




背景
Least Frequently Used(下文简称LFU)是一种著名的缓存置换算法,用来管理计算机中的缓存使用。
原理
LFU的基本思路是,记录item的访问次数,一旦缓存已满,则需要频率最低的item。这是一种locality的考虑,则在一定周期内访问次数最少的item,未来也大概率不会被访问。
最简单的实现方法就是,为缓存中的每个item分配一个计数器,每次引用该item的时候(即调用put或者get),计数器加一(item不在的时候直接设为1),当缓存达到预设容量的时候,将计数器最小的那个item逐出。
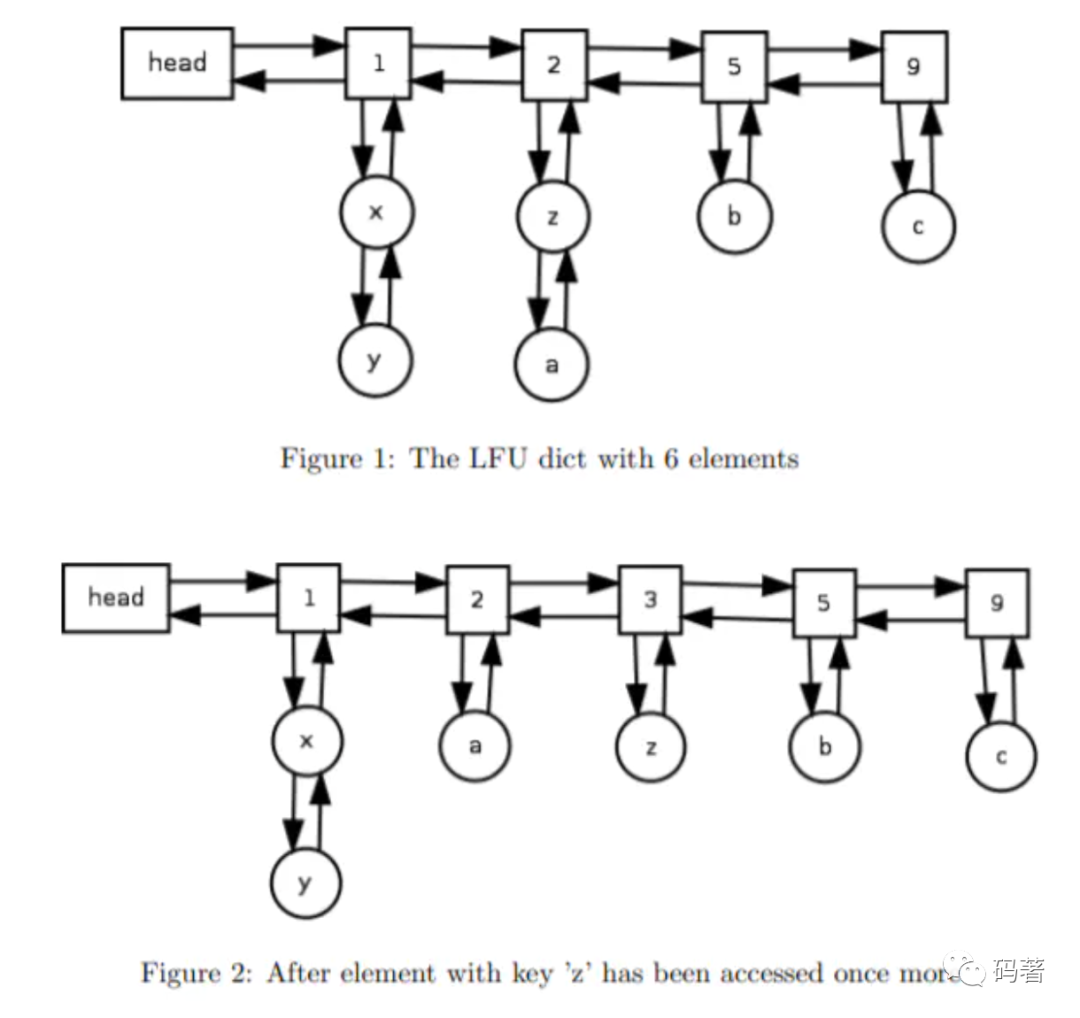
具体的实现方案也有几种,一种是双链表+哈希表的方式;另一种则是双哈希表的方式;双哈希表的方式来源论文《An O(1) algorithm for implementing the LFU cache eviction scheme》[1],能将get和put的时间复杂度降低到O(1)。第一个哈希表以频率为索引,value则是一个双链表。第二个哈希表则是key为索引,value是链表某一项的内存地址。
下图是论文原图,插入新item后,链表的变化情况。
LFU的缺陷与优化
先来说说缺陷,LFU本身的机制强依赖频率统计,因此可能带来两个问题:一是前期的热点数据一直存留在内存中,考虑这样一个场景,一个热点item短时间内被重复引用,但后续长期不被访问,由于前面的访问量导致计数器剧增,成为后续一直保留的“热点”数据。第二个问题是新加入item的抖动,由于刚加入的item其对应的计数较小,刚进入缓存的item可能很快就会被删除。
一些优化思路
针对LFU存在的问题,业界已经有不少的理论以及落地产品来对LFU进行优化了。主要是两点,一个是对缓存中的item实施aging机制,另一种则是限制采样近w次访问的窗口机制;
1. WLFU
WLFU即window LFU[2],这是一种比较经典的LFU改进算法。WLFU的策略比较简单:
WLFU只缓存近W次访问的请求;
缓存的置换依赖于LFU算法,即对W大小的窗口进行置换;
如果若干个item具有相同的频率,则通过LRU策略来进行选择;
WLFU只需要记录一部分的访问记录,因此内存消耗和排序消耗都更低,命中率也更高,有效地避免了缓存污染的问题。但需要注意的是,窗口大小跟缓存大小不是一个东西,一般的做法是item更新的时候需要重新计算窗口内的历史记录访问次数。
2. TinyLFU
TinyLFU[3]则是另一种变种,TinyLFU的主要考虑点是如何在不保存每个item访问频率的情况下,有效地近似计算访问次数。另一个则是如何在维护历史统计数据的同时,减少内存的损耗。其基本结构如下:
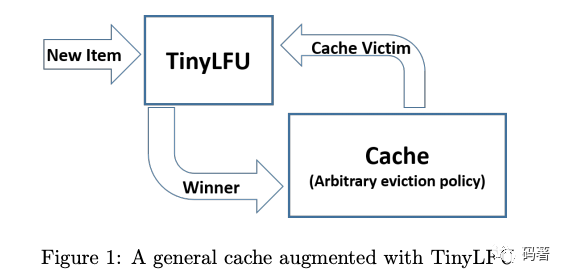
简单来说,就是当有新数据插入的时候,逐出策略选定一个候选的淘汰item,由tinyLFU决定是否使用新的数据替代待淘汰的item。
这篇论文最有趣的地方在于,使用了一个计数的布隆过滤器CM-Sketch,插入新item的时候,不再是做标记位,而是增加对应索引的计数。其主要提供两个操作:
Estimate:通过计算key的多个hash值,以此作为索引,计算多个索引对应值的最小值;
Add:通过计算key的多个hash值,以此作为索引,增加其中数值最小的值;
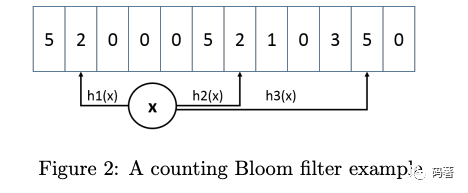
同样为了解决缓存污染的问题,保持新鲜度,CM-Sketch通过reset机制将原有的统计信息减半。
至于减少内存的优化,则是集中在两个方面:一是可以利用bit来减小CM-Sketch的counter尺寸,即每个counter可以用log(W)位来表示。另一方面则是引入一个Doorkeeper来应对长尾流量,其实这是一个在CM-Sketch前面的布隆过滤器,只有在Doorkeeper的item才能加到后面的结构中,计算的时候则是将在Doorkeeper的item加一,reset则需要清空Doorkeeper。
