





作者 | 范佳
1
简介
经过社区连日开发,SeaTunnel的新Connector API已经完成初步开发,接下来就是对SeaTunnel新Connector API的适配工作。为了让开发者能够更快地开始新API的开发之旅,本文将为大家介绍新版API的开发流程。
环境配置:推荐使用JDK8和Scala2.11。
和以前一样,我们需要通过git下载最新代码到本地,并导入到IDE中,项目地址:https://github.com/apache/incubator-seatunnel 。同时切换分支到api-draft中,目前使用该分支开发新版本API和对应的Connector。项目结构如下:
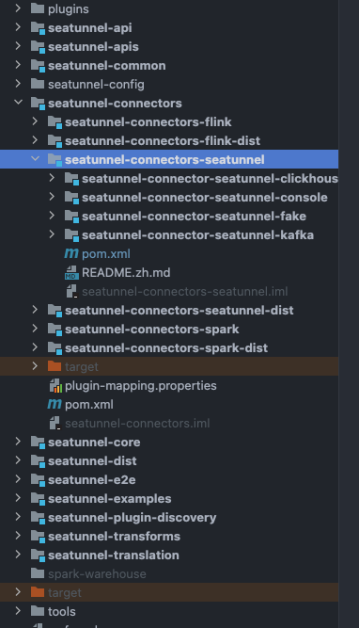
目前我们为了区别不同的Connector,将支持Flink/Spark的Connector放在seatunnel-connectors/seatunnel-connectors-flink(spark)模块下,我们的新版Connector是放在seatunnel-connectors/seatunnel-connectors-seatunnel模块下。从上图中我们可以看到,目前我们已经实现了Fake,Console,Kafka Connector,Clickhouse Connector也正在实现中。
目前我们支持的数据类型为SeaTunnelRow,所以无论Source产生的数据的类型,还是Sink消费的数据的类型,都应该是SeaTunnelRow。
以Fake Connector为例,我们来介绍如何实现一个新的Connector:
首先是创建对应的模块,路径应在seatunnel-connectors-seatunnel下,和其他新版的connector同级。
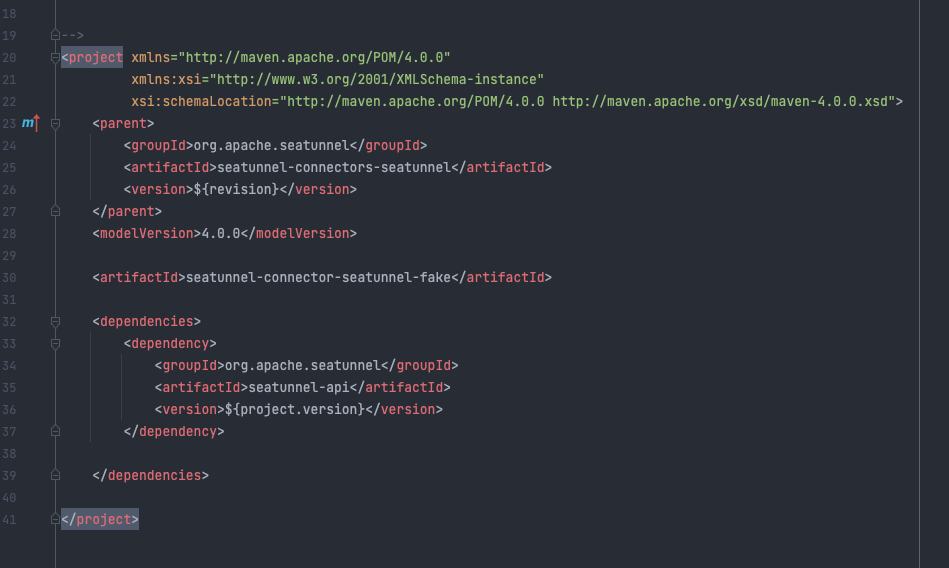
修改seatunnel-connectors-seatunnel pom.xml文件,添加新的module到modules下,修改seatunnel-connectors-seatunnel/seatunnel-connector-seatunnel-fake/pom.xml,添加seatunnel-api依赖,以及对parent的正确引用。得到的样式如下:
接下来就是创建对应的package和相关类,创建FakeSource,需要继承SeaTunnel Source。SeaTunnel的Source采用流批一体的设计,通过getBoundedness来决定当前Source是流Source还是批Source,所以可以通过动态配置的方式(参考default方法)来指定一个Source为流或批。可以通过prepare方法得到用户在配置文件中定义的配置,实现自定义化的配置。之后再创建FakeSourceReader,FakeSource SplitEnumerator,FakeSourceSplit分别继承对应的抽象类(可以在对应的类中查找到)。我们只要实现了这些类对应的方法,那么我们的SeaTunnel Source Connector就基本完成了。
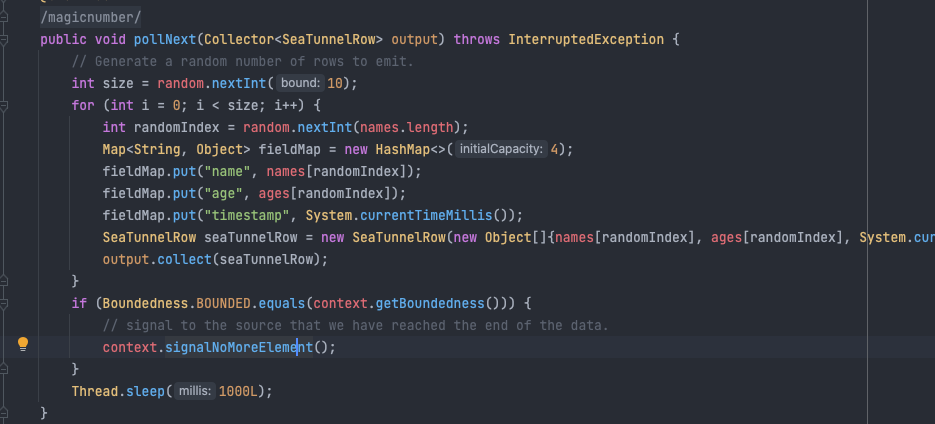
接下来仿照着现有的例子编写对应的代码就行了,其中最关键的就是FakeSource Reader,这里定义了我们如何从外部获取数据,也就是Source Connector最关键的地方,每产生一条数据,我们都需要将其放入collector中,如下所示:
