程中出错,使数据同步变得简单、有趣且容易上手 详细介绍
MySQL 增量同步Datetime类型binlog接收到的时间 比实际UTC时间快8小时,导致下游StarRocks中的时间和上游MySQL的DateTime时间不一致 #89
数据库名支持中划线 #86
Oracle数据库可以选择系统授权给的其他用户名下的表 #85
在配置DATAX oracle reader 时,避免大量重复字段出现 #81
执行TIS 批量任务失败,但是最终任务状态显示失败 #79
Flink实时同步支持阿里云ES同步,填入的用户名、密码可以生效 #76
重构TIS启动脚本,优化TIS启动时间 #65
TIS启动端口可配置 #62
架构
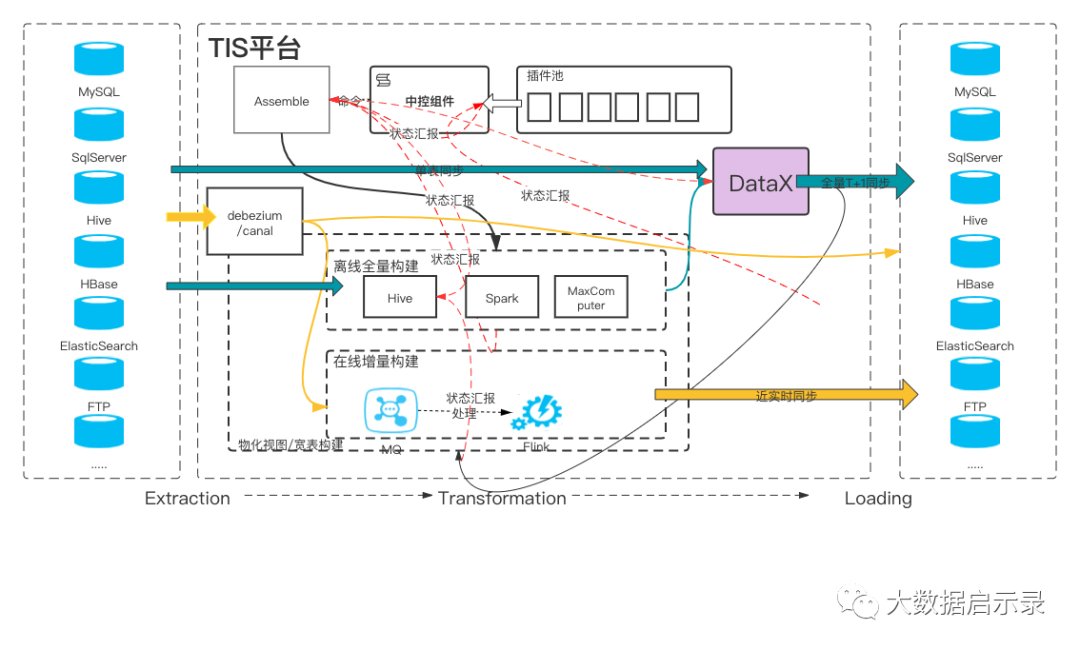
没啥可说的,配置化操作,参见:https://github.com/qlangtech/tis
下载及学习,详见官方文档:https://www.clougence.com/