W-TinyLRU则是一款叫Caffeine的缓存组件的开源实现,通过LRU和LFU的结合,有效地应对突发的流量。其整体结构则是在TinyLFU前面加了一个只占1%左右流量的LRU。

3. Redis LFU实现
redis4.0之后增加了一种新的逐出策略LFU,其设计思路与传统LFU不大一样,并没有维护全部的统计信息,也不是每次访问请求就对item加一。
在redis中每个对象都有一个24bit的空间来记录LRU/LFU信息,当被用做LFU时,则高16bit记录访问时间(分钟),低8bit记录访问频率(计数器)。
redis LFU的计数器与传统的不一样,并不是线性增长,而是跟比特币生成来取,基于概率来实现,源码如下:
uint8_t LFULogIncr(uint8_t counter) {if (counter == 255) return 255;double r = (double)rand()/RAND_MAX;double baseval = counter - LFU_INIT_VAL;if (baseval < 0) baseval = 0;double p = 1.0/(baseval*server.lfu_log_factor+1);if (r < p) counter++;return counter;}
这段源码核心在于概率p的计算
1/((counter-LFU_INIT_VAL)*server.lfu_log_factor+1)
其中LFU_INIT_VAL为5,随着counter的增大,p机会越小,即计数器增加的概率越小,并且最终会收敛到255这个最大值。
前文也讲过,LFU的缺陷需要依赖aging和采样来解决,redis也一样,提供了一个衰减因子server.lfu_decay_time。具体aging方法则是:
unsigned long LFUDecrAndReturn(robj *o) {unsigned long ldt = o->lru >> 8;unsigned long counter = o->lru & 255;unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) server.lfu_decay_time : 0;if (num_periods)counter = (num_periods > counter) ? 0 : counter - num_periods;return counter;}
简单来说,当server.lfu_decay_time为1时,每隔N分钟就递减N。至于选择哪些key进行计数器递减,则是随机选择的。
另外,为了避免新加入的key由于访问次数过小而被马上淘汰,新key访问次数初始化为5。
总结
置换算法是缓存组件中最值得重视的策略,在计算机领域是不可替代的。LFU算法凭借在命中率方面更好的表现受到了需要开源组件的关注和引入,并且也在工业界经受了广泛的考验。
[1] Ketan, & Anirban, Shah & Matani, Mitra. (2010). An O(1) algorithm for implementing the LFU cache eviction scheme.
[2] G. Karakostas and D. N. Serpanos. Exploitation of different types of locality for web caches. In Proc. of the 7th Int. Symposium on Computers and Communications (ISCC), 2002.
[3] *Gil Einziger, Roy Friedman, and Ben Manes. 2017. TinyLFU: A Highly Efficient Cache Admission Policy.* *ACM Trans. Storage* *13, 4, Article 35 (December 2017), 31 pages.*
