




今天下午2点半,接到故障反馈

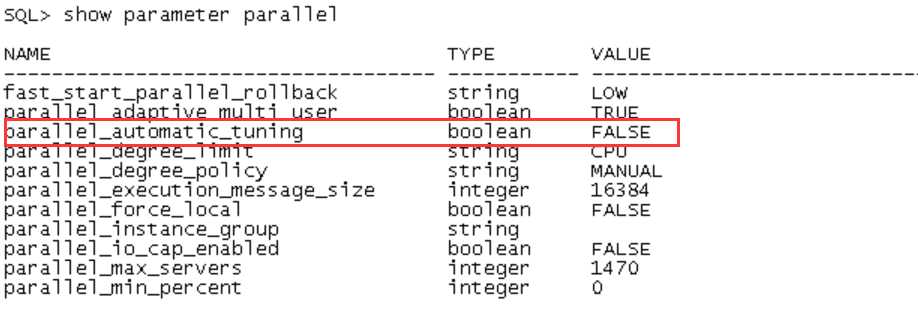
我登陆数据库一看,有大量的异常等待事件,其中latch: parallel query alloc buffer尤甚。


第一次遇见这个等待事件,从字面上理解,是并行进程分配buffer的相关latch。 并行进程在获取内存时,首先获取该latch,在随后的内存分配过程中,会一直持有该latch,直到获取到满足需要的内存。
我想到了2个可以解决问题的方法:
1.减少parallel_max_servers,并重启数据库。
2.增大内存。
检查了主机资源,CPU很空闲,内存很充足,我选择了第2个方法。
但是,并行进程使用的内存,是哪里的内存呢?在我的印象中,是大池,没有大池,则在共享池分配。我记得DSI中说过:有当PARALLEL_AUTOMATIC_TUNING设置为TRUE时,并行执行才会从大池中分配buffer。在我的故障中,这个参数是FALSE。
难道是在共享池中?可是,如果共享池已经不足, 不是应该出现ORA-4031吗?
故障数据库采用自动SGA内存管理:

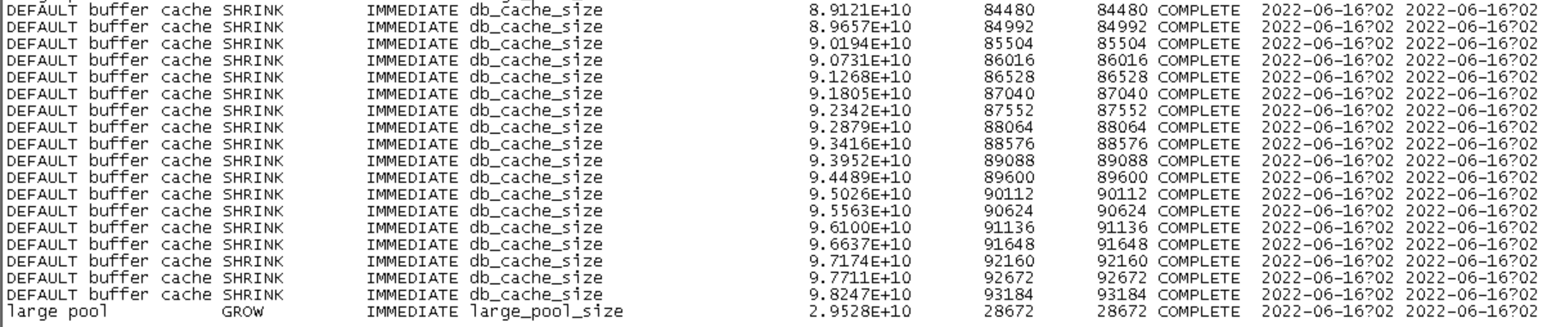
查看v$sga_resize_ops,下午2点时的时候(时间格式我没有用24小时制) ,所有的可动态调整的组件,几乎都在收缩,而唯独large pool在grow。
 此外, v$sgainfo显示,大池占用了大量的SGA内存
此外, v$sgainfo显示,大池占用了大量的SGA内存
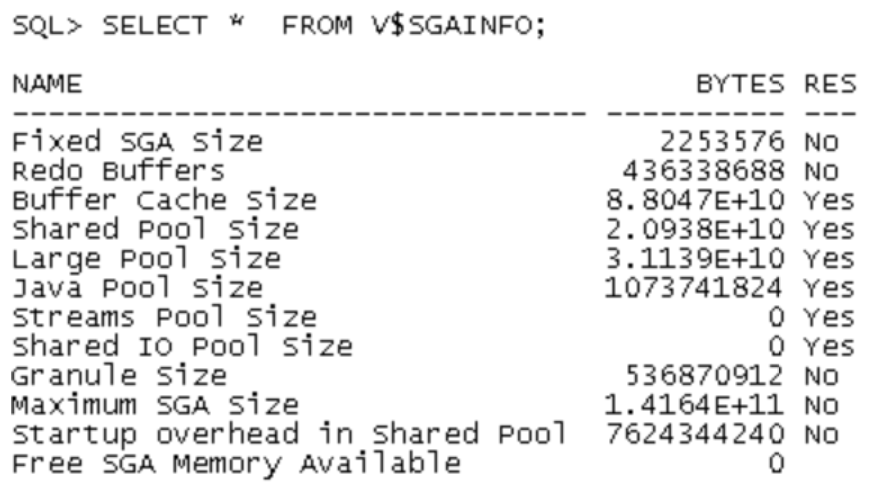
这坚定了我的推测:并行进程需要的buffer在大池而非共享池。
这个参数是resizable的,但是因为SGA_TARGET等于SGA_MAX_SIZE的大小,所以手动增加large pool的想法已经不现实了。(比较可惜,修改SGA大小要重启数据库,我比较希望在所有的环境不变的情况下,测试大池的增大能不能解决该故障。。)
征得客户同意后,我修改了SGA大小,并重启数据库:
alter system set sga_target=200G scope=spfile;
alter system set sga_max_size=240G scope=spfile;--预留40用于组件增长。没有预留的可用空间,组件增长要等待
修改完重启数据库, over。
