




C++ atomics
在文章开始之前,首先来关注一些无锁编程这个概念(lock free——不使用锁来保持代码同步)。一般人在使用无锁编程或者了解这个概念之前,会先入为主地认为无锁编程性能更快,相对使用锁来同步拥有更好的运行速度。
实际上,无论是lock free还是更严格的wait free都没有直接跟运行速度有直接关系,他们关联的是“steps”,但在程序运行过程中“step”的运行时间不一定是一样的。无锁编程的优势在于通过减少阻塞和等待来提高并发的可能性,消除race condition、死锁等潜在危机。因此在使用无锁编程之前应该先测试程序,观察代码的算法逻辑是否有问题。
接下来我们开始了解C++的原子操作。
何谓原子操作
原子操作是一种以单个事务来执行的操作,这是一个“不可再分且不可并行的”操作,其他线程只能看到操作完成前或者完成后的资源状态,不存在中间状态可视。
从底层来看,原子操作是一些硬件指令,其原子性是由硬件保证的,C++11对原子操作抽象出统一的接口,避免使用时嵌入平台相关的代码来支持跨平台使用。
先来看看如果多线程中没有原子操作会发生什么情况:
int x = 0;// ===============// Thread 1{int tmp = x; // 0++tmp; // 1x = tmp; // 1}// Thread 2{int tmp = x; // 0++tmp; // 1x = tmp; // 1!!! What!!!}
这是一个很典型的Read-modify-write的递增场景,多线程环境下就会出现data race。为什么会这样,以一个简易的计算机架构图来举例,这里存在三级缓存,变量在内存中初始化好为0,由于这里没有同步机制,每个CPU都从主存中将变量取出来(此时变量都是0),在寄存器中进行递增,最后将递增后的值1写回内存。
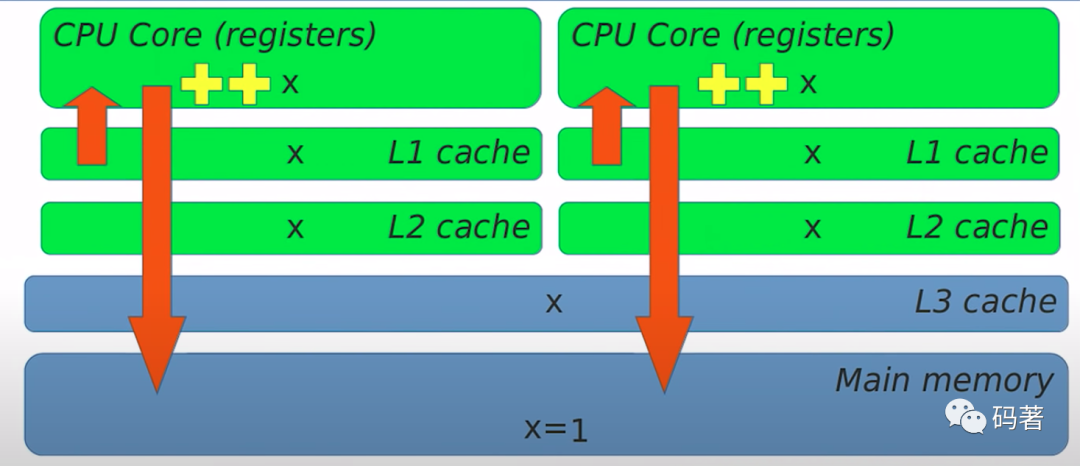
那么我们怎么在C++中进行数据共享呢?在C++11之前是没有标准的线程库的,在C++11之后引入了std::atomic模版类来提供原子操作。一个简单例子:
std::atomic<int> x(0); // Not support std::atomic<int> x = 0++x; // now atomic operation
std::atomic的使用
std::atomic是一个模版,那么哪些类型可以实例化该模版呢?按照标准的说法,需要是Trivially Copyable的类型,简单来说就是满足三个条件:
连续的内存;
拷贝对象意味着按bit拷贝(memcpy);
没有虚函数;
用代码来表达则是自定义结构满足下面5个条件:
std::is_trivially_copyable<T>::valuestd::is_copy_constructible<T>::valuestd::is_move_constructible<T>::valuestd::is_copy_assignable<T>::valuestd::is_move_assignable<T>::value
那么对于一个合法的std::atomic<T> 类型来说,它能进行哪些操作?一个是assignment,则读写操作;另一个则是特定的原子操作和跟类型T相关的其他操作。下面几种操作要么编译失败、要么是非原子:
std::atomic<int> x{0};x *= 2; // compile errorx = x + 1; // Not atomic: Atomic read followed by atomic writex = x * 2; // Not atomic: Atomic read followed by atomic write
还有一个就是原子自增不支持浮点数。其他的原子操作包括CAS、exchange等等;
std::atomic<T> x;T y = x.load(); // same sa T y = xx.store(y); // same as x = yT z = x.exchange(y); // Atomically: z = x; x = y;// if x == y, make x=z and return true// Otherwise, set y=x and return false// 还有一个compare_exchange_week,x == y也可能会失败,主要是因为某些平台会对锁有类似超时释放的操作,满足其高效调度bool success = x.compare_exchange_strong(y, z);
这里重点看一下CAS的使用,CAS在大多数无锁算法中都有应用,除了原子自增外,CAS还支持递增浮点数,进行乘法运算:
std::atomic<int> x{0};int x0 = x;while (!x.compare_exchange_strong(x0, x0+1)) {}while (!x.compare_exchange_strong(x0, x0*2)) {}// fetch_xxx() == some operatorsstd::atomic<int> x{0};x.fetch_add(y); // same as x += yint z = x.fetch_add(y); // same as z = (x += y) - y;