CloudCanal 是一款数据迁移同步工具,帮助企业快速构建高质量数据流通通道,产品包含 SaaS 模式和私有输出专享模式。开发团队核心成员来自大厂,具备数据库内核、大规模分布式系统、云产品构建背景,懂数据库,懂分布式,懂云产品商业和服务模式。
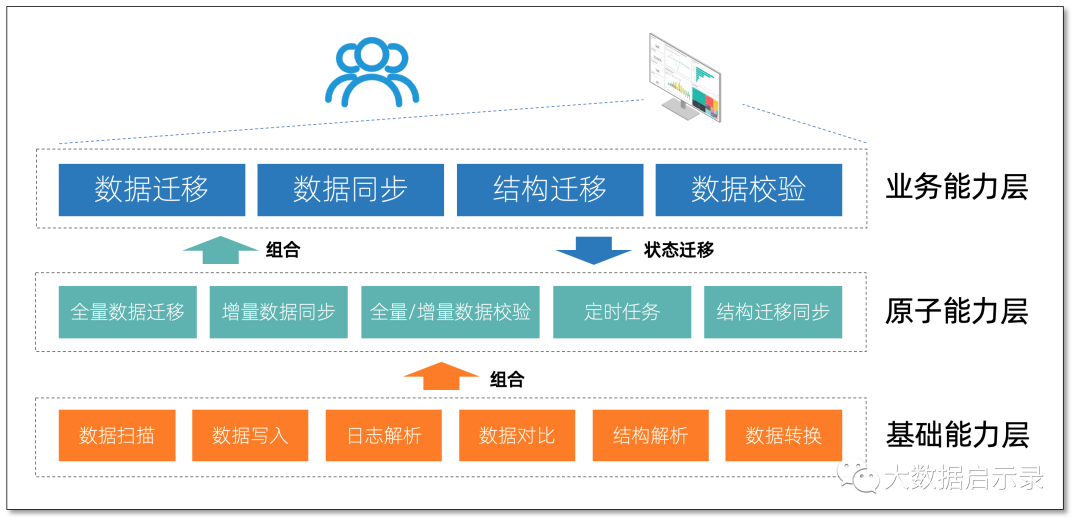
数据迁移
将指定数据源数据全量搬迁到目标数据源,支持多种数据源,具备断点续传、顺序分页扫描、并行扫描、批量写入、并行写入、数据条件过滤等特点,对源端数据源影响小且性能好,同时满足数据轻度处理需求。
数据迁移 可选搭配 结构迁移、迁移后指定时长数据同步、数据校验,满足可能的业务平滑切换需求。
数据同步
数据同步 通过消费源端数据源增量操作日志,准实时在对端数据源重放,以达到数据同步目的,支持多种数据源,具备断点续传、DDL 同步、边同步边校验、对端事务保持、高性能对端写入、数据条件过滤等特点。