代码开发完成后,我们需要配置位于seatunnel-connectors/模块下的配置文件plugin-mapping.properties。添加一条seatunnel .source.FakeSource=seatunnel-connector-fake,代表着SeaTunnel可以通过查找一个名为FakeSource的Source,找到该工程对应的jar包。这样就可以正常配置文件中使用该Connector。
关于编写Source和Sink以及SeaTunnel API的细节描述,请参考位于seatunnel-connectors/seatunnel-connectors-seatunnel/README.zh.md中的介绍。
当我们编写完Connector之后,就需要对其进行测试,我们可以在seatunnel-examples里面找到seatunnel-flink(spark)-new-connector-example模块,针对不同的引擎进行测试,目的是为了保证我们的Connector在不同的引擎中表现尽量一致,如果有差异可以在文档中标注,修改resource下的配置文件,将我们的Connector加入配置中,同时引入seatunnel-flink(spark)-new-connector-example /pom.xml的依赖,就可以执行SeaTunnelApiExample来进行测试。
默认为流处理模式,通过在配置文件的env中修改job.mode=BATCH来将执行模式切换为批模式。
Apache SeaTunnel

// 保持联络 //
微信号 : SeaTunnel
来,和社区一同成长!
Apache SeaTunnel(Incubating) 是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台。
仓库地址:
https://github.com/apache/incubator-seatunnel
网址:
https://seatunnel.apache.org/
Proposal:
https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelProposal
Apache SeaTunnel(Incubating) 2.1.0 下载地址:
https://seatunnel.apache.org/download
衷心欢迎更多人加入!
能够进入 Apache 孵化器,SeaTunnel(原 Waterdrop) 新的路程才刚刚开始,但社区的发展壮大需要更多人的加入。我们相信,在「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」(精英管理)、以及「多样性与共识决策」等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!
我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!
提交问题和建议:
https://github.com/apache/incubator-seatunnel/issues
贡献代码:
https://github.com/apache/incubator-seatunnel/pulls
订阅社区开发邮件列表 :
dev-subscribe@seatunnel.apache.org
开发邮件列表:
dev@seatunnel.apache.org
加入 Slack:
https://join.slack.com/t/apacheseatunnel/shared_invite/zt-123jmewxe-RjB_DW3M3gV~xL91pZ0oVQ
关注 Twitter:
https://twitter.com/ASFSeaTunnel
往期推荐