std::atomic与无锁的关系
这里有一个关键的信息:std::atomic并不意味着一定是无锁的;首先来看下面的代码:
long x; // lock freestruct A { long x; }; // lock freestruct B { long x; long y; }; // run-time and platfrom dependent. x86 is lock freestruct C { long x; long y; long z; }; // > 16 bytes. not lock freestruct D { long x; int y; }; // alignment 16 bytes. lock freestruct E { long x; int y; }; // 12 bytes. not lock free
判断atomic是否无锁可以通过一个成员函数std::atomic<T>::is_lock_free(),这是一个运行时的判断(C++17提供了编译时判断constexpr is_always_lock_free()),之所以会出现无锁不确定的情况主要是因为对齐alignment。
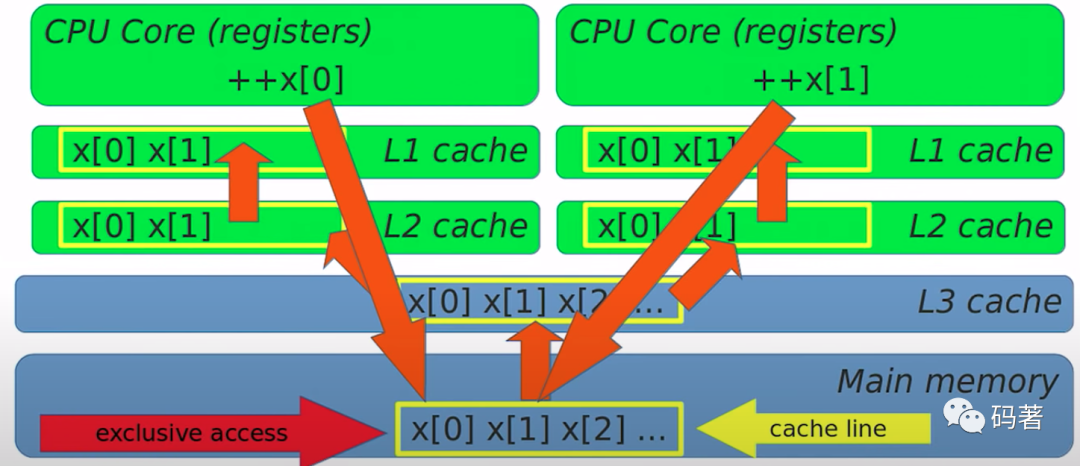
假设atomic是无锁的,但也有可能出现两个atomic变量互相等待的情况,假设存在这样的场景,两个atomic变量:
std::atomic<int> x[N];// thread 1++x[0];// thread 2++x[1];
这种情况下就会出现两个atomic变量互相等待的可能性,主要是因为这两个操作都是在同一个cache line,都从主存到CPU来回写入,因为两个CPU可能互斥访问同一个cache line,这就是所谓的false sharing。一个提高性能解决这个问题的方式是将每个线程的数据对齐到充满整个cache line。(NUMA机器上,可能是整个page)
memory barrier
memory barrier控制着某个CPU对内存的修改被另一个CPU可见的方式,这是一个对所有CPU的全局控制。这是通过硬件实现,确定指令的特定操作顺序。简单来说,就是CPU在执行指令的时候不一定按照编写顺序来执行,从而挖掘更多并行能力。
如果仔细观察std::atomic相关操作的参数,会发现其还接受一个memory_order的枚举作为参数。
typedef enum memory_order {memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_release,memory_order_acq_rel,memory_order_seq_cst} memory_order;
memory_order_relaxed:不对执行顺序做任何保证,即该原子操作指令可以任由编译器重排或者CPU乱序执行;
memory_order_acquire:当前线程里,所有在该原子操作之后的读操作,都不能重排到该原子操作指令之前执行。原子操作指令先读;
memory_order_release:当前线程里,所有在该原子操作之前的写操作,都不能重排到该原子操作指令之后执行。原子操作最后写;
int Thread1(int){int t=1;a.store(t,memory_order_relaxed);b.store(2,memory_order_release); // a必须在b之前完成写入}int Thread2(int){while(b.load(memory_order_acquire)!=2); // b必须在a之前读cout<<a.load(memory_order_relaxed)<<endl;//输出1.}
memory_order_acq_rel:包含memory_order_acquire和memory_order_release两个标志;
memory_order_seq_cst:默认标志。顺序一致,确保代码在线程中的执行顺序与顺序看到的代码顺序一致,禁止重排指令和乱序执行;
改变memory order参数,在一定程度上可能会提高程序的性能,从代码中表达出程序员的意图。
C++的atomic操作在一定条件下能很好提高程序的性能,并且也提高了易用性,但也存在很多容易踩坑的地方,因此在使用前仍然需要做详细的设计。使用atomic的时机也需要细细斟酌,对于不适用的地方使用无锁或者atomic操作可能收效甚微。
https://www.infoq.com/news/2014/10/cpp-lock-free-programming/
https://www.youtube.com/watch?v=ZQFzMfHIxng
https://en.cppreference.com/w/cpp/atomic/atomic关注我,一起学点不一样的知识