数据同步 可选搭配 结构迁移、数据初始化(全量迁移)、单次或定时数据全量校验,既便利,又能满足业务长周期数据同步对于数据质量的要求。
结构迁移
结构迁移 帮助用户快速镜像指定数据源结构,具备类型转换、数据库方言转换、命名映射等特点,可独立使用,也可作为 数据迁移 或 数据同步 准备步骤,灵活满足新数据构建需求。
数据校验
数据校验 让数据质量可衡量,可单独使用,也可配合 数据迁移 或 数据同步 使用,具备全量校验、增量校验、采样率、定时执行、校验数据条件过滤等特性,满足用户灵活的数据质量验证需求。
使用场景
云上云下、多云数据生态构建
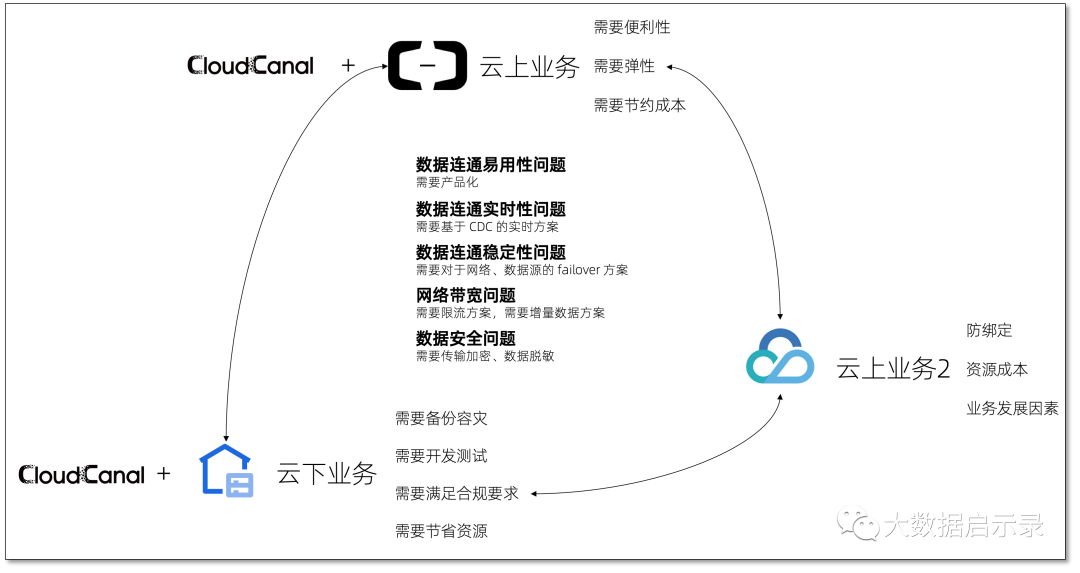
不同类型业务、开发和生产、主数据和数仓等不同维度数据放置于多云或云上云下环境,以满足高弹性、高性价比、可控性、安全合规等需求。CloudCanal 安全通信、稳定性、主流数据源支撑、全面的功能很好地满足此场景要求。
实时数仓构建
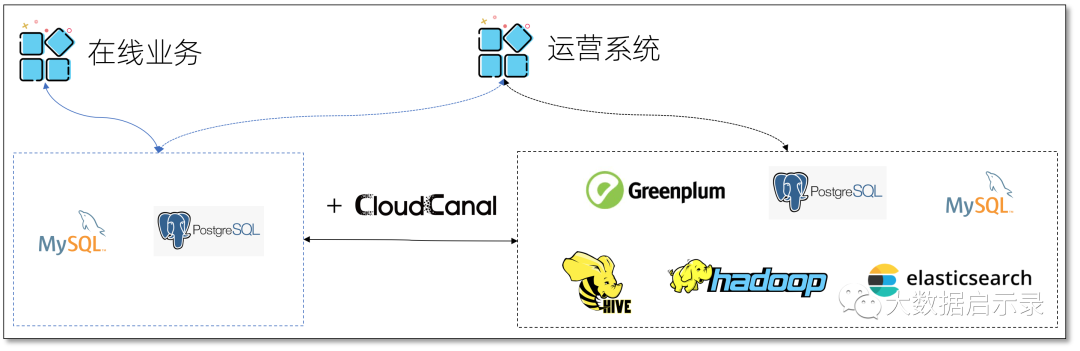
数据实时多维删选、聚合、链接在业务场景中越来越多,对于'快'的诉求永不停歇,找到一个强大的实时数仓同时,如何让主数据流畅、实时到达也成为了一个关键需求,CloudCanal 主流数仓支撑很好满足此类场景需求。
周边业务异步化
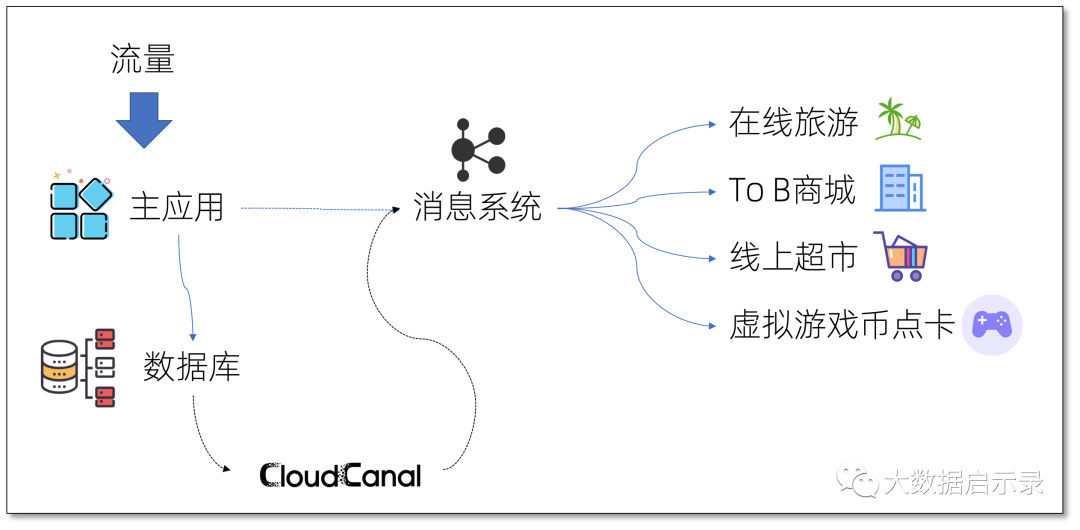
高并发业务的其中一个重要优化即同步操作 只保留最关键操作 ,其他操作皆 异步化 ,通过 消息订阅模式 补完流程,但写消息中间件有很多细节需要注意,包括如何保持事务,如何规避消息中间件不可用等问题, CloudCanal 通过 链接数据增量变更 和 消息中间件,主业务不需要关注消息中间件即可完成业务的异步化。
数据按需抽取同步
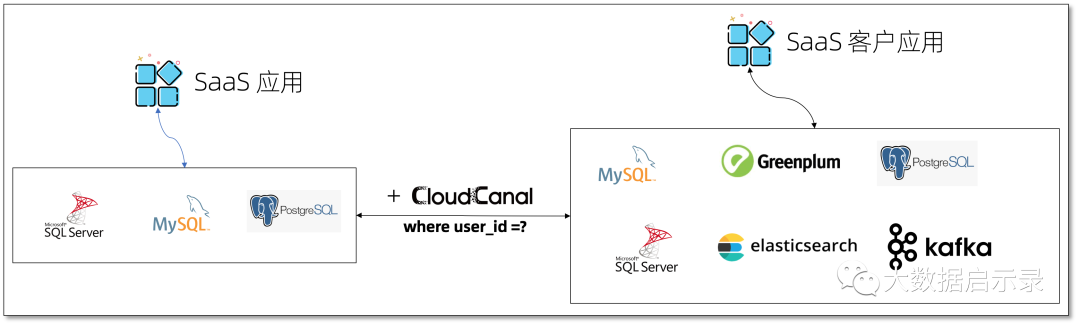
对于业务型 SaaS 平台,快速抽取同步指定用户数据构建专享服务是一项高价值业务,CloudCanal 数据条件过滤功能让这个工作顺畅进行。
数据集散
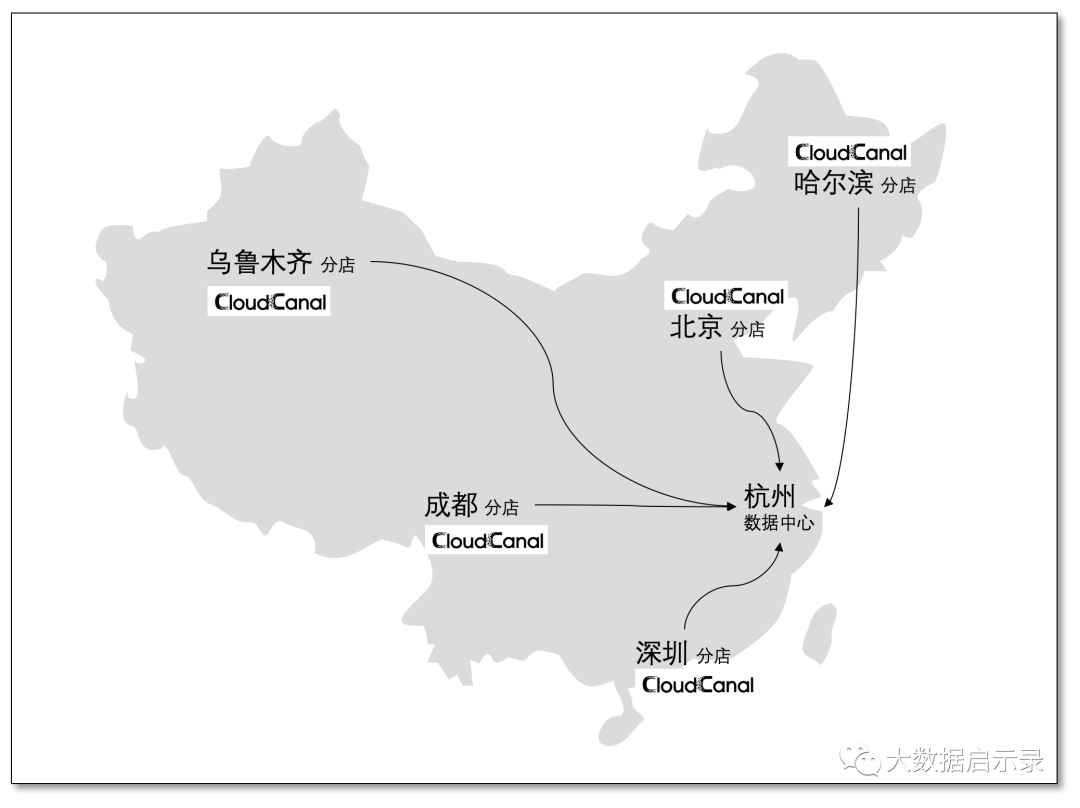
分散于各地的门店、网点产生订单等行为数据,迁移同步到云数据库、云数仓,再将数据归档到云上或自建大数据系统。完整的数据集散生态构建,CloudCanal 跨网络部署、容灾重试策略、主流数据库支撑很好匹配此场景诉求。
功能介绍:
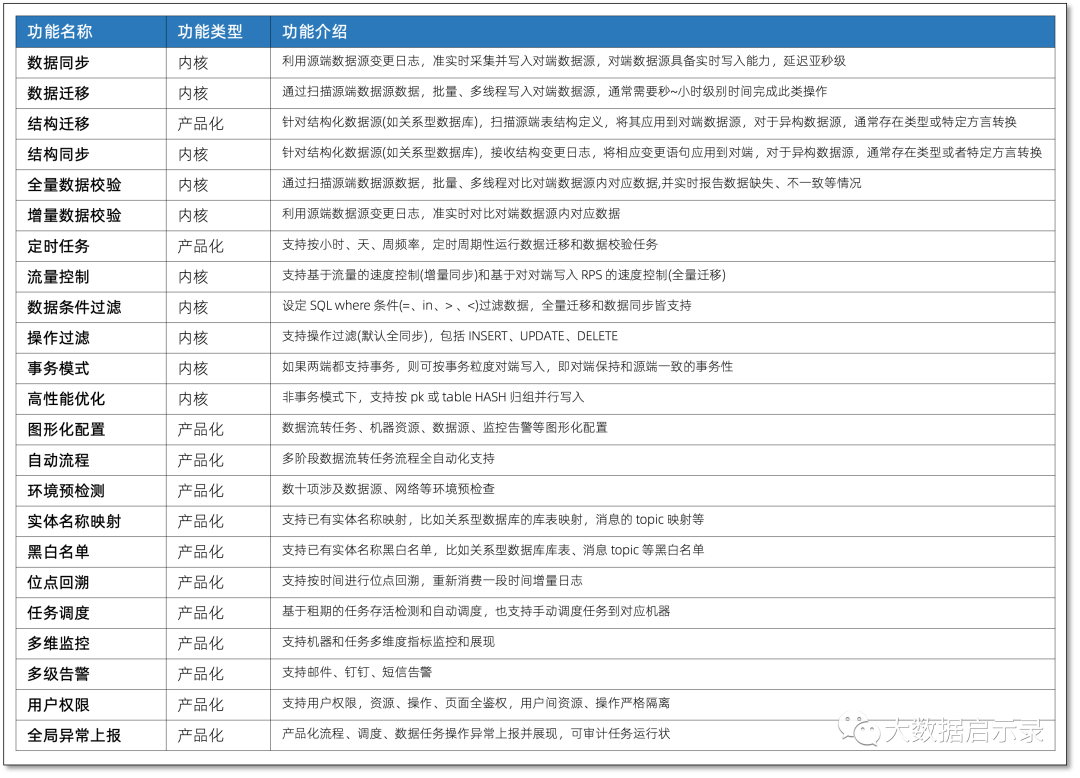
支持的源端:
MySQL
,Oracle
,PostgreSQL
,SQLServer
,RDS for MySQL
,ElasticSearch
,Hive
,Kafka
,RocketMQ
,RDS for PG
,ADB for PG
,Greenplum
,RabbitMQ
,TiDB
,PolarDB
,ClickHouse
,PolarDB-X
,Redis
,Kudu
,MongoDB
,StarRocks
,OceanBase
